3.5.1.5. Linguistic Features#
In NLP, there are some linguistic features that provide additional information:
Part-of-speed (POS)
Named Entities
Syntactic strcutures: constituency trees, dependency trees
3.5.1.5.2. NER - Named Entities Recognization#
Named Entity Recognition – Nhận diện thực thể có tên
NER là quá trình tự động phát hiện (dò tìm) và phân loại các thực thể “có tên” trong văn bản, ví dụ như tên người, tên địa điểm, tổ chức, thời gian, sự kiện, v.v.
Mục tiêu: Xác định đâu là thực thể đặc biệt trong câu và chúng thuộc loại thực thể nào.
Ví dụ câu tiếng Việt: “Ông Nguyễn Văn A làm việc tại Công ty Bkav ở Hà Nội.”
“Nguyễn Văn A” → Người (Person)
“Công ty Bkav” → Tổ chức (Organization)
“Hà Nội” → Địa điểm (Location)
Ý nghĩa
NER là một bước quan trọng trong trích xuất thông tin:
Tìm kiếm và tổng hợp thông tin: Cho phép hệ thống hiểu được đối tượng nào đang được đề cập đến (ví dụ, tìm tất cả các tin tức có nhắc đến một người/tổ chức cụ thể).
Hỏi đáp tự động (Question Answering): Giúp xác định câu trả lời chính xác khi câu hỏi hướng đến các thực thể (Ví dụ: “Ai là CEO của Google?”).
Phân tích ý kiến (Sentiment Analysis): Xem ý kiến của người dùng nhắm vào thực thể nào (nhãn hàng, địa điểm, cá nhân).
Phương pháp
Rule-based: Sử dụng luật ngôn ngữ hoặc biểu thức chính quy (regex), kết hợp danh sách các thực thể đã biết. Cách này mang tính đặc thù, thiếu linh hoạt.
Thống kê/học máy cổ điển: CRF, MaxEnt (Maximum Entropy), SVM… sử dụng đặc trưng (feature) về từ, ngữ cảnh, chữ hoa/thường, tiền tố/hậu tố, v.v.
Học sâu (Deep Learning):
Mô hình mạng nơ-ron nhiều tầng (BiLSTM + CRF) hoặc Transformers (BERT, XLM-R, PhoBERT…) huấn luyện đặc trưng tự động, thay vì thủ công.
Kết quả NER hiện nay cải thiện rất nhiều nhờ áp dụng mô hình Transformer, đặc biệt khi có dữ liệu gắn nhãn đủ lớn.
ner = [
{"token": token.text, "ner_tag": token.label_} for token in spacy_doc.ents
]
df = pd.DataFrame(ner).head()
df
| token | ner_tag | |
|---|---|---|
| 0 | Liz Truss | PERSON |
| 1 | UK | GPE |
| 2 | Rationing | PRODUCT |
| 3 | superyachts | CARDINAL |
| 4 | Russian | NORP |
from spacy import displacy
displacy.render(spacy_doc[:150], style="ent", jupyter=True)
type(spacy_doc)
spacy.tokens.doc.Doc
3.5.1.5.3. Dependency Tree#
Represent grammatical relationships between words. Read dependency relations
Applications:
Aspect-based sentiment analysis: provide syntactic information that helps determine sentiment towards relevents aspects
Textual entailment
Mối quan hệ phụ thuộc với head khi sử dụng thuộc tính .dep_

nsubj(nominal subject): Chủ ngữ danh từ của động từ “looking” là “Apple”.aux(auxiliary): Trợ động từ “is” hỗ trợ cho động từ chính “looking”.ROOT: Động từ chính của câu là “looking”.prep(prepositional modifier): Giới từ “at” bổ nghĩa cho động từ “looking”.pcomp(prepositional complement): Động từ “buying” là bổ ngữ của giới từ “at”.compound: “U.K.” là phần bổ nghĩa cho danh từ “startup”.dobj(direct object): Tân ngữ trực tiếp của động từ “buying” là “startup”.quantmod(quantifier modifier): “$” là bổ ngữ định lượng cho “billion”.pobj(object of preposition): Danh từ “billion” là tân ngữ của giới từ “for”.punct(punctuation): Dấu chấm câu.
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion.")
# Displaying the dependency parsing result for each token
for token in doc:
print(
token.text,
token.dep_,
token.head.text,
token.head.pos_,
[child for child in token.children],
)
# Visualizing the dependency parse using displaCy
# img = displacy.render(doc, style='dep', jupyter=True, distance=1)
options = {"color": "blue", "distance": 100}
img = displacy.render(doc, style="dep", jupyter=True, options=options)
Apple nsubj looking VERB []
is aux looking VERB []
looking ROOT looking VERB [Apple, is, at, .]
at prep looking VERB [buying]
buying pcomp at ADP [startup]
U.K. nsubj startup VERB []
startup ccomp buying VERB [U.K., for]
for prep startup VERB [billion]
$ quantmod billion NUM []
1 compound billion NUM []
billion pobj for ADP [$, 1]
. punct looking VERB []
3.5.1.5.4. Constituency Trees#
Constituency Trees là một phương pháp biểu diễn cấu trúc ngữ pháp của một câu dưới dạng cây phân cấp. Nó minh họa rõ ràng cách các từ trong câu kết hợp lại với nhau để tạo thành những cụm từ lớn hơn (constituents).
Giúp phân tích cấu trúc ngữ pháp rõ ràng hơn.
Thể hiện rõ mối liên hệ giữa các cụm từ và từ đơn lẻ.
Giải quyết được các trường hợp câu nhập nhằng (một câu có thể hiểu theo nhiều cách khác nhau).
A. Component
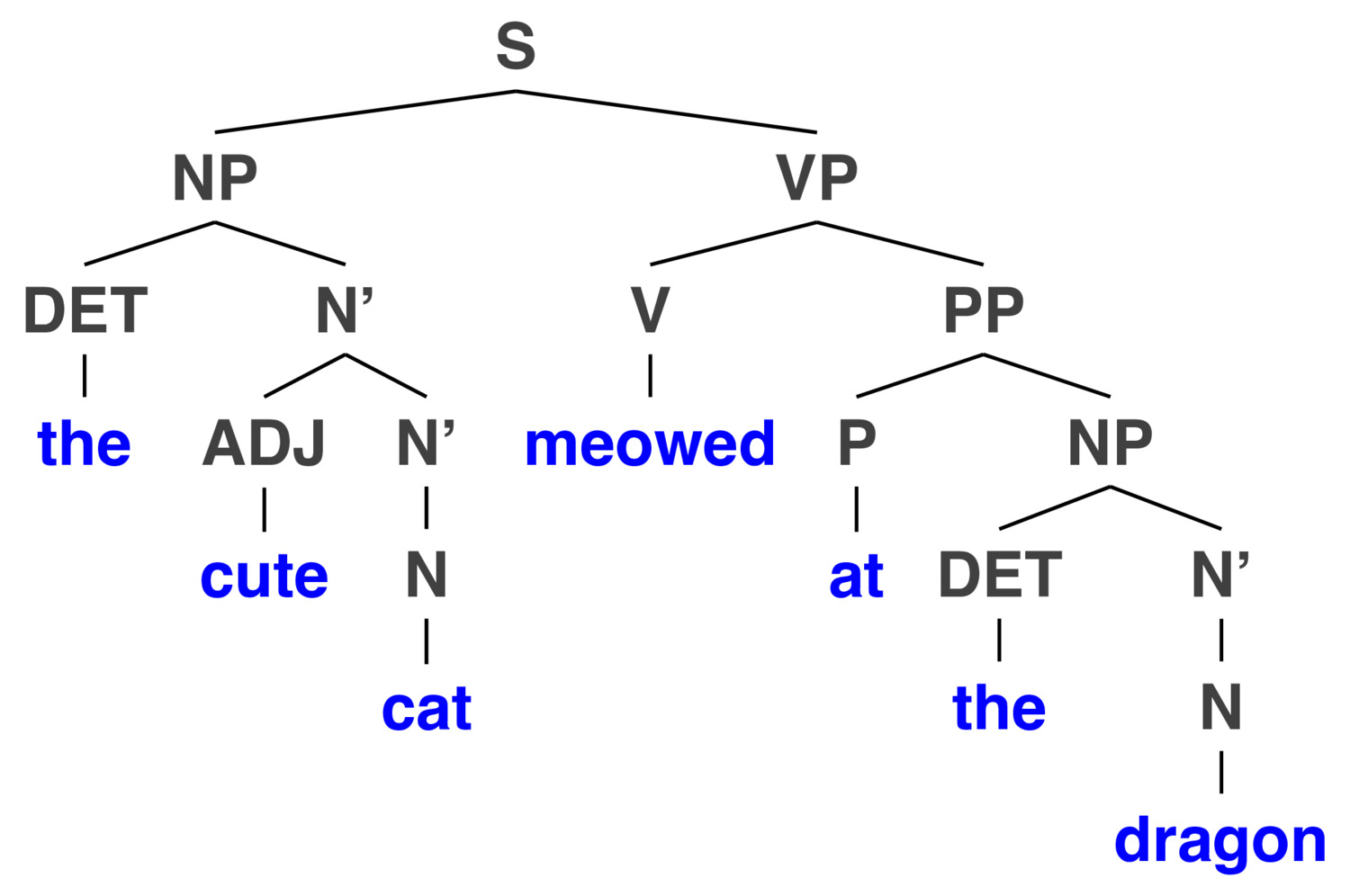
A constituent (Cụm từ) is a syntactic unit or phrase that functions as a single unit within a hierarchical structure. Là một nhóm các từ liên kết với nhau, đóng vai trò như một đơn vị thống nhất trong câu. Common types of constituents include:
Noun Phrase (NP): “the red car”Verb Phrase (VP): “is driving fast”Prepositional Phrase (PP): “on the road”
Constituency trees show sentences broken down into increasingly smaller components, typically:
Sentence (S)
Phrases (NP, VP, PP, ADJP, ADVP, etc.)
Words/Tokens (terminals)
Constituency tree are contructed using grammatical rulse like Context Free Grammar (CFG)
Nodes Trees contain two types of nodes:
Non-terminal nodes (internal nodes representing phrases or grammatical categories): là các cụm từ như NP (cụm danh từ), VP (cụm động từ), PP (cụm giới từ).
Terminal nodes (leaf nodes, typically individual words). là các từ cụ thể trong câu.
Grammatical Categories common categories used to label nodes:
S (Sentence)
NP (Noun Phrase)
VP (Verb Phrase)
PP (Prepositional Phrase)
ADJP (Adjective Phrase)
ADVP (Adverbial Phrase)
DET (Determiner)
V (Verb)
N (Noun)
P (Preposition)
Adj (Adjective), etc.
Types of Parsing:
Top-down parsing: Starts from the highest-level constituent (sentence) and recursively breaks down phrases into smaller units.
Bottom-up parsing: Starts with individual words and builds phrases up to the full sentence.
Common algorithms:
CKY algorithm (Cocke–Kasami–Younger)
Earley parsing
B. Applications in NLP
Ứng dụng trong NLP:
Parsing: Constituency trees help parsers identify sentence structure to facilitate tasks such as information extraction, machine translation, and semantic analysis.
Semantic interpretation: They guide systems to understand meaning, ambiguity, and grammatical relationships.
Grammar checking: Constituency parsing is essential for grammar-correction tools and language modeling.
Khác biệt Constituency Trees vs. Dependency Trees
Constituency trees focus on hierarchical phrase structure.
Dependency trees focus explicitly on relationships between words (head-dependent relationships), without phrase-level categories.
# Importing the Benepar parser
import benepar
# Downloading the Benepar model for English parsing
benepar.download("benepar_en3")
# Importing necessary functions from nltk
from nltk.tree import Tree
# Reloading the English language model with Benepar parser added to the pipeline
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe("benepar", config={"model": "benepar_en3"})
# Processing a new sample text for constituency parsing
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
# Extracting the first sentence from the document
sent = list(doc.sents)[0]
# Getting the constituency parse tree as a string
tree = sent._.parse_string
# Converting the string parse tree into an nltk Tree object
t = Tree.fromstring(tree)
# Pretty printing the constituency parse tree
t.pretty_print()
S
____|_____
| VP
| _____|__________
| | VP
| | __________|________________
| | | PP
| | | _____________________|_____
| | | | S
| | | | |
| | | | VP
| | | | ______________________|_______
| | | | | | PP
| | | | | | _______|___
| | | | | | | NP
| | | | | | | |
NP | | | | NP | QP
| | | | | ____|_____ | _______|_____
NNP VBZ VBG IN VBG NNP NN IN $ CD CD
| | | | | | | | | | |
Apple is looking at buying U.K. startup for $ 1 billion
3.5.1.5.5. Semantic Graph#
Semantic Graph là dạng biểu diễn kiến thức hoặc ý nghĩa của ngôn ngữ bằng đồ thị, trong đó:
Các nút (nodes): thể hiện các thực thể (entities), khái niệm (concepts), từ ngữ hoặc ý tưởng.
Các cạnh (edges): thể hiện mối liên hệ (relations) về mặt ý nghĩa giữa các nút.
Nói đơn giản, semantic graph mô tả ý nghĩa và mối quan hệ ngữ nghĩa giữa các từ, cụm từ, hoặc thực thể trong câu hoặc văn bản, thay vì chỉ thể hiện cấu trúc ngữ pháp.
Semantic graph có nhiều ứng dụng quan trọng:
Trích xuất thông tin (Information Extraction): Giúp tìm kiếm, xác định nhanh chóng các mối quan hệ giữa thực thể, sự kiện trong văn bản.
Hệ thống hỏi đáp (Question Answering): Hỗ trợ các chatbot, trợ lý ảo trả lời các câu hỏi dựa trên các mối liên hệ trong đồ thị.
Tìm kiếm ngữ nghĩa (Semantic Search): Thực hiện tìm kiếm dựa trên ý nghĩa thay vì chỉ dựa vào từ khóa đơn thuần.
Dịch máy (Machine Translation): Cải thiện độ chính xác bằng cách nắm bắt đúng ý nghĩa các câu.
Phân tích và suy luận (Reasoning): Semantic graph cho phép các hệ thống tự động suy luận, rút ra thông tin mới dựa trên các mối quan hệ đã biết.