3.6.1. Transformer#
3.6.1.1. Language models#
Trong không gian vocab, models sẽ cho output xác suất phân phối của words trong mỗi context nhất định, từ đó xác định được the next generated text.
The learning process typically involves predicting the next token in a sequence using either classical statistical method or novel deep learning techniques.
Read more Intro-llms
Seq2Seq: Là mô hình chuỗi có thứ tự về mặt thời gian/tuần tự
Các model đời đầu như RNN theo lớp model Seq2Seq, nhưng có nhiều yếu điểm về việc low-performance và không capture để tốt về context, dễ bị mất ý meaning của những sequence đã xuất hiện trước đó khá xa
Model LSTM đã phần nào giải quyết được vấn đề bộ nhớ context, nhưng chi phí tính toán và hiệu suất quá chậm do cần nhiều bộ nhớ để lưu trữ thông tin và vẫn phải xử lý tuần tự
Các hạn chế của RNN, LSTM và GRU bao gồm:
Vấn đề về phụ thuộc dài hạn: Mặc dù LSTM và GRU được thiết kế để giải quyết vấn đề biến mất gradient trong RNN truyền thống, chúng vẫn gặp khó khăn khi học các phụ thuộc dài hạn trong văn bản. Điều này là do bản chất tuần tự của chúng, khiến việc lưu giữ thông tin qua một chuỗi dài trở nên khó khăn.
Khó khăn trong việc song song hóa: Các mô hình RNN, bao gồm LSTM và GRU, phải xử lý dữ liệu theo trình tự từng bước một thời điểm. Điều này hạn chế khả năng song song hóa quá trình huấn luyện, làm tăng thời gian cần thiết để huấn luyện mô hình trên các chuỗi dài và các tập dữ liệu lớn.
Hiệu suất xử lý không hiệu quả: Việc xử lý tuần tự khiến RNN không thể tận dụng hiệu quả các GPU và TPU hiện đại, những thiết bị được thiết kế để xử lý đồng thời nhiều tác vụ. Điều này dẫn đến một hiệu suất xử lý không tối ưu.
Cơ chế Attention hiểu một cách đơn giản sẽ giúp thuật toán điều chỉnh sự tập trung lớn hơn ở các cặp từ (input, output) nếu chúng có vị trí tương đương hoặc gần tương đương.
Large Language Models: the extensive training data size + model size
Chatbots
Translation services
Conten creation
ORC photo
3.6.1.2. Transformer conponents#
Về thành phần của Transformer, bao gồm các conponents chính. Tuy thuộc vào Encoder hay Decoder block thì sẽ sử dụng kết hợp các conponents này kết hợp.
Embedding: Biến đổi input text đầu vào thành dạng vector
Transformer Block: Process và transform input data
Output Probabilities: Sử dụng linear hoặc softmax layer để tự đoán từ tiếp theo
See the model flow in transformer-explainer
![]()
3.6.1.2.1. Embedding#

1. Tokenization: Dữ liệu đầu vào là text được break down nhỏ hơn biến đổi thành token (word / subword). Ví dụ, câu “ChatGPT là gì?” sẽ được mã hoá thành 4 token [“ChatGPT, “là”, “gì”, “?”].
Phương pháp sử dụng subword encoding phổ biến: Byte Pair Encoding
2. Embedding: Biến token thành vector với số dimension phụ thuộc vào model. Mỗi token được chuyển thành một vector dựa vào ma trận word embedding (kích thước vocab_size x n-dimension)
Với model chatGPT-2 (small), vocab size 50257, mỗi token được biểu diễn trong vector 768-dimension. Tương đương với 39 triệu tham số.
3. Positional Encoding: Vì Transformer không xử lý tuần tự nên cần một cách để hiểu vị trí của từng từ trong câu. Điều này được thực hiện thông qua positional encodings, được cộng trực tiếp vào input embeddings. Các positional encodings có thể dùng các hàm sin và cos với bước sóng khác nhau để mỗi vị trí có một encoding duy nhất. Ý nghĩa của position encoding sẽ khác nhau tùy thuộc vào độ dài của câu đó.
Mỗi models khác nhau sẽ sử dụng phương pháp khác nhau cho encode giá trị positional encoding -
4. Final Embedding: Kết hợp Token Embedding + Positional Encoding để đưa ra final embedding representation, capture both the semantic meaning of token + the position in input sequence
3.6.1.2.2. Transformer block#
Transformer processing là tổ hợp nhiều transformer block, trong đó với mỗi block sẽ chứa Multi-head self-attention và 1 lớp Multi-layer Perceptron. Output của 2 sublayer sẽ đi qua một lớp gọi là Add & Norm.

3.6.1.2.2.1. Attention mechanism#
Cốt lõi của transformer là attention mechanism (cơ chế tập trung), giúp mô hình tập trung vào các phần quan trọng của văn bản để đưa ra dự đoán chính xác hơn. Cơ chế này cho phép giao tiếp giữa các token với nhau để có thể capture được contextual information và relationships giữa các từ
Encoder
Encoder xử lý dữ liệu đầu vào (gọi là “Source”) và nén dữ liệu vào vùng nhớ hoặc context mà Decoder có thể sử dụng sau đó.
Encoder Là phrase chuyển input thành những features learning có khả năng học tập các task. Đối với model Neural Network, Encoder là các hidden layer. Đối với model CNN, Encoder là chuỗi các layers Convolutional + Maxpooling. Model RNN quá trình Encoder chính là các layers Embedding và Recurrent Neral Network.
Decoder
Decoder nhận đầu vào từ đầu ra của Encoder (gọi là “Encoded input”) kết hợp với một chuỗi đầu vào khác (gọi là “Target”) để tạo ra chuỗi đầu ra cuối cùng.
Decoder: Đầu ra của encoder chính là đầu vào của các Decoder. Phrase này nhằm mục đích tìm ra phân phối xác xuất từ các features learning ở Encoder từ đó xác định đâu là nhãn của đầu ra. Kết quả có thể là một nhãn đối với các model phân loại hoặc một chuỗi các nhãn theo tứ tự thời gian đối với model seq2seq.
Mỗi encoder và decoder đều bao gồm nhiều lớp, mỗi lớp chứa các thành phần self-attention và feed-forward neural networks.
3.6.1.2.2.2. Multi-Head Self-attention#
1. Tạo ra bộ 3 vectơ từ các vectơ đầu vào của encoder bằng cơ chế Self-Attention
Cơ chế cho phép mỗi token có thể tương tác với các token khác trong câu, cụ thể từng token sẽ quan sát các tokens còn lại, thu thập ngữ cảnh rồi update lại vector biểu diễn bằng việc các điều chỉnh trọng số của nó cho các từ khác trong câu sao cho từ ở vị trí càng gần nó nhất thì trọng số càng lớn và càng xa thì càng nhỏ dần. Cơ chế self attention giống như cơ chế tìm kiếm. Với một từ cho trước, cơ chế này sẽ cho phép mô hình tìm kiếm trong cách từ còn lại, từ nào “giống” để sau đó thông tin sẽ được mã hóa dựa trên tất cả các từ trên.
Mỗi token embedding vector sẽ tạo ra 3 vector q,k,v dựa vào matrix tương ứng là Wq, Wk, Wv được build trong quá trình training model.
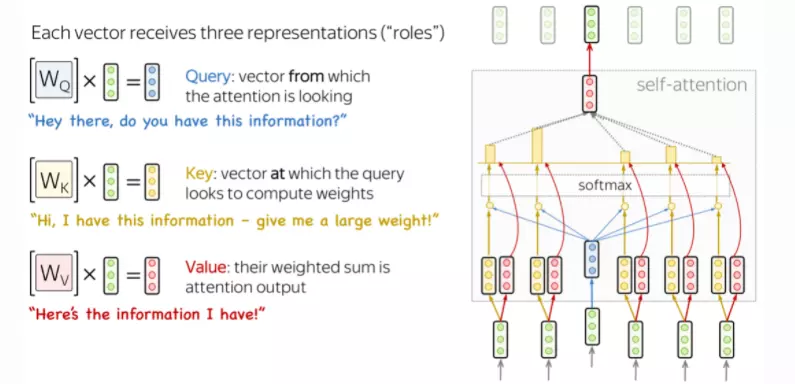
Vector
q(Query): biểu diễn thứ mà chúng ta cần tìm kiếm trong input, hoặc có thể hiểu là từ mà chúng ta đang xét đến trong câu. Query được sử dụng khi một token “quan sát” những tokens còn lại, nó sẽ tìm kiếm thông tin xung quanh để hiểu được ngữ cảnh và mối quan hệ của nó với các tokens còn lại.Ví dụ khi search google thì q đại diện cho search text
Vector
k(Key): đại diện cho mọi thành phần trong input. Vector này sẽ đóng vai trò như một bản tóm tắt thông tin của mỗi thành phần. Key sẽ phản hồi yêu cầu của Query và được sử dụng để tính trọng số attention.Đại diện cho tiêu đề từng web-page sau khi search
Vector
v(Value): biểu diễn toàn bộ thông tin của mỗi một thành phần trong câu. Value được sử dụng trọng số attention vừa rồi để tính ra vector đại diện (attention vector)Đại diện cho nội dung chi tiết bên trong từng web-page
2. Tính Attention Score
Bằng việc sử dụng 3 vector q, k, v thì model có thể tính được điểm attention scores để xác định được mức độ focus vào mỗi một token khi dự đoán output:
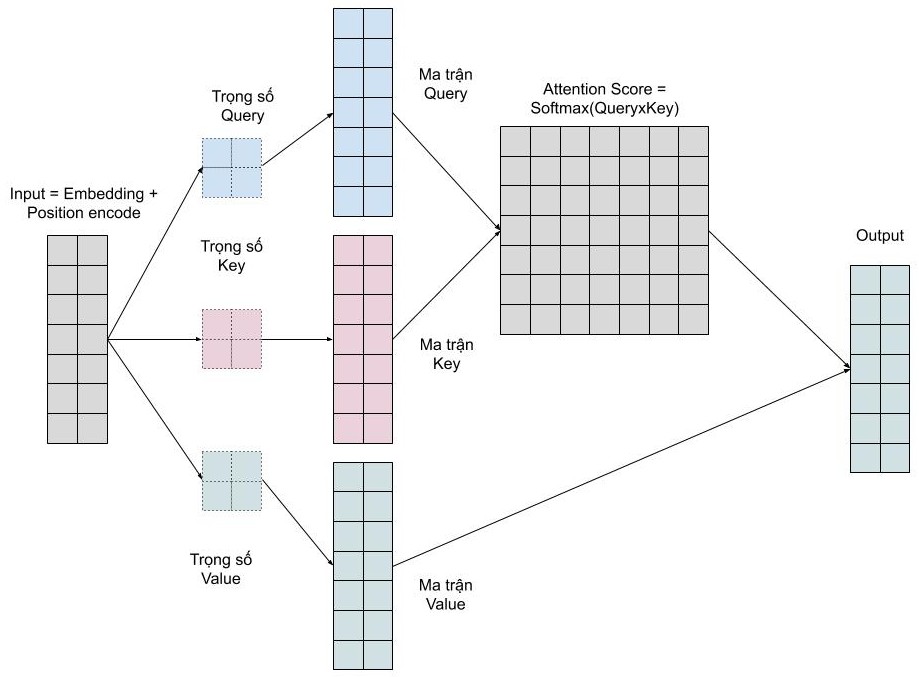
Bước 1: Tính ma trận query (Q), key (K), value (V) bằng cách khởi tạo 3 ma trận trọng số query, key, vector. Sau đó nhân input với các ma trận trọng số này để tạo thành 3 ma trận tương ứng.
Bước 2: Tính attention weights (W). Nhân 2 ma trận key (K), query (Q) vừa được tính ở trên với nhau để với ý nghĩa là so sánh giữa câu query và key để học mối tương quan. Sau đó thì chuẩn hóa về đoạn [0-1] bằng hàm softmax. 1 có nghĩa là câu query giống với key, 0 có nghĩa là không giống.
Bước 3: Tính output Attention Score. Nhân attention weights (W) với ma trận value (V).
Ta có mỗi token có các vector tương ứng là k, q. Nên với text input (nhiều token) sẽ có 1 matrix K, Q
2 matrix K và Q sẽ được dot product, tạo ra 1 square matrix thể hiện relationship giữa tất cả các input token
Điều này có nghĩa là chúng ta biểu diễn một từ bằng trung bình có trọng số (attention weights) của ma trận value.
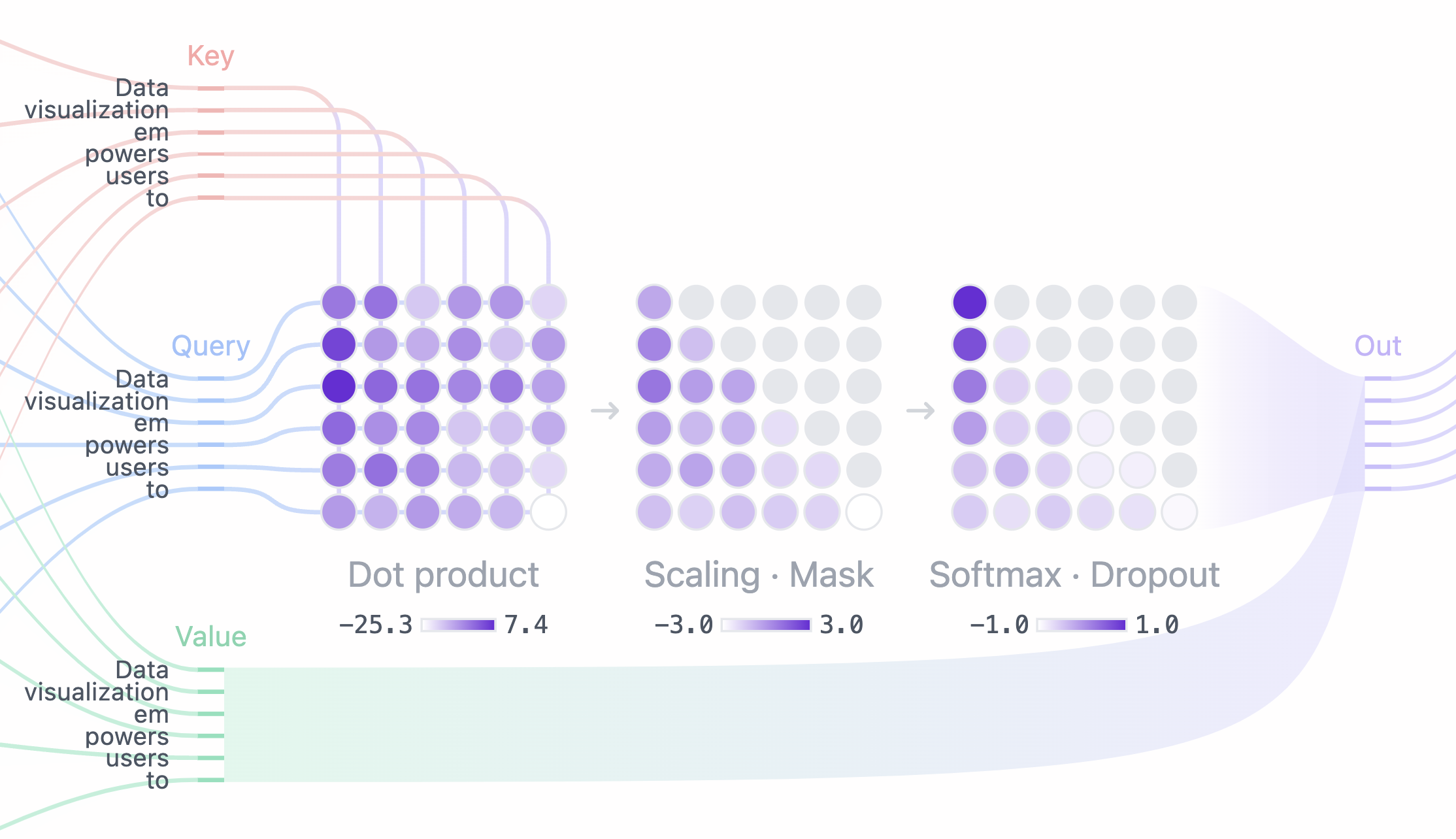
Bước 4: Masking (Decoder block ONLY)
Che giấu toàn bộ thông tin (attention score) phía trước của mỗi token
Trong khi thực hiện predict text, ta không muốn leak thông tin của future token để dự đoán, nhưng trong quá trình Encoder Block (hiểu input text) thì cần cover được hết các input truyền vào thay vì chỉ những token phía trước nó.
Bước 5: Softmax + Dropout
Convert the attention score (after masking) thành dạng probability theo từng row
Mỗi dòng của matrix thể hiện sự liên quan (probability) của token vị trí tương ứng với các từ phí trước nó.
Trong quá trình tạo ra attention weights (W), Dropout được sử dụng sau bước Softmax để tăng tính ngẫu nhiên của kết quả. Kết quả sau Dropout layer sẽ được sử dụng để kết hợp với ma trận Value (V) để tính ra final attention score của head đó.
3. Tạo ma trận Multi-Head Self-Attention
Thông thường, để có thể hiểu được vai trò của một từ trong một câu ta cần hiều được sự liên quan giữa từ đó và các thành phần còn lại trong câu. Điều này rất quan trọng trong quá trình xử lí câu đầu vào ở ngôn ngữ A và cả trong quá trình tạo ra câu ở ngôn ngữ B. Vì vậy, mô hình cần phải tập trung vào nhiều thứ khác nhau, cụ thể là thay vì chỉ có một cơ chế self attention như đã giới thiệu hay còn gọi là 1 “head” thì mô hình sẽ có nhiều “heads” mỗi head sẽ tập trung vào khía cạnh về sự liên quan giữa từ và các thành phần còn lại. Đó chính là multi-head attention:
Tính toán các vector q, k, v với các head khác nhau, mỗi head sẽ nhận dạng một đặc điểm độc lập về cấu trúc, ngữ pháp, ngữ nghĩa, mối quan hệ semantic relationships.
Với mỗi head được tính toán song song, nâng cao khả năng biểu đạt của model.
Kết hợp concat lại để tạo ra ma trận multi-head self-attention.
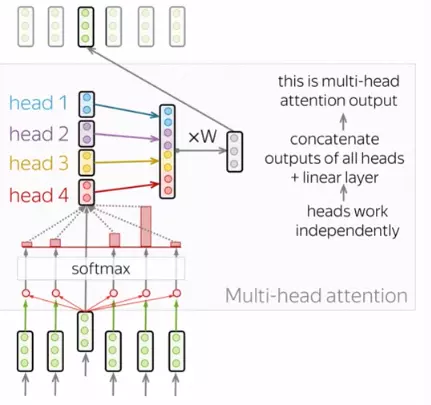
Khi triển khai, ta cần dựa vào query, key và value để tính toán cho từng head. Sau đó ta sẽ concat các ma trận thu được để thu được ma trận của multi-head attention. Để có đầu ra có cùng kích thước của đầu vào thì cần nhân với ma trận
W
Chúng ta muốn mô hình có thể học nhiều kiểu mối quan hệ giữa các từ với nhau. Với mỗi self-attention, chúng ta học được một kiểu pattern, do đó để có thể mở rộng khả năng này, chúng ta đơn giản là thêm nhiều self-attention. Tức là chúng ta cần nhiều ma trận query, key, value mà thôi. Giờ đây ma trận trọng số key, query, value sẽ có thêm 1 chiều depth nữa.
3.6.1.2.2.3. MLP (Multilayer Perceptron) Layer#
MLP is a feed-forward network (FFN) that vận hành độc lập trên từng tokens. While the goal of the attention layer is to route information between tokens, the goal of the MLP is to refine each token’s representation. Có thể hiểu là cơ chế attention giúp thu thập thông tin từ những tokens đầu vào thì FFN là khối xử lí những thông tin đó.
Cấu trúc khối MLP gồm lớp: Layer Normalization –> Residual Connection –> tăng chiều –> hàm kích hoạt (Ví dụ GELU) –> lớp giảm chiều –> Residual Connection –> Layer Normalization.
Residual Connection: Giúp truyền thông tin trực tiếp từ đầu vào sang đầu ra sub-layer, giúp gradient lan truyền tốt, tránh mất mát thông tin.
Layer Normalization: Ổn định phân phối dữ liệu, giúp quá trình huấn luyện dễ hội tụ hơn.
Trong kiến trúc Transformer, sau khi qua cơ chế self-attention (multi-head self-attention đảm nhận việc học các mối quan hệ đa dạng giữa các token đầu vào), đầu ra được ghép (concatenate) từ các heads đó sẽ đi vào khối MLP (Multilayer Perceptron).
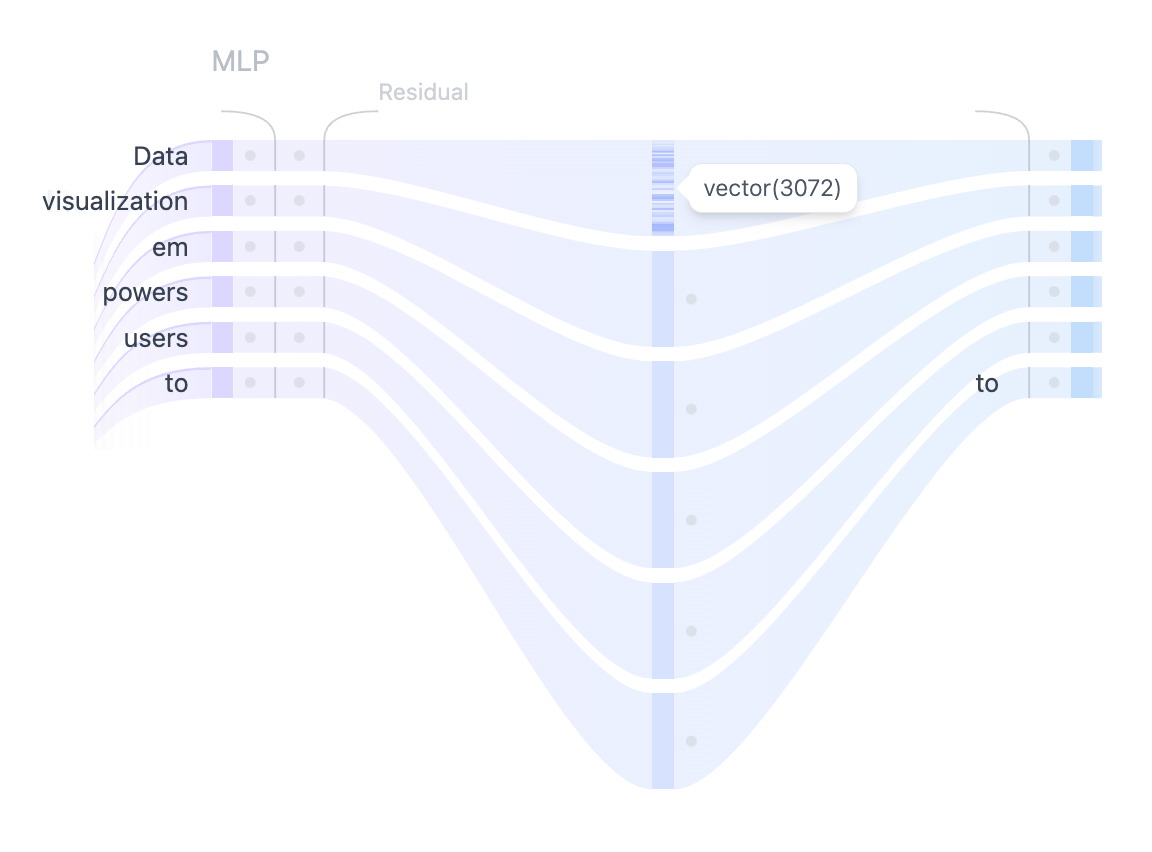
Lý do MLP đứng sau Self-Attention?
Bổ sung phi tuyến (Non-linearity): Self-Attention có bản chất là các phép tính linear (mặc dù có 1 số lớp bổ sung nhằm hạn chế tính linear) do là các phép tính với matrix. Khối MLP thêm một thành non-linear, giúp mô hình có thể biểu đạt được các hàm phức tạp hơn.
Học đặc trưng ở mức token: Self-Attention chú trọng vào việc trộn thông tin giữa các token, trong khi MLP đảm nhận nhiệm vụ chuyển đổi vector của từng token (nghĩa là, cách biểu diễn mỗi token được học sâu hơn, độc lập).
Tăng chiều tạm thời (Intermediate Dimensionality): Bằng cách nâng chiều ẩn lên (Projection Up), MLP cho phép discovery more hidden information, sau đó “nén” lại (Projection Down), có tác dụng extract and combine additional feature cho Self-Attention.
Vị trí của FFN trong lớp Transformer:
Trong block Encoder: Mỗi lớp encoder bao gồm hai sub-layer chính: cơ chế self-attention (multi-head attention) và mạng feed-forward. Sau khi đầu ra của self-attention được xử lý qua một bước chuẩn hóa lớp (layer normalization) và kết nối dư (residual connection), nó sẽ được đưa vào mạng feed-forward. Mạng feed-forward này tiếp tục xử lý thông tin đã được tập trung bởi cơ chế attention.
Trong block Decoder: Mỗi lớp decoder (trong kiến trúc encoder-decoder đầy đủ) bao gồm ba sub-layer: masked self-attention, cross-attention, và mạng feed-forward. Tương tự như encoder, đầu ra của cross-attention (attend to encoder output) sau khi được layer normalization và áp dụng residual connection sẽ được đưa vào mạng feed-forward để xử lý tiếp. Trong kiến trúc decoder-only (ví dụ như GPT), mỗi lớp decoder chỉ có masked self-attention và mạng feed-forward.
3.6.1.2.2.4. Add & Norm Layers#
![]()
Bao gồm hai bước Add và Norm:
Bước Add thêm Residual Connections allows gradients to flow directly through the network and helps to prevent the vanishing gradient problem, Nhằm giảm vấn đề vashing gradient (mất độ dốc) trong các deep network (mạng sâu). Giúp giảm bớt khó khăn khi huấn luyện các mạng sâu (vanishing gradients) bằng cách thêm một “đường tắt” (shortcut) cho phép tín hiệu đầu vào của một lớp cộng trực tiếp vào đầu ra của lớp đó. Kết nối residual bản chất rất đơn giản: thêm đầu vào của một khối vào đầu ra của nó. Với kết nối này giúp mạng có thể chồng được nhiều layers. Như trên hình, kết nối residual sẽ được sử dụng sau các khối FFN và khối attention
Trong GPT-2, các kết nối dư được dùng hai lần trong mỗi khối Transformer: một lần trước MLP và một lần sau, giúp lan truyền gradient tốt hơn và hỗ trợ các lớp ban đầu được cập nhật hiệu quả.
Ngay sau đó, bước Norm thực hiện Layer Normalization (chuẩn hoá lớp) giúp ổn định quá trình huấn luyện và giảm số lượng giai đoạn cần thiết để huấn luyện, tăng tốc độ converge. Layer Normalization được áp dụng để ổn định quá trình huấn luyện và cải thiện sự hội tụ. Nó chuẩn hóa đầu vào trên các đặc trưng (features), duy trì trung bình và phương sai nhất quán, nhờ đó giảm thiểu hiện tượng “internal covariate shift” và tăng hiệu quả học của mô hình.
Trong GPT-2, Layer Normalization được dùng hai lần trong mỗi khối Transformer: trước cơ chế tự chú ý (self-attention) và trước MLP.
3.6.1.2.3. Output Probabilities#
The final linear and softmax layers transform the processed embeddings into probabilities, enabling the model to make predictions about the next token in a sequence.
Trong bước cuối cùng để sinh ra token kế tiếp, mô hình Transformer (hoặc các mô hình ngôn ngữ tương tự) sử dụng xác suất đã tính được (qua cơ chế Softmax trên logits), và lấy mẫu (sampling) để chọn token tiếp theo. Dưới đây là ba tham số ảnh hưởng lớn đến chất lượng và tính đa dạng của đầu ra.
3.6.1.2.3.1. Quá trình sinh ra token kế tiếp#
Dưới đây là các bước chính mà một mô hình Transformer (hoặc các mô hình tương tự) thực hiện để tạo ra token kế tiếp trong quá trình sinh văn bản (text generation):
Nhận vector ẩn (hidden state)
Ở mỗi bước dự đoán (vị trí token), mô hình (phần Decoder) trả về một vector ẩn kích thước
hidden_dim.Vector này chứa thông tin về:
Ngữ cảnh từ các token đầu ra trước đó.
Ngữ cảnh từ chuỗi đầu vào (nếu là mô hình Encoder-Decoder).
Lịch sử hội thoại (trong trường hợp chatbot).
Chiếu (Projection) sang không gian từ vựng (vocab)
Hidden state được đưa qua một lớp tuyến tính (linear layer) có trọng số kích thước
hidden_dim x vocab_size.Đầu ra là logits – một mảng giá trị kích thước
vocab_size(mỗi phần tử tương ứng với một token trong từ vựng).
Tính xác suất (Softmax)
Mô hình áp dụng hàm Softmax lên
logitsđể thu được phân phối xác suất cho toàn bộ từ vựng.Công thức Softmax cho phần tử thứ \(i\) trong
logits:\[P_i = \frac{e^{\text{logits}[i]}}{\sum_{j=1}^{\text{vocab\_size}} e^{\text{logits}[j]}}\]Mỗi \(P_i\) thể hiện xác suất mô hình đoán token thứ \(i\) là token kế tiếp.
Tinh chỉnh phân phối (Temperature, Top-k, Top-p, …) (tuỳ chọn)
Temperature \(\tau\):
Chia logits cho \(\tau\) để điều chỉnh mức “sắc nét” của phân phối.
\(\tau < 1\) → phân phối tập trung (mô hình quyết đoán hơn).
\(\tau > 1\) → phân phối phẳng hơn (mô hình sáng tạo hơn).
Top-k:
Chỉ giữ \(k\) token có xác suất cao nhất, bỏ các token còn lại.
Chuẩn hoá lại xác suất trong nhóm \(k\) này rồi lấy mẫu.
Top-p (Nucleus Sampling):
Sắp xếp token theo xác suất giảm dần.
Chọn nhóm token có tổng xác suất \(\ge p\).
Chuẩn hoá lại và lấy mẫu.
Chọn token kế tiếp (Sampling / Greedy / Beam Search)
Sampling: Rút ngẫu nhiên token từ phân phối (đã tinh chỉnh).
Greedy: Chọn token có xác suất cao nhất (phân phối không hoặc ít điều chỉnh).
Beam Search: Duy trì nhiều “nhánh” tiềm năng, tìm chuỗi đầu ra có xác suất tích luỹ cao nhất.
Ghép token vào câu kết quả
Token được chọn sẽ được gắn vào câu đang xây dựng.
Các bước (1) → (5) lặp lại cho token tiếp theo, đến khi gặp token đặc biệt (ví dụ
<EOS>), hoặc đạt giới hạn độ dài.
3.6.1.2.3.2. Tham số lựa chọn phân phối#
3.6.1.2.3.2.1. Temperature#
Temperature kiểm soát độ “sắc nét” hay “phẳng” của phân phối xác suất trước khi áp dụng Softmax, bằng cách chia logits cho một hằng số \(\tau\) (temperature):
\(\tau\) = 1 (temperature = 1)
Không thay đổi phân phối xác suất.
Mô hình tạo ra câu trả lời ở mức “bình thường,” vừa phải.
\(\tau\) < 1
Làm phân phối “sắc nét” hơn (sharper).
Mô hình trở nên “quyết đoán” hơn, xác suất cho token có khả năng cao nhất trở nên vượt trội, dễ tạo ra câu ổn định, ít ngẫu nhiên nhưng có thể kém đa dạng.
\(\tau\) > 1
Làm phân phối “phẳng” hơn (softer).
Mô hình có tính “ngẫu nhiên,” “sáng tạo” hơn, sinh những đáp án đa dạng hơn nhưng đôi khi kém mạch lạc.
3.6.1.2.3.2.2. Top-k Sampling#
Top-k giới hạn việc chọn token ở k từ (token) có xác suất cao nhất.
Mô hình tạo xác suất cho toàn bộ từ vựng (có thể lên tới hàng chục nghìn token).
Chỉ giữ lại k token có xác suất cao nhất, loại bỏ các token còn lại.
Chuẩn hoá lại xác suất trong nhóm k này thành tổng bằng 1.
Lấy mẫu một token từ nhóm k đó.
Ví dụ:
top-k = 50nghĩa là mỗi lần sinh token, chỉ quan tâm đến 50 từ có xác suất cao nhất.Lợi ích: Tránh việc mô hình chọn những từ cực kỳ ít khả năng (tỉ lệ nhỏ), giúp văn bản tập trung hơn nhưng vẫn đủ linh hoạt so với greedy search.
3.6.1.2.3.2.3. Top-p Sampling (Nucleus Sampling)#
Top-p (còn gọi là Nucleus Sampling) dựa vào xác suất tích luỹ thay vì giới hạn k cố định.
Sắp xếp token theo xác suất giảm dần.
Chọn tập hợp nhỏ nhất các token sao cho tổng xác suất của chúng ≥ p.
Chuẩn hoá lại xác suất cho nhóm token này và lấy mẫu.
Ví dụ:
top-p = 0.9Mô hình chỉ giữ các token mà tổng xác suất >= 0.9, có thể là 30 token trong một trường hợp, nhưng có thể là 10 hoặc 50 trong trường hợp khác, tuỳ theo phân phối.
Lợi ích: Linh hoạt hơn top-k, vì số token được chọn thay đổi tùy vào độ “phân tán” của phân phối.
3.6.1.2.3.2.4. Kết hợp Temperature, Top-k, Top-p#
Temperature điều khiển “mức ngẫu nhiên” hay “sáng tạo” tổng thể.
Top-k và Top-p lọc bớt các token kém khả thi để tập trung vào nhóm token tiềm năng.
Bằng cách tinh chỉnh ba tham số này, bạn có thể tạo ra đầu ra:
Mang tính xác định và nhất quán (khi giảm temperature, giảm top-p, giảm hoặc giữ top-k ở mức vừa phải).
Đa dạng, sáng tạo (khi tăng temperature, sử dụng top-p rộng hoặc top-k tương đối cao).
Tóm lại, temperature, top-k, và top-p là những tham số quan trọng giúp bạn cân bằng giữa tính xác định (deterministic) và tính đa dạng (diversity) trong câu trả lời của mô hình. Bạn có thể điều chỉnh chúng tuỳ thuộc vào yêu cầu cụ thể của ứng dụng chatbot hoặc sinh văn bản.
3.6.1.3. Transformer Models#
3.6.1.3.1. Tổng quan mô hình#
Transformer có khả năng
Xử lý song song: Transformer xử lý đầu vào theo từng khối, không tuần tự. Điều này cho phép việc huấn luyện mô hình được thực hiện song song, giảm đáng kể thời gian cần thiết để huấn luyện mô hình.
Self-Attention: Cơ chế này giúp Transformer xác định được mối quan hệ giữa tất cả các từ trong một câu, bất kể khoảng cách giữa chúng trong văn bản, giải quyết vấn đề về phụ thuộc dài hạn.
Hiệu suất và mở rộng: Với khả năng xử lý đồng thời, Transformer tận dụng tối đa sức mạnh của phần cứng hiện đại, như GPU và TPU, để xử lý các tác vụ NLP một cách hiệu quả.
Học biểu diễn chuỗi tốt hơn nhờ cơ chế attention -> một chuỗi đơn được biểu diễn nhờ sự kết hợp thông tin của toàn bộ chuỗi, thông tin quan trọng từ những vị trí khác trong chuỗi được khuếch đại, ngược lại thông tin không quan trọng sẽ bị bỏ qua. Ví dụ với chuỗi là câu nói “Trời hôm nay trở lạnh vì gió mùa tràn về”, chuỗi đơn sẽ là các từ trong câu. Dễ thấy từ “lạnh” có sự liên quan với từ “gió mùa”, khi biểu diễn từ “lạnh” cơ chế attention từ sẽ khuếch đại thông tin của từ “gió mùa” và kết hợp với thông tin của chính từ đó để tạo thành một biểu diễn tốt hơn cho từng từ.
Detail-architecture
![]()
Trong block Encoder và Decoder sẽ bao gồm nhiều lớp tương ứng, mỗi layer xử lý đồng thời nhiều từ (Khác với LSTM thì phải xử lý tuần tự). Ngoài ra, kiến trúc transfomer cho phép xử lý input text theo 2 hướng khác nhau
Encoder block: Tiếp nhận chuỗi đầu vào (input sequence) và tạo ra các biểu diễn ngữ cảnh (contextual representations) cho mỗi token. The primary function of the encoder is to create a high-dimensional representation of the input sequence that the decoder can use to generate the output. Encoder consists multiple layers and each layer is composed of two main sub-layers:
Self-Attention Mechanism: This sub-layer allows the encoder to weigh the importance of different parts of the input sequence differently to capture dependencies regardless of their distance within the sequence.
Feed-Forward Neural Network: This sub-layer consists of two linear transformations with a ReLU activation in between. It processes the output of the self-attention mechanism to generate a refined representation.
Layer normalization and residual connections are used around each of these sub-layers to ensure stability and improve convergence during training.
Decoder block: Sử dụng thông tin ngữ cảnh từ encoder để dự đoán từng token của đầu ra (output sequence), có tính đến những token đầu ra đã được tạo ra trước đó (nhờ cơ chế “mask” trong self-attention ở decoder). Decoder in transformer also consists of multiple identical layers. Its primary function is to generate the output sequence based on the representations provided by the encoder and the previously generated tokens of the output. Each decoder layer consists of three main sub-layers:
Masked Self-Attention Mechanism: Similar to the encoder’s self-attention mechanism but with a mask to prevent the decoder from attending to future tokens in the output sequence.
Encoder-Decoder Attention Mechanism: This sub-layer allows the decoder to focus on relevant parts of the encoder’s output representation, facilitating the generation of coherent and contextually appropriate output sequences.
Feed-Forward Neural Network: This sub-layer processes the combined output of the masked self-attention and encoder-decoder attention mechanisms.
3.6.1.3.2. Input Preprocessing#
Người dùng nhập câu hỏi/tin nhắn
Ví dụ: “Thời tiết hôm nay thế nào?”
Tokenization
Chuyển câu văn thành các token (từ, subword, BPE,…).
Ví dụ:
["Thời", "tiết", "hôm", "nay", "thế", "nào", "?"].
Embedding & Positional Encoding
Mỗi token được ánh xạ (embedding) sang một vector (chẳng hạn 512 hoặc 768 chiều).
Thêm Positional Encoding (hoặc Position Embedding) để mô hình biết vị trí token.
Kết quả: một ma trận embedding \(\mathbf{E}\) (kích thước
chuỗi x hidden_dim).
Đưa dữ liệu vào Encoder
Ma trận \(\mathbf{E}\) (đã có positional encoding) sẽ được chuyển qua các lớp (layers) của encoder.
3.6.1.3.3. Encoder Process#
Mỗi layer của Encoder thường gồm hai thành phần chính:
Self-Attention (Multi-Head)
Giúp các token trong câu nhìn và trộn thông tin lẫn nhau.
Đầu vào: ma trận embedding (hoặc đầu ra của layer trước).
Đầu ra: ma trận biểu diễn (contextualized) giúp mỗi token “hiểu” được các token khác.
Feed-Forward Network (MLP)
Sau self-attention, mỗi token tiếp tục qua MLP 2 tầng (thường kèm hàm kích hoạt như ReLU/GELU).
MLP hoạt động position-wise, tức độc lập cho từng token.
Mỗi sub-layer (Self-Attention, MLP) có Residual Connection và Layer Normalization giúp ổn định và duy trì thông tin.
Sau \(N\) lớp encoder, ta được EncOutput - biểu diễn ngữ cảnh cho toàn bộ chuỗi (kích thước chuỗi x hidden_dim).
Encoder Process:
Input Embedding: The input sequence is tokenized and converted into embeddings with positional encodings added.
Self-Attention Mechanism: Each token in the input sequence attends to every other token to capture dependencies and contextual information.
Feed-Forward Network: The output from the self-attention mechanism is passed through a position-wise feed-forward network.
Layer Normalization and Residual Connections: Layer normalization and residual connections are applied.
3.6.1.3.4. Decoder Process#
Mỗi layer của Decoder gồm 3 phần chính:
Masked Self-Attention
Decoder cần dự đoán token tương lai, nên sử dụng “look-ahead mask” để token hiện tại chỉ được nhìn các token trước đó trong câu đầu ra.
Sau đó, Residual + LayerNorm như ở encoder.
Cross-Attention (Encoder-Decoder Attention)
Decoder “nhìn” sang EncOutput (đầu ra encoder) để lấy ngữ cảnh về chuỗi input.
Kết quả của cross-attention giúp kết hợp thông tin giữa token output và token input.
Feed-Forward Network (MLP)
Mỗi token đầu ra tiếp tục qua MLP 2 tầng, tương tự bên encoder.
Kết quả lại cộng (residual) và chuẩn hóa (layer norm).
Sau \(N\) lớp decoder, ta thu được Decodings (kích thước chuỗi x hidden_dim).
Decoder Process:
Input Embedding and Positional Encoding: The partially generated output sequence is tokenized and embedded with positional encodings added.
Masked Self-Attention Mechanism: The decoder uses masked self-attention to prevent attending to future tokens ensuring that the model generates the sequence step-by-step.
Encoder-Decoder Attention Mechanism: The decoder attends to the encoder’s output allowing it to focus on relevant parts of the input sequence.
Feed-Forward Network: Similar to the encoder the output from the attention mechanisms is passed through a position-wise feed-forward network.
Layer Normalization and Residual Connections: Similar to the encoder Layer normalization and residual connections are applied.
Mô hình Decoder-only
Một số mô hình (GPT-2, GPT-3, ChatGPT) dùng decoder-only.
Ở đó, “encoder” được embedding trong prompt, mô hình vẫn lấy thông tin ngữ cảnh qua attention, nhưng không tách riêng thành encoder.
Dòng chảy dữ liệu cơ bản vẫn tương tự: self-attention (có masking) và MLP, còn thông tin “ngữ cảnh” được nối chung cùng đầu vào.
3.6.1.3.5. Output Generation#
Linear + Softmax
Biến đổi (projection) Decodings thành logits trên không gian từ vựng.
Dùng Softmax để có xác suất cho từng token có thể xảy ra.
Chọn token
Ở quá trình sinh (generation), mô hình sẽ chọn token có xác suất cao (hoặc dùng sampling/beam search) làm token tiếp theo.
Bước này lặp lại đến khi đạt câu trả lời hoàn chỉnh (gặp token End of Sentence hoặc đạt độ dài tối đa).
Chuỗi đầu ra
Toàn bộ token được chọn ra theo thứ tự tạo thành câu trả lời của chatbot.
3.6.1.3.6. Encoder-decoder models#
3.6.1.3.6.1. Encoder models#
Model chỉ có block Encoder (Không chưa block Decoder), phục vụ một số task liên quan đến việc understand input text (ví dụ như sentence classification, named entity recognition, extractive question answering) mà không có yêu cầu về generate text, khi đó output là Class (label) hoặc con số (chứ ko phải là content text)
Một số model: BERT
3.6.1.3.6.2. Decoder models#
Model chỉ có block Decoder (Không chưa block Encoder), phục vụ một số task liên quan đến việc predict next word
Một số model: CTRL, GPT
Tính chất Features của decoder models:
Autoregressive Nature: generate text by predict the next word in a sequence, using all previous words as context
Transformer Architecture: use the decoder part, focusing on text generation rather than understanding
Few-Shot Learning: perform tasks with minimal examples (few-shot), a single example (one-shot) or even without any examples (zero-shot)
3.6.1.3.6.3. Encoder-Decoder models#
Model sử dụng cả hai block là Encoder và Decoder để genrate new sentences base on input text:
summarization
translation
generative question answering
Một số model: BART, T5
3.6.1.4. Use-case practical Labs#
!pip install -q transformers
from transformers import (
AutoModel,
AutoModelForCausalLM,
AutoModelForSeq2SeqLM,
AutoTokenizer,
)
from transformers import pipeline
3.6.1.4.1. Sentiment classification (BERT)#
# load BERT models (load models only)
# BERT = AutoModel.from_pretrained("bert-base-uncased")
# print(BERT)
# load full pipeline models (tokenizer + models + others)
classifier = pipeline(
"text-classification",
model="nlptown/bert-base-multilingual-uncased-sentiment",
)
print("Model Architecture:\n", classifier.model, end="\n------\n")
text = """This movie is normal."""
prediction = classifier(text)
print(f"Predict '{text}' is {prediction}")
Model Architecture:
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(105879, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=5, bias=True)
)
------
Predict 'This movie is normal.' is [{'label': '3 stars', 'score': 0.35550278425216675}]
3.6.1.4.2. Completed sentences (GPT)#
from transformers import pipeline, AutoTokenizer
# Load the tokenizer and add the pad token if it's missing
tokenizer = AutoTokenizer.from_pretrained("gpt2")
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
# Use a pipeline as a high-level helper with the modified tokenizer
generator = pipeline(model="gpt2", tokenizer=tokenizer)
text = "It's long time to"
prediction = generator(
text,
do_sample=True,
top_p=0.7,
num_return_sequences=3,
max_new_tokens=20,
return_full_text=False,
)
for item in prediction:
print(text, "...", item["generated_text"])
It's long time to ... tell. I think I'm about to be born. And when I get my first child, I
It's long time to ... wait, but it's not as bad as it sounds," said Tulloch, who said the
It's long time to ... get the game back on track, but I think we're going to get to a point where we
3.6.1.4.3. Summarization (BART)#
min_length: The minimum length of the summary.max_length: The maximum length of the summary.num_beams: The number of beams for beam search. Higher values can lead to - better quality summaries but are more computationally expensive.do_sample: Whether or not to use sampling; use greedy decoding otherwise.top_k: The number of highest probability vocabulary tokens to keep for - top-k-filtering.top_p: The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling.temperature: The value used to module the next token probabilities. Lower values make the model more confident.
text = """
To participate in the program in the most convenient way,
we encourage students to use a computer with at least 16GB RAM and 150GB hard drive space (SSD is recommended).
During the course, we will use the Ubuntu 22.04 operating system;
however, version 20.04 is also a reasonable choice if it is pre-installed.
For students using Macbooks, Ubuntu is not required to be installed, however,
having a computer running Ubuntu will be the best choice.
Note that you should avoid using very old processors (such as Intel i3 chips produced 10 years ago)
to ensure smooth and efficient computer operation throughout the course.
"""
summarizer = pipeline(
"summarization", model="facebook/bart-large-cnn", device="cuda"
)
print(summarizer.model)
BartForConditionalGeneration(
(model): BartModel(
(shared): BartScaledWordEmbedding(50264, 1024, padding_idx=1)
(encoder): BartEncoder(
(embed_tokens): BartScaledWordEmbedding(50264, 1024, padding_idx=1)
(embed_positions): BartLearnedPositionalEmbedding(1026, 1024)
(layers): ModuleList(
(0-11): 12 x BartEncoderLayer(
(self_attn): BartSdpaAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(decoder): BartDecoder(
(embed_tokens): BartScaledWordEmbedding(50264, 1024, padding_idx=1)
(embed_positions): BartLearnedPositionalEmbedding(1026, 1024)
(layers): ModuleList(
(0-11): 12 x BartDecoderLayer(
(self_attn): BartSdpaAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(activation_fn): GELUActivation()
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(encoder_attn): BartSdpaAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(lm_head): Linear(in_features=1024, out_features=50264, bias=False)
)
sum = summarizer(text, min_length=20, max_length=100)
print(sum[0]["summary_text"])
To participate in the program in the most convenient way, we encourage students to use a computer with at least 16GB RAM and 150GB hard drive space (SSD is recommended). During the course, we will use the Ubuntu 22.04 operating system.
3.6.1.4.4. Summarization (T5)#
# Load the T5 model and tokenizer
model_name = "t5-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# Create a summarization pipeline
summarizer = pipeline("summarization", model=model, tokenizer=tokenizer, device=0) # Assuming CUDA device 0
# Generate the summary
summary = summarizer(text, min_length=20, max_length=100)
print(summary)
[{'summary_text': 'students should use a computer with at least 16GB RAM and 150GB hard drive space . we will use the Ubuntu 22.04 operating system; however, version 20.04 is also a reasonable choice if it is pre-installed .'}]