1.1. 🎓 Lecture: 1-MLOps System Overview#
1.1.1. 📖 Tổng quan về hệ thống MLOps#
Định nghĩa về MLOps:
MLOps là một mô hình, bao gồm các cách thực thi tốt nhất (best practices), khái niệm, văn hoá làm việc, trong quá trình phát triển, triển khai và theo dõi một hệ thống ML.
MLOps gồm các kĩ thuật hội tụ bởi 3 mảng: machine learning, software engineering (đặc biệt là DevOps) và data engineering.
MLOps tạo điều kiện thuật lợi cho quá trình phát triển và triển khai các hệ thống ML ra production hiệu quả hơn, thông qua các nguyên tắc mà chúng ta sẽ xem xét ngay sau đây.
1.1.1.1. Nguyên tắc MLOps#
1. Tự động hoá trong tích hợp và triển khai (Continuous Integration/Continuous Delivery - CI/CD automation): Nguyên tắc này đảm bảo việc tích hợp và triển khai code diễn ra tự động.
2. Hợp phối quy trinh (Workflow orchestration): Trong quá trình phát triển hệ thống ML, có nhiều luồng (pipeline) cần được chạy vào những thời điểm nhất định, với các bước trong luồng phụ thuộc lẫn nhau. Ngoài ra, thư viện, môi trường chạy cũng khác nhau. Nguyên tắc này đảm bảo việc tự động hoá điều phối các bước trong một luồng chạy đúng thứ tự và thời gian được chỉ định.
3. Khả năng được tái lập lại (Reproducibility): Khả năng tái lập lại (reproduce) một kết quả hay một lần thử nghiệm là một yêu cầu thường thấy khi phát triển một hệ thống ML. Yêu cầu này đảm bảo việc chạy suy diễn mô hình (model inference) ở production ổn định và debug quá trình phát triển model hiệu quả hơn.
4. Quản lý phiên bản mã nguồn, dữ liệu và mô hình (Versioning code, data, model): Nguyên tắc này đảm bảo mã nguồn (code), dữ liệu (data) và mô hình (model) được quản lý theo các phiên bản (versions). Điều này làm thuận tiện cho việc phát triển, kiểm tra phiên bản model được huấn luyện (train) với phiên bản data nào và sử dụng code ở phiên bản nào để train.
5. Hợp tác trong phát triển (Collaboration): Trong một dự án ML, nhiều kĩ sư với chuyên môn khác nhau cùng tham gia vào phát triển hệ thống. Nguyên tắc này đảm bảo việc thiết lập một bộ các quy tắc, công cụ và văn hoá làm việc để quá trình cộng tác giữa các cá nhân, ở các vai trò, trách nhiệm khác nhau, diễn ra hiệu quả.
6. Huấn luyện và đánh giá ML liên tục (Continuous ML training & evaluation): Ở môi trường production, việc dữ liệu thay đổi liên tục khiến hiệu năng của mô hình giảm nhanh chóng. Nguyên tắc này đảm bảo việc xây dựng một luồng để huấn luyện và đánh giá mô hình một cách tự động định kì hoặc ngay khi cần thiết.
7. Theo dấu metadata trong ML (ML metadata tracking): Trong một hệ thống ML, các cấu hình hay data đầu vào/đầu ra được yêu cầu cụ thể, ở mỗi bước của một luồng. Nguyên tắc này được đặt ra nhằm theo dõi và ghi lại các đầu vào và đầu ra đó, kèm theo thông tin về những lần chạy của các luồng, ví dụ như:
Ngày, tháng, thời gian chạy
Phiên bản của data đang chạy
Hyperparameter dùng để train model
Nơi lưu trữ model sau khi train xong
v.v.
8. Theo dõi liên tục (Continuous monitoring): Nguyên tắc này đảm bảo việc theo dõi liên tục các thông số liên quan tới dữ liệu, mô hình, hạ tầng (infrastructure), để phát hiện và giải quyết các lỗi kịp thời. Một vài thông số điển hình bao gồm:
Các tính chất thống kê của data ở production
Model performance
Lượng request được gửi đến server
Thời gian xử lý một request
v.v.
9. Vòng lặp ý kiến phản hồi (Feedback loops): Khi phát triển một hệ thống ML, sự phản hồi từ phần đánh giá ngược về phần phát triển thường xuyên xảy ra, ví dụ:
Phản hồi từ quá trình thử nghiệm data và model ngược về quá trình xử lý dữ liệu thô (raw data)
Phản hồi từ quá trình đánh giá model performance ở production ngược về quá trình thử nghiệm model
v.v.
1.1.1.2. Các thành phần của MLOps (MLOps Components)#
Các thành phần trong MLOps bao gồm các cấu phần trong một hệ thống ML. Các thành phần được liệt kê như sau.
CI/CD component
Source code repository
Workflow orchestration
Feature store
Model training infrastructure
Model registry
ML metadata store
Model serving component
Monitoring component
Tên các components đã giải thích ý nghĩa và công việc của các components đó, đồng thời chúng cũng thực hiện nhiệm vụ của một hoặc nhiều principle ở phần trước, nên chúng ta sẽ không đề cập chi tiết ở đây. Để hiểu rõ hơn về mối quan hệ của các components với principles trong MLOps, bạn có thể đọc kĩ hơn ở bài báo trên.
1.1.1.3. Các workflows#
Trong phần này, chúng ta sẽ tìm hiểu về các workflows điển hình trong quá trình phát triển một hệ thống ML. Các workflows được mô tả ở bảng dưới đây.
# |
Workflow |
Mô tả |
|---|---|---|
1 |
Phân tích vấn đề |
Phân tích vấn đề kinh doanh, thiết kế hệ thống phần mềm, quyết định giải pháp về công nghệ sẽ dùng, định nghĩa vấn đề ML cần giải quyết, tìm kiếm data có thể sử dụng, thu thập data và phân tích data |
2 |
Định nghĩa quy luật biến đổi data |
Định nghĩa các quy luật để biến đổi data thành dạng có thể sử dụng được để thử nghiệm |
3 |
Xây dựng data pipeline |
Quy luật biến đổi data sẽ được sử dụng để xây dựng data pipeline |
4 |
Thử nghiệm model |
Thử nghiệm data và model, train model tốt nhất |
5 |
Tự động hoá ML pipeline |
Code từ quá trình thử nghiệm data và model sẽ được tự động vào ML pipeline. Model sau khi train xong sẽ được triển khai tự động lên Model serving component và tích hợp với Monitoring component |
Các workflows trên không phải là thứ tự chính xác về các công việc khi xây dựng một hệ thống ML. Hình dưới đây là một ví dụ về thứ tự trong thực tế.
Đầu tiên, chúng ta cần định nghĩa và phân tích vấn đề kinh doanh để hiểu rõ yêu cầu về các chức năng của hệ thống ML. Sau đó, dự án Proof Of Concept (POC) sẽ được thực hiện để chứng minh rằng giải pháp đề ra là khả thi, trước khi bắt tay vào xây dựng chi tiết các chức năng phức tạp.
Có thể có nhiều dự án POC ở các mức độ khác nhau. Trong quá trình thực hiện dự án POC, các data engineer, software engineer, ML engineer hay MLOps engineer cũng thực hiện song song việc xây dựng data pipeline, training pipeline, model serving component, monitoring component và CI/CD cho tất cả pipeline, components đó. Dựa trên các bước xây dựng một hệ thống ML trong thực tế, khoá học này sẽ bao gồm các bài học lần lượt như sau:
Phân tích vấn đề
POC
Data pipeline
Training pipeline
Model serving
Monitoring
CI/CD
1.1.1.4. Phân tích bài toán/vấn đề kinh doanh#
? Khi một khách hàng hỏi về sản phẩm phù hợp với trading persona của họ, nhiệm vụ là phải đưa ra câu trả lời.
Chủ đề |
Câu hỏi |
Trả lời |
|---|---|---|
Mục tiêu |
Mục tiêu kinh doanh? |
Tăng số lượng giao dịch của khách hàng trong 1 tháng 10% |
Các chức năng chính? |
Chọn mã cố phiếu có khả năng cao nhất phù hợp với khách hàng |
|
Các bên liên quan |
Ai là người tham gia? Vai trò và trách nhiệm? |
Product owner, Product manager, Solution Architect, Data Scientist, Data engineer, ML engineer |
Ai cần được thông báo về dự án? |
Head of Engineering, CTO, CEO |
|
Ai là người dùng cuối? |
Khách hàng |
|
Data |
Có thể lấy ở các nguồn nào? |
Static data và streaming data từ ứng dụng trading của công ty |
Định nghĩa quy trình để biến đổi data sang format có thể dùng được? |
Giả sử quy trình để biến đổi data, feature engineering đã được định nghĩa |
|
Phát triển model |
Có giải pháp nào đã được thực hiện để đối chiếu? |
Giả sử đã tìm hiểu các giải pháp của đối thủ cạnh tranh |
Có những thresholds nào được dùng để khiến giải pháp trở nên hữu ích? |
Model inference không được chạy quá 500ms |
|
Cân nhắc tradeoffs |
False positives (false alarm) có ảnh hưởng nghiêm trọng hơn |
|
Có cần confidence score không? Dùng threshold nào? |
Không cần, rank các mã cố phiếu theo xác suất mà model dự đoán sau |
|
Làm gì với các dự đoán không được chọn? |
Được log lại và gán label |
|
Đánh giá model |
Dùng metrics nào để đánh giá model lúc phát triển và ở production? |
Dùng metrics Root Mean Square Error (RMSE) |
Làm sao để liên kết model performance với mục tiêu kinh doanh? |
Ở production, ngoài RMSE để đánh giá model performance, cần tính tỉ lệ hoàn thành mã giao dịch trong 1 tháng gần nhất |
|
Triển khai |
Data của quá trình inference sẽ được lấy từ đâu? Được format và lưu trữ thế nào? |
Data đầu vào của quá trình inference được lấy từ Online Feature Store (sẽ được giải thích trong bài Model serving) |
Model được triển khai ở đâu? |
Lên server nội bộ của công ty |
|
Khi nào chạy batch prediction? Khi nào chạy online prediction? |
Chạy batch prediction mỗi giờ cho các cổ phiếu ít hoạt động, data ít thay đổi. Chạy online prediction cho các cổ phiếu phổ biến nhiều |
|
Tốc độ thay đổi của data thế nào? |
Vài features sẽ thay đổi không thường xuyên, đặt lịch để cập nhật hàng ngày. Vài features cần lấy từ streaming data, cần data pipeline riêng để xử lý và lưu trữ |
|
Bao lâu thì cần train lại model? |
Dựa vào tốc độ thay đổi của data hoặc chất lượng data ở production |
|
Labels ở production được thu thập như thế nào? |
Sau khi mã cổ phiếu được gợi ý, ứng dụng giao dịch sẽ trả về kết quả xem lệnh giao dịch có hoàn thành không |
|
Quyền riêng tư |
Có yêu cầu nào về quyền riêng tư của data, labels, v.v |
Data và labels chỉ được dùng trong nội bộ công ty |
Hệ thống có thể được kết nối với internet không? |
Có |
|
Có thể giữ data của users trong bao lâu? |
Không giới hạn |
|
Chi phí và lợi ích |
Ngân sách ban đầu |
$500,000 |
So sánh chi phí và lợi ích |
Lợi ích lớn hơn chi phí nhiều, hệ thống có thể tái sử dụng, chi phí để optimize không lớn |
|
Cần đạt yêu cầu nào để tăng kinh phí? |
Hoàn thành các mốc thời gian tiếp theo, triển khai model ra production và tiếp tục chứng minh lợi ích lớn hơn nhiều chi phí |
|
Rủi ro |
Phân tích rủi ro đi kèm |
Có thể model được đánh giá offline là tốt, nhưng ở production không mang lại hiệu quả cao |
Phân tích rủi ro kinh doanh khác |
Hết tiền trước khi hoàn thiện POC |
|
Ràng buộc kĩ thuật |
Có hệ thống cũ nào cần tích hợp với không? |
Không |
Architecture và tools sẽ dùng? |
Được định nghĩa ở bài tiếp theo |
|
Bước đầu tiên của một dự án phần mềm, đó chính là thu thập các yêu cầu, phân tích vấn đề kinh doanh. Quá trình này giúp hiểu rõ và sâu hơn về vấn đề đang gặp phải, về những giải pháp tiềm năng, đồng thời lên kế hoạch để triển khai chúng. |
1.1.2. Hệ thống ML#
1.1.2.1. Thành phần và công cụ#
MLOps platform là nền tảng cung cấp các công cụ cần thiết để phát triển, quản lý và triển khai các dự án ML. Trong một số tài liệu khác MLOps platform còn có tên là AI platform hoặc ML platform. Ở khóa học này chúng ta sẽ sử dụng một MLOps platform với các thành phần và công cụ tương ứng như sau:
Tên thành phần |
Ý nghĩa |
Tool sử dụng |
|---|---|---|
Source control |
Quản lý các phiên bản về mã nguồn và dữ liệu |
Git & Github |
Feature store |
Lưu trữ, quản lý và tương tác với các tính năng (feature) |
Feast (PostgreSQL & Redis backend) |
Experiment tracking |
Lưu trữ thông tin và quản lý các thí nghiệm (experiments) |
MLFlow |
Model registry |
Lưu trữ và quản lý các mô hình |
MLFlow |
ML metadata Store |
Lưu trữ thông tin (artifact) của các luồng (pipeline) |
MLFlow |
Workflow orchestrator |
Xây dựng và quản lý các luồng quy trình |
Airflow |
Monitoring |
Theo dõi tài nguyên hệ thống, hiệu năng của mô hình và chất lượng dữ liệu trên production |
Prometheus & Grafana & ELK |
CI/CD |
Tự động hóa quá trình test và deploy |
Jenkins |
Info
Chúng ta có thể sử dụng một công cụ cho nhiều mục đích khác nhau, ví dụ MLFlow, với mục đích sử dụng tối thiểu các công cụ cần thiết mà vẫn đảm bảo được 9 MLOps Principles, 9 MLOps Components và 5 MLOps Workflows được áp dụng (xem lại bài Tổng quan MLOps). Việc sử dụng quá nhiều công cụ có thể dẫn tới việc vận hành MLOps platform trở nên phức tạp, đồng thời khiến người dùng dễ bị choáng ngợp do không biết sử dụng và quản lý một cách hiệu quả.
1.1.2.2. Architecture#
Kiến trúc MLOps platform của chúng ta sẽ như sau:
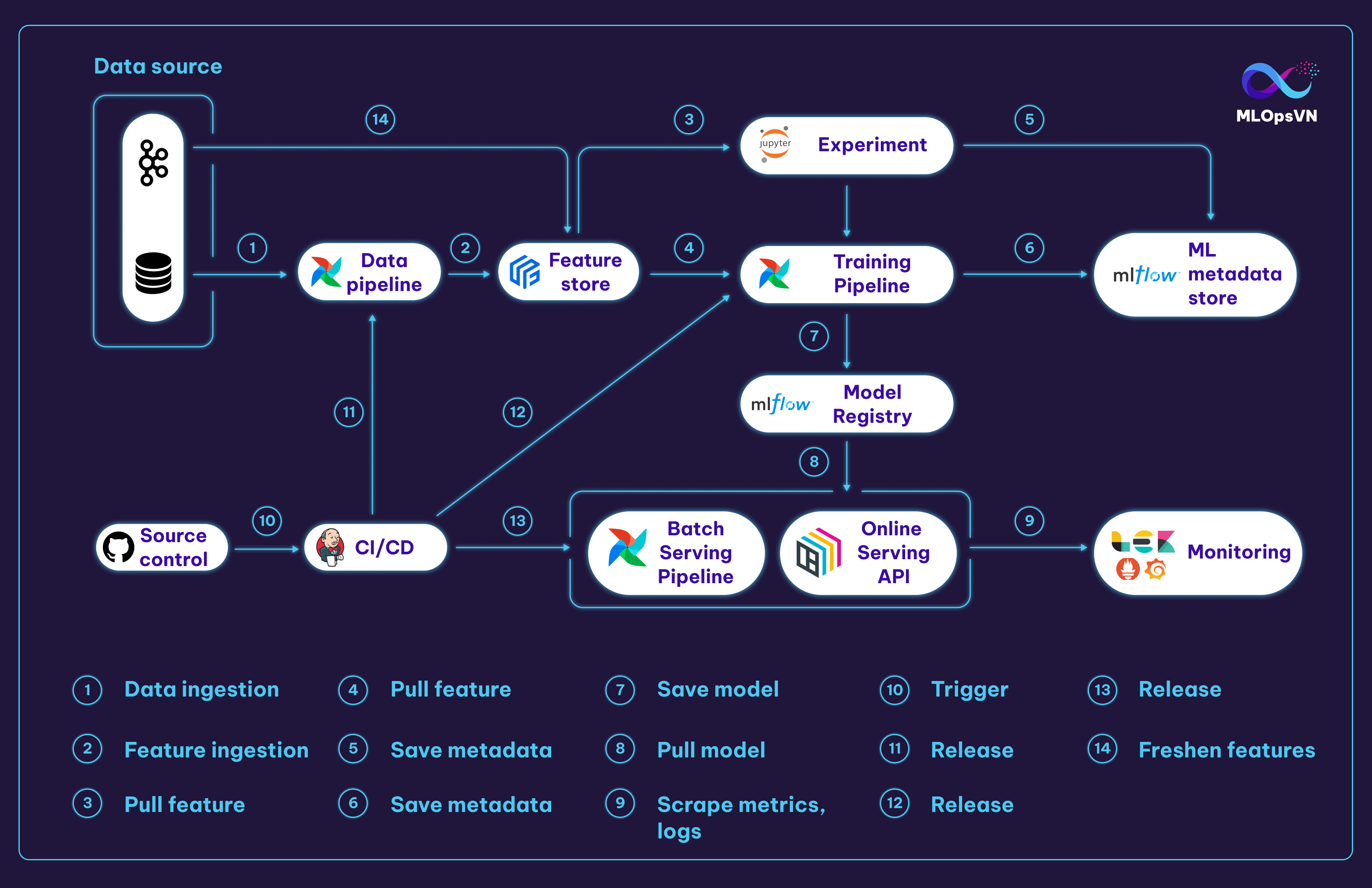
Các tương tác chính trong MLOps platform:
1. Data Pipeline kéo và xử lý dữ liệu từ file source
2. Dữ liệu sau khi xử lý bởi Data Pipeline sẽ được đẩy vào Feature Store
3. Data Scientist (DS) kéo feature từ Feature Store để thực hiện các thí nghiệm trên notebook
4. Training Pipeline kéo feature về để train model
5. Metadata của các experiment, ví dụ như hyperparameters và metrics,… được lưu vào Metadata Store
6. Metadata của Training Pipeline cũng được lưu vào Metadata Store
7. Model sau khi train sẽ được lưu trữ ở Model Registry
8. Batch Serving Pipeline và Online Serving API kéo model từ Model Registry về để serve
9. Logs và metrics được scrape từ Online Serving API
10. 11. 12. 13. DS push code lên Github kích hoạt triển khai tự động (CI/CD) cho các pipelines và Online Serving API
14. Ngoài data source ở dạng tĩnh (static data), streaming data từ Kafka sẽ ghi liên tục vào Feature Store để cập nhật feature
Các tương tác và các công cụ được nhắc đến ở trên sẽ được hướng dẫn cụ thể xuyên suốt cả khoá học.
1.1.2.3. Sử dụng platform#
1.1.2.3.1. Start#
Để start các services trong MLOps platform, bạn làm theo các bước sau.
Clone code mlops-crash-course-platform tại đây
Cài Docker theo hướng dẫn tại đây
Cài Docker Compose version v2.10.2 theo hướng dẫn tại đây Warning Series bài giảng này sử dụng docker-compose v2.10.2 với command
docker-compose(thay vì compose plugin của Docker với commanddocker compose). Sử dụng version khác v2.10.2 có thể gây ra nhiều lỗi không mong muốn.Start services
Cách 1: Start tất cả services một lúc (nếu máy bạn có cấu hình mạnh):
cd mlops-crash-course-platform bash run.sh all up # Mỗi bài học tiếp theo sẽ hướng dẫn cách start các service liên quan đến bài học đó. Do vậy, bạn không cần phải start tất cả các services cùng một lúc.
Cách 2: Start từng nhóm service một:
cd mlops-crash-course-platform bash run.sh feast up # Start các service liên quan đến feast
(BUG) Khi start các service, nếu bạn gặp lỗi
port is already allocatedtương tự như sau:Error response from daemon: driver failed programming external connectivity on endpoint mlflow-mlflow-1 (2383a7be19ea5d2449033194211cabbd7ad13902d8d4c2dd215a63ab78038283): Bind for 0.0.0.0:5000 failed: port is already allocated
có nghĩa là đang có một service khác chạy ở port
5000vàmlflowkhông thể sử dụng port đó nữa, khi đó bạn sẽ thay bằng port khác như bên dưới đây. Bạn sẽ xử lý tương tự với các service khác. Thay bằng"another_port:5000", ví dụ”"5001:5000". Khi đó, sau khi start servicemlflowbạn sẽ truy cập service này tạihttp://localhost:5001.
1.1.2.3.2. Stop#
Để stop các services trong MLOps platform, bạn làm theo các cách sau.
Cách 1: Stop tất cả service mà không làm mất docker volumes liên quan
cd mlops-crash-course-platform bash run.sh all down
Cách 2: Stop một nhóm service mà không làm mất docker volumes liên quan
cd mlops-crash-course-platform bash run.sh feast down
Cách 3: Stop service và docker volumes liên quan tới service
cd mlops-crash-course-platform bash run.sh feast down --volumes # Stop service `feast` và docker volumes liên quan tới service này bash run.sh all down --volumes # Stop tất cả services và docker volumes liên quan
Sử dụng cách 3 sẽ không xoá data nằm trong các local folders mà được mount với các docker containers của các services. Để xoá hoàn toàn data liên quan tới services, bạn cần xoá các local folders này thủ công. Các bạn làm các bước sau:
Trong repo
mlops-crash-course-platform, mở folder tương ứng với service bạn muốn xoá data, ví dụ folderairflowXoá toàn bộ folders/files trong folder
airflow/run_env, trừ file.gitkeep
1.1.2.3.3. Restart#
Để restart các services trong MLOps platform, bạn làm như dưới đây.
cd mlops-crash-course-platform
bash run.sh feast restart # Restart service `feast`
bash run.sh all restart # Restart tất cả services
1.1.2.4. Cấu trúc code#
Để tiện cho việc code đồng thời quản lý các service trong MLOps platform thì bạn đặt repo mlops-crash-course-platform và mlops-crash-course-code trong cùng 1 folder như sau:
mlops-crash-course
├── mlops-crash-course-platform/ # chứa docker-compose files để triển khai MLOps platform
└── mlops-crash-course-code/ # chứa code của dự án ML mà chúng ta sẽ phát triển và sử dụng MLOps platform
Warning: Trong mỗi module ở mlops-crash-course-code/ ví dụ như: data_pipeline và model_serving sẽ đều có 1 file là dev_requirements.txt. Bạn hãy tạo một môi trường mới tương tự như bên dưới trước khi cài đặt các thư viện để tránh xung đột thư viện với các dự án khác:
conda create -n myenv python=3.9
conda activate myenv
cd data_pipeline
pip install -r dev_requirements.txt
1.1.2.5. Infra layer#
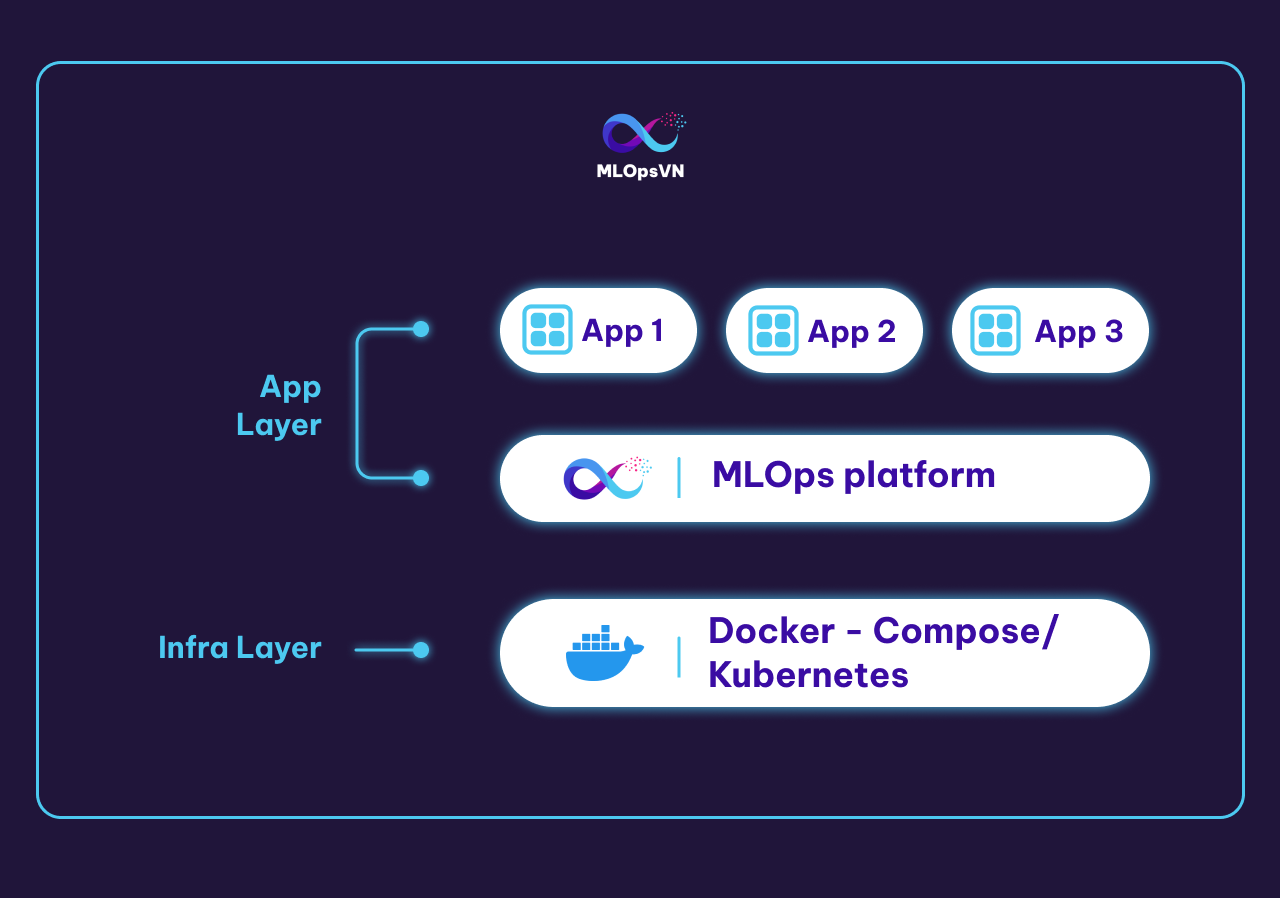
Phần này cung cấp cho bạn một cái nhìn tổng quan hơn nữa về MLOps platform khi được đặt trong cơ sở hạ tầng IT của một tổ chức.
Thông thường, một tổ chức sẽ có một nhóm các kỹ sư hạ tầng (Infra engineer) làm nhiệm vụ xây dựng Infra layer. Chức năng chính của Infra layer là quản lý, cung cấp tài nguyên tính toán, lưu trữ cho các ứng dụng ở các layer trên nó. Infra layer có thể được xây dựng đơn giản sử dụng docker-compose, Docker Swarm hoặc phức tạp hơn như Kubernetes. Trong khoá học này, giả sử rằng chúng ta sử dụng docker-compose ở Infra layer để quản lý các containers và cung cấp tài nguyên tính toán, lưu trữ cho các service.
Trên Infra layer là Application layer hay chính là nơi mà các engineer khác xây dựng các ứng dụng cho chính tổ chức đó. Các ứng dụng này có thể là môi trường Jupyter notebook, Gitlab server, Jenkins server, monitoring platform, v.v. MLOps platform mà chúng ta đang xây dựng cũng nằm trên Application layer này.
1.1.3. POC#
Dự án POC thử nghiệm các giải pháp nhanh chóng để chứng minh được tồn tại ít nhất một giải pháp giải quyết được vấn đề kinh doanh, trước khi bắt tay vào xây dựng các tính năng phức tạp khác. Vì ML được chọn làm giải pháp, nên việc cần làm đó là chứng minh rằng giải pháp ML là khả thi, bằng cách sử dụng MLOps platform đã được định nghĩa ở bài MLOps Platform.
1.1.3.1. Môi trường phát triển#
Các thư viện bạn cần cài đặt cho môi trường phát triển được đặt tại training_pipeline/dev_requirements.txt. Bạn có thể dùng virtualenv, conda, hoặc bất kì công cụ nào để cài đặt. Phiên bản Python được sử dụng trong cả khoá học là 3.9.
Các MLOps tools được dùng trong bài này bao gồm:
Jupyter notebook: thử nghiệm data, model
MLflow: ML Metadata Store, Model Registry
1.1.3.2. Định nghĩa POC#
Trong quá trình phân tích vấn đề kinh doanh, thông tin về data và quá trình xây dựng ML model đã được tổng hợp như sau.
# |
Câu hỏi |
Trả lời |
|---|---|---|
1 |
Data được lấy từ đâu? |
Được tổng hợp bởi Data Engineer từ ứng dụng của công ty |
2 |
Data sẽ được biến đổi và lưu trữ thế nào? |
Được Data Engineer xử lý để thực hiện POC trước, format là |
3 |
Feature tiềm năng? |
|
4 |
Model architecture tiềm năng? |
Elastic Net |
5 |
Dùng metrics nào để đánh giá model? |
MSE, RMSE, R2 |
Khi định nghĩa dự án POC, chúng ta cần trả lời một câu hỏi quan trọng:
Thế nào là một dự án POC thành công?
Ở những dự án POC đầu tiên, ML model chưa được triển khai ra production mà chỉ được thử nghiệm offline. Do đó, chúng ta cần sử dụng các offline metrics để đánh giá. Cụ thể, cần đặt một threshold cho các metrics này. Ví dụ, sử dụng metric RMSE với một hạn mức (threshold) để định nghĩa dự án POC thành công là RMSE phải nhỏ hơn 0.5.
Ngoài RMSE cho bài toán logistic regression ra, một số metric khác cũng được sử dụng như:
Sử dụng Accuracy, F1, AUC để đánh giá model performance cho bài toán classification
Sử dụng thời gian training và inference của ML model để so sánh chi phí và lợi ích
v.v.
1.1.3.3. Thu thập data#
Ở dự án POC đầu tiên, do data pipeline chưa được hoàn thiện, nên data dùng để thử nghiệm được Data Engineer thu thập từ data sources, rồi chuyển giao data thô này cho Data Scientist (DS). DS sẽ thực hiện các công việc sau:
Phân tích data để định nghĩa các cách biến đổi cho data. Các cách biến đổi này được dùng để xây dựng data pipeline
Phân tích data, thử nghiệm và định nghĩa các cách biến đổi feature engineering cho data. Các cách biến đổi feature engineering này được dùng để xây dựng data pipeline
Thử nghiệm các model architecture và hyperparameter. Cách train model được dùng để xây dựng training pipeline
1.1.3.4. Phân tích data#
Trong phần này, Jupyter Notebook được dùng để viết code phân tích data và training code. Giả sử Data Engineering đã thu thập data từ data sources và chuyển giao cho chúng ta 2 file data:
training_pipeline/nbs/data/exp_driver_stats.parquet: chứa data của các tài xế, được ghi lại ở nhiều thời điểmtraining_pipeline/nbs/data/exp_driver_orders.csv: chứa thông tin về cuốc xe có hoàn thành hay không của các tài xế ở nhiều thời điểm
Hai file này chứa các cột chính với ý nghĩa tương ứng như sau:
File |
Cột |
Ý nghĩa |
|---|---|---|
exp_driver_stats.parquet |
datetime |
Thời gian record được ghi lại |
driver_id |
ID của tài xế |
|
conv_rate |
Một thông số nào đó |
|
acc_rate |
Một thông số nào đó |
|
avg_daily_trips |
Một thông số nào đó |
|
exp_driver_orders.csv |
event_timestamp |
Thời gian record được ghi lại |
driver_id |
ID của tài xế |
|
trip_completed |
Cuốc xe có hoàn thành không |
Source code được đặt tại training_pipeline/nbs/poc-training-code.ipynb.
training_pipeline/nbs/poc-training-code.ipynbDATA_DIR = Path("./data") #
DATA_PATH = DATA_DIR / "exp_driver_stats.parquet"
LABEL_PATH = DATA_DIR / "exp_driver_orders.csv"
df_orig = pd.read_parquet(DATA_PATH, engine='fastparquet') #
label_orig = pd.read_csv(LABEL_PATH, sep="\t")
label_orig["event_timestamp"] = pd.to_datetime(label_orig["event_timestamp"]) #
target_col = "trip_completed" #
Tiếp theo, Data Scientist sẽ phân tích data để hiểu data. Quá trình này thường kiểm tra những thứ sau.
Có feature nào chứa
nullkhông? Nên thaynullbằng giá trị nào?Có feature nào có data không thống nhất không? Ví dụ: khác đơn vị (km/h, m/s), v.v
Có feature hay label nào bị bias không? Nếu có thì do quá trình sampling hay do data quá cũ? Giải quyết thế nào?
Các feature có tương quan không? Nếu có thì có cần loại bỏ feature nào không?
Data có outlier nào không? Nếu có thì có nên xoá bỏ không?
v.v
Mỗi một vấn đề về data trên sẽ có một hoặc nhiều cách giải quyết. Tuy nhiên, chúng ta sẽ không biết được ngay các cách giải quyết có hiệu quả hay không. Do vậy, quá trình kiểm tra và phân tích data này thường sẽ đi kèm với các thử nghiệm đánh giá model. Các metrics khi đánh giá model giúp đánh giá xem các giải pháp được thực hiện trên data có hiệu quả không. Vì tiến trình thường gặp của Machine Learning là thử nghiệm với data, model nên bước phân tích data này và bước training model như một vòng lặp được thực hiện lặp lại nhiều lần.
Vì các file data của chúng ta không có feature nào chứa null và để tập trung vào MLOps, chúng ta sẽ tối giản hoá bước phân tích data này và đi vào viết code train model.
1.1.3.5. Chuẩn bị data#
Photo by Luke Chesser on Unsplash
Đầu tiên, features được tổng hợp từ DataFrame df_orig với labels từ DataFrame label_orig. Cụ thể, với mỗi record trong label_orig, chúng ta muốn lấy ra record mới nhất tương ứng trong df_orig với driver_id giống nhau. Record mới nhất tương ứng nghĩa là thời gian ở cột datetime trong df_orig sẽ xảy ra trước và gần nhất với thời gian ở cột event_timestamp trong label_orig. Ví dụ:
df_origchứa 2 records như sau
index |
datetime |
driver_id |
conv_rate |
acc_rate |
avg_daily_trips |
|---|---|---|---|---|---|
1 |
2022-12-01 |
1001 |
0.1 |
0.1 |
100 |
2 |
2022-11-01 |
1001 |
0.2 |
0.2 |
200 |
3 |
2022-10-01 |
1001 |
0.3 |
0.3 |
300 |
4 |
2022-09-01 |
1001 |
0.4 |
0.4 |
400 |
label_origchứa 2 records như sau
index |
event_timestamp |
driver_id |
trip_completed |
|---|---|---|---|
1 |
2022-12-15 |
1001 |
1 |
2 |
2022-09-15 |
1001 |
0 |
Data mà chúng ta muốn tổng hợp gồm 2 records như sau
index |
event_timestamp |
driver_id |
trip_completed |
conv_rate |
acc_rate |
avg_daily_trips |
|---|---|---|---|---|---|---|
1 |
2022-12-15 |
1001 |
1 |
0.1 |
0.1 |
100 |
2 |
2022-09-15 |
1001 |
0 |
0.4 |
0.4 |
400 |
Giải thích
Features từ
index 1ởdf_origđược lấy ra cho recordindex 1ởlabel_orig, vì feature đó là mới nhất (2022-12-01) so vớievent_timestampcủa record ởindex 1(2022-12-15) tronglabel_origTương tự, features từ
index 4ởdf_origđược lấy ra cho recordindex 2ởlabel_orig, vì feature đó là mới nhất và xảy ra trước (2022-09-01) so vớievent_timestampcủa record ởindex 2(2022-09-15) tronglabel_orig
Code để tổng hợp features và labels như dưới đây.
Nhóm features vào các nhóm theo
driver_idHàm xử lý mỗi hàng trong
label_origLấy ra các hàng trong
df_origcủa một tài xếLấy ra các hàng trong
df_origcódatetime<=event_timestampcủa hàng hiện tại tronglabel_origSắp xếp các hàng theo cột
datetimeLấy ra hàng ở thời gian mới nhất
Thêm các cột cần thiết vào
Biến thành
Series(một hàng) và returnLoại bỏ các cột không cần thiết
1.1.3.6. Training code#
Sau khi tổng hợp features và labels vào data_df, DataFrame này được chia thành training set và test set. Các bước train model và đánh giá model được thực hiện như dưới đây.
training_pipeline/nbs/poc-training-code.ipynbselected_ft = ["conv_rate", "acc_rate", "avg_daily_trips"] # (1)
TARGET_COL = "trip_completed"
TEST_SIZE = 0.2
train, test = train_test_split(data_df, test_size=TEST_SIZE, random_state=random_seed) # (2)
train_x = train.drop([TARGET_COL], axis=1)[selected_ft]
test_x = test.drop([TARGET_COL], axis=1)[selected_ft]
train_y = train[[TARGET_COL]]
test_y = test[[TARGET_COL]]
ALPHA = 0.5
L1_RATIO = 0.1
model = ElasticNet(alpha=ALPHA, l1_ratio=L1_RATIO, random_state=random_seed) # (3)
model.fit(train_x, train_y)
predicted_qualities = model.predict(test_x) # (4)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
Chọn các features để train
Tạo training set và test set
Train model
Đánh giá model
Chúng ta cần thử nghiệm rất nhiều bộ feature, nhiều model architecture với các bộ hyperparameter khác nhau. Để có thể tái lập kết quả training, cần phải biết được thử nghiệm nào dùng bộ feature nào, model architecture, với các hyperparameter nào. Trong khoá học này, chúng ta sẽ sử dụng MLOps Platform đã được giới thiệu trong bài MLOps Platform và cụ thể là MLflow sẽ đóng vai trò chính giúp chúng ta theo dõi các thông tin trên hay ML metadata của các lần thử nghiệm.
1.1.3.7. Theo dõi thử nghiệm#
MLflow là một open-source platform để quản lý vòng đời và các quy trình trong một hệ thống ML. Một trong những chức năng của MLflow mà chúng ta sử dụng đó là chức năng theo dõi ML metadata. Code của phần này được đặt tại notebook training_pipeline/nbs/poc-integrate-mlflow.ipynb. Logic của code giống như notebook training_pipeline/nbs/poc-training-code.ipynb, chỉ có thêm đoạn code để tích hợp MLflow vào. Bạn hãy làm theo các bước sau để tích hợp MLflow.
Clone github repo mlops-crash-course-platform, chạy MLflow server trên môi trường local
bash run.sh mlflow up
Đi tới URL http://localhost:5000 để kiểm tra xem MLflow server đã được khởi tạo thành công chưa
Trong notebook
training_pipeline/nbs/poc-integrate-mlflow.ipynb, các bạn để ý đoạn code sau được thêm vào ở đoạn code training để tích hợp MLflow vào đoạn code trainingVì
sklearnđược dùng để train model, dòng này tự động quá trình log lại các hyperparameter và các metrics trong quá trình training. Xem thêm ở đây để biết thêm thông tin về các training framework được MLflow hỗ trợ tự động log ML metadata.
Đoạn code sau để log lại các hyperparameter và metric
Đặt tên cho lần chạy
Log lại feature được dùng
Log lại hyperparameter
Log lại metric sau khi test trên test set
Log lại model
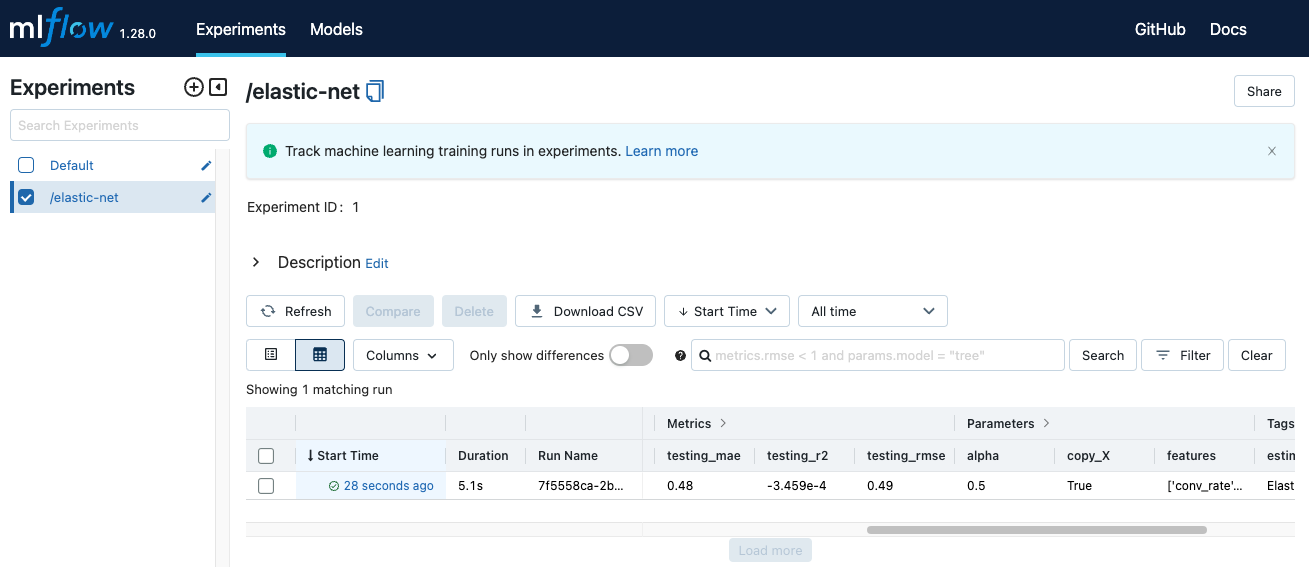
Mở MLflow trên browser, bạn sẽ thấy giao diện như sau.
 Mọi thông tin chúng ta log lại mỗi lần thử nghiệm đã được lưu lại. Bạn có thể xem thêm thông tin chi tiết về một lần chạy bằng cách ấn vào cột
Mọi thông tin chúng ta log lại mỗi lần thử nghiệm đã được lưu lại. Bạn có thể xem thêm thông tin chi tiết về một lần chạy bằng cách ấn vào cột Start timecủa lần chạy đó.
1.1.3.8. Theo dõi features#
Trong phần trước, chúng ta đã coi bộ feature mà chúng ta sử dụng trong quá trình training như một hyperparameter và dùng MLflow để log lại. Tuy nhiên, đây chưa phải giải pháp tối ưu để theo dõi các feature trong quá trình thử nghiệm.
Mục đích của việc theo dõi các feature là để có thể tái lập kết quả của một thử nghiệm. Chỉ bằng việc lưu lại tên các feature được dùng thì không đảm bảo được sẽ tạo lại được kết quả, vì có thể feature bị đổi tên hoặc tên vẫn giữ nguyên nhưng cách biến đổi để sinh ra feature đó bị thay đổi. Do đó, việc theo dõi các feature này không chỉ là theo dõi tên của các feature, mà cả quy trình sinh ra các feature đó.
Ở giai đoạn POC, vì chưa có đủ nguồn lực để xây dựng cơ sở hạ tầng đủ mạnh để hỗ trợ việc theo dõi quy trình tạo ra feature, nên chúng ta chỉ kì vọng sẽ theo dõi được tên các feature là đủ. Trong các bài tiếp theo, chúng ta sẽ học cách theo dõi version của quy trình biến đổi feature và tích hợp version đó vào quá trình training.
1.1.3.9. Tổng kết POC#
Qua nhiều lần thử nghiệm data và model, ngoài việc chứng minh giải pháp ML là khả thi, chúng ta sẽ hiểu rõ hơn về vấn đề kinh doanh, giải pháp tiềm năng, cách đánh giá các giải pháp đó một cách hiệu quả. Các đầu ra này sẽ được dùng để cập nhật lại các định nghĩa của vấn đề kinh doanh, các cách biến đổi data để xây dựng data pipeline, training code để xây dựng training pipeline và serving code để xây dựng model serving component.