3.5.1.6. Language Models#
3.5.1.6.1. Recurrent Neural Network (RNN’s)#
Khi đọc và hiểu 1 words thì để hiểu từ đó trong cả câu/ngữ cảnh đó, hay nói cách khác cần phải hiểu bối cảnh của câu hoặc các words trước đó. Ví dụ chúng ta có 2 câu là “Bố ăn tối chưa ?” và “Bố chưa ăn tối”. Mặc dù cả 2 sequence đều có các từ giống nhau nhưng khác nhau về mặt ý nghĩa. Thứ tự các words quyết định ý nghĩa của sentence.
Khi RNN looks at 1 sequence of text (dưới dạng numeric), các pattern sẽ được học 1 cách liên tục dựa vào order của sequence đó. RNN’s là mạng đặc trưng bởi việc lấy những input(x) + previous inputs để compute Y, helpful when dealing with sequences data, such as natural language text.
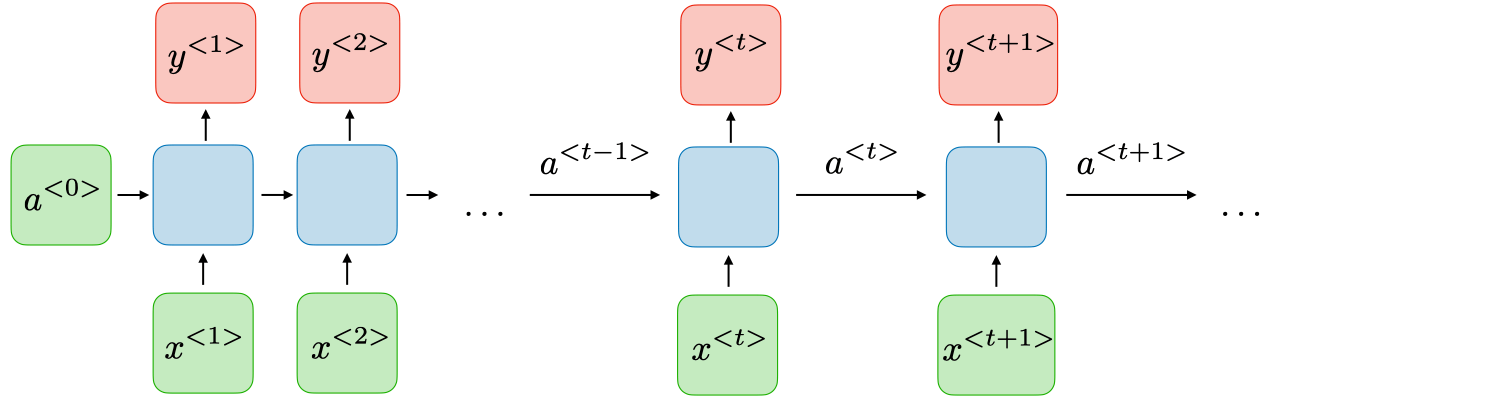
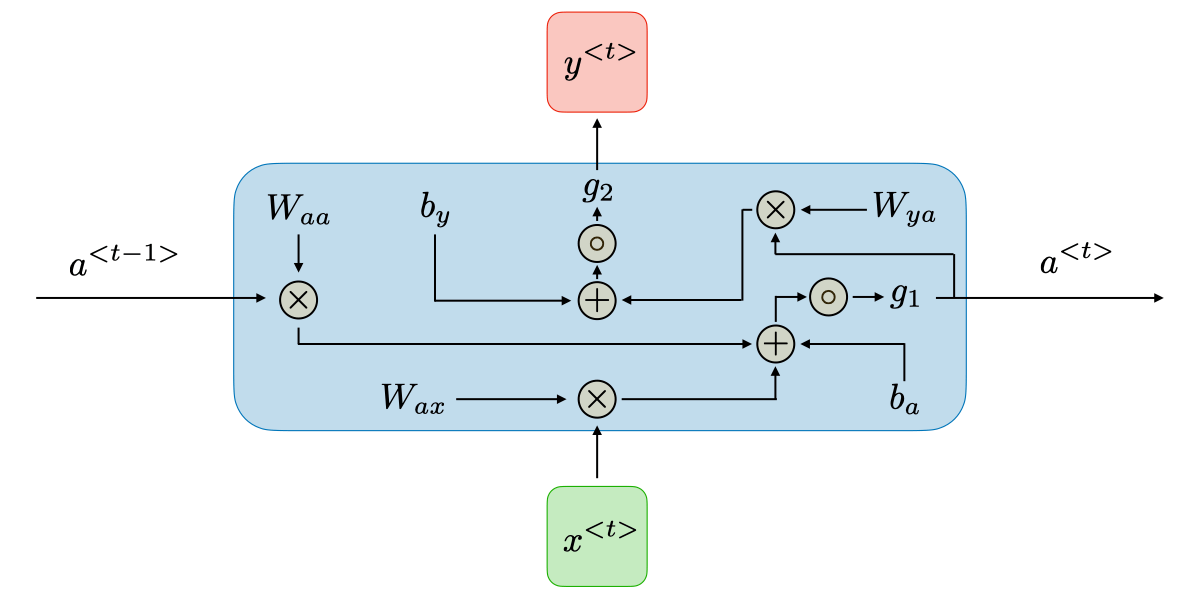
Với mỗi timestep t, the activation \(a^{<t>}\) và output \(y^{t}\) được tính theo công thức
\[a^{<t>}=g_{1}(W_{a a}a^{<t-1>}+W_{a x}x^{<t>}+b_{a})\]
\[y^{<t>}=g_{2}(W_{y a}a^{<t>}+b_{y})\]
Trong đó các hệ số W và b là các weights sẽ được update trong quá trình learn, còn g1, g2 là các hàm activation functions
Ưu điểm của RNN:
Xử lý input có bất kỳ độ dài như thế nào
Model size not increasing with size of input
Computation takes into account history information
Weights được share theo thời gian
Hạn chế của RNN:
Phải thực hiện tuần tự data, nên ko tuận dụng được sức mạnh tính toán song song (CPU/GPU), tính toán lâu
Khó trong việc accessing những long-history information vào thời điểm hiện tại
Cannot consider any future input for the current state
Vanishing gradient: do các hàm activation trong RNN thường là
tanh(có output y [-1,1] và đạo hàm [0,1]) vàsigmoid(có output y [0,1] và đạo hàm [0,0.25]), rất dễ gây ra đạo hàm = 0 với các giá trị activation_input lớn khiến các weights phía xa đều không được update, tức là các node phía xa không còn tác dụng nhiều tới node hiện tại nữa. Có một số cách khắc phục bằng việc:Sử dụng activation là ReLU hoặc các biến thể
Sử dụng 1 số mạng biến thể như GRU hay LSTM
3.5.1.6.1.1. Một số các triển khai của RNN’s#

One to one: one input, one output. Ví dụ: image classification,…
One to many: one input, many output. Ví dụ: image captioning (input 1 image, output ra 1 sequence of text as image caption)
Many to one: many input, one output. Ví dụ: text classification,…
Many to many: many input, many output. Ví dụ: machine translation, speech to text,…
Ví dụ Many to many:
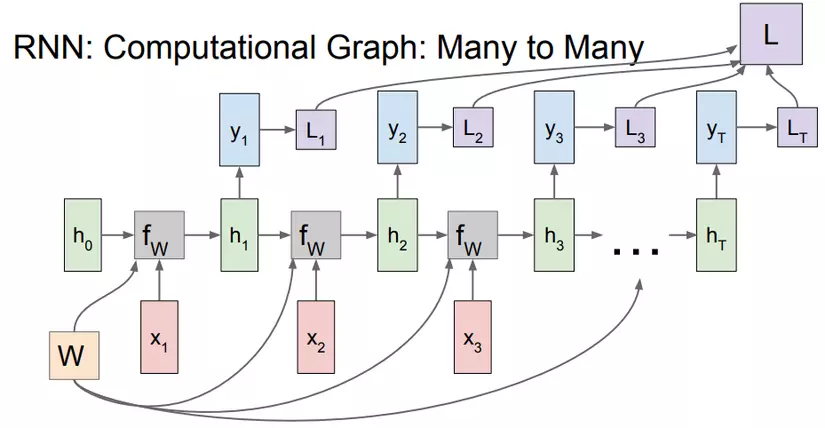
Nếu như mạng NN chỉ là input_layer \(x\) đi qua hidden_layer \(h\) và cho ra output_layer \(y\) với fully connected giữa các layers thì trong RNN, các input \(x_t\) sẽ được kết hợp với hidden layer \(h_{t-1}\) chạy qua activation function \(g_1\) để tính toán ra hidden layer \(h_t\). Thường hàm \(g_1\) là hàm \(\tanh\) kết hợp với tập hợp các trọng số W (tính là total Loss từ L1, L2,..Lt). Ngoài ra còn có activation function \(g_2\) khi tính toán output \(y_t\). $\(h_t = g_1(h_{t-1}, x_t) = \tanh (W_{hh}h_{t-1} + W_{xh}x_{t} + b_h)\)\( Tính output \)y_t\(: \)\(y_t = g_2(W_{hy}h_t + b_y)\)$
Tổng hợp quá trình tính toán được thể hiện:
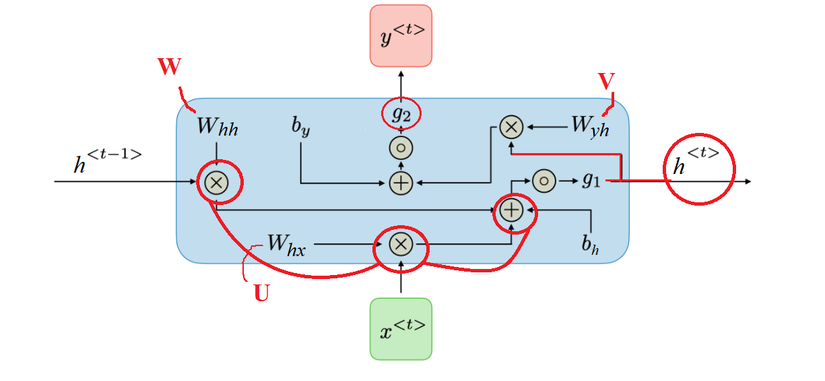
Trong mạng NN thì chỉ có 1 matrix \(W\) duy nhất, nhưng trong mạng RNN thì có 3 matrix trọng số:
\(W_{hh}\): là matrix trọng số của “bộ nhớ trước” \(h_{t-1}\)
\(W_{xh}\): là matrix trọng số của “input hiện tại” \(x_t\)
\(W_{hy}\): là matrix trọng số của “bộ nhớ hiện tại” \(h_t\) để tạo ra output \(y_t\)
3.5.1.6.1.2. Applications of RNNs#
Loại network |
minh hoạ |
ứng dụng |
|---|---|---|
One-to-One |
|
Traditional Neral network |
One-to-many |
|
Music generation |
Many-to-one |
|
Sentiment classification |
Many-to-many |
|
Name entity recognition |
Many-to-many |
|
Machine translation |





RNN cho phép ta dự đoán xác suất của một từ mới nhờ vào các từ đã biết liền trước nó. Cơ chế này hoạt động giống với ví dụ bên trên, với các đầu ra của cụm này sẽ là đầu vào của cụm tiếp theo cho đến khi ta được một câu hoàn chỉnh. Các input thường được encode dưới dạng 1 vector one hot encoding. Ví dụ với tập dataset gồm 50000 câu ta lấy ra được một dictionary gồm 4000 từ, từ “hot” nằm ở vị trí 128 thì vector one hot của từ “hot” sẽ là một vector gồm 4000 phần tử đều bằng 0 chỉ có duy nhất vị trí 128 bằng 1. Mô hình này này chính là mô hình Many to Many với số lượng đầu ra, đầu vào và lớp ẩn bằng nhau.
3.5.1.6.1.3. Loss function#
Loss function của RNNs bằng tổng loss tại mỗi output trong mạng
3.5.1.6.1.4. Handling long term dependencies#
Activation Function
Các hàm activation function phổ biến trong RNNs là : sigmoid, tanh, ReLU
Vanishing/exploding gradient
Hiện tượng gradient biến mất hoặc bùng nổ thường xuyên xảy ra trong mạng RNN, nên rất khó trong việc capture những yếu tố dài hạn phía trước ảnh hưởng tới hiện tại.
Gradient clipping thường được sử dụng để setting max value of gradient trong TH gặp phải vấn đề gradient exploding

Tham số |
LSTM |
GRU |
|---|---|---|
Minh hoạ |
|
|

Loại gate - state |
Công thức |
Vai trò |
minh hoạ |
|---|---|---|---|
Forget gate \(f_t\) |
$\( f_t = \text{sigmoid}(W_f.[h_{t-1}, x_t] + b_f) \)$ |
Forget gate quyết định thông tin nào từ bộ nhớ dài hạn được lưu giữ hoặc loại bỏ |
|

\(C_{t}\,\longrightarrow\,f_{t}\,*\,C_{t-1}\,+\,\dot{\iota}_{t}\,*\,\widetilde C_{t}\)
3.5.1.6.2. LSTM#
Long short-term memory cells (LSTMs) khác RNN ở điểm thay vì 1 tầng mạng neural với hàm tanh thì LSTM có 4 tâng (4 cổng gate) tương tác với nhau, nhờ vậy mà có thể bỏ đi hoặc thêm vào các thông tin cần thiết thông qua các gate, một nơi giúp sàng lọc thông tin với activation là 1 hàm sigmoid.
Tầng sigmoid cho output trong khoảng [0,1], mô tả có bao nhiêu thông tin có thể được thông qua. Khi output là 0 có nghĩa là không có thông tin nào, nếu là 1 thì có nghĩa cho tất cả các thông tin đi qua.

Loại gate - state |
Công thức |
Vai trò |
minh hoạ |
|---|---|---|---|
Forget gate \(f_t\) |
$\( f_t = \text{sigmoid}(W_f.[h_{t-1}, x_t] + b_f) \)$ |
Forget gate quyết định thông tin nào từ bộ nhớ dài hạn được lưu giữ hoặc loại bỏ |
|
Input gate \(i_t\) |
$\( i_t = \text{sigmoid}(W_i.[h_{t-1}, x_t] + b_i) \)$ |
Cổng đầu vào quyết định thông tin nào sẽ được lưu trữ trong bộ nhớ dài hạn. Nó chỉ hoạt động với thông tin từ đầu vào hiện tại và bộ nhớ ngắn hạn từ bước trước. Tại cổng này, nó lọc ra thông tin từ các biến không hữu ích |
|
Output gate (\(o_t\)) |
$\( o_t = \text{sigmoid}(W_o.[h_{t-1}, x_t] + b_o) \)$ |
Output gate sử dụng \(x_t\), \(h_{t-1}\) và long-term memory mới vừa được tính để tạo ra bộ lọc cho short-term memory \(h_t\) (để dùng trong next step) và cấu phần ra the cell state \(C_t\) (dùng trong step hiện tại) |
|
Hidden state (\(\tilde{C}_{t}\)) |
$\( \tilde{C}_{t} = \text{tanh}(W_c.[h_{t-1}, x_t] + b_c) \)$ |
Trạng thái ẩn tạm thời cấu phần ra the cell state \(C_t\) (dùng trong step hiện tại) |
|
Cell state (\(C_{t}\)) |
$\( C_{t} = f_t*C_{t-1} + i_t*\tilde{C}_{t} \)$ |
là bộ nhớ trong của LSTM được tổng hợp của bộ nhớ trước \(C_{t-1}\) đã được lọc qua forget gate \(f_t\) và trạng thái ẩn \(\tilde{C}_{t}\) đã được lọc qua Input gate \(i_t\), từ đó các thông tin quan trọng (long-term memory) sẽ được đi xa hơn và sẽ được dùng khi cần |
|
Short-term memory Output (\(h_{t}\)) |
$\( h_{t} = o_t*\text{tanh}({C}_{t}) \)$ |
Cell state \(C_{t}\) sau khi qua tanh activation sẽ được lọc 1 lần nữa qua Output gate \(o_t\) tạo ra output của step. |
|



Nếu nhìn kỹ một chút, ta có thể thấy RNN truyền thống là dạng đặc biệt của LSTM. Nếu thay giá trị đầu ra của input gate = 1 và đầu ra forget gate = 0 (không nhớ trạng thái trước)
LSTM có long-term memory. Tuy nhiên, LSTM khá giống với RNN truyền thống, tức có short-term memory. Nhìn chung, LSTM giải quyết phần nào vanishing gradient so với RNN, nhưng chỉ một phần.
Với lượng tính toán như trên, RNN đã chậm, LSTM nay còn chậm hơn.
Reference:
3.5.1.6.3. GRU#
Gated Recurrent Unit (GRU) là 1 TH đặc biệt của LSTM. GRU sử dụng less training parameter nên do đó sử dụng less memory and executes faster than LSTM trong khi đó LSTM is more accurate on a larger dataset.
LSTM if you are dealing with large sequences and accuracy is concerned
GRU is used when you have less memory consumption and want faster results.

GRU chỉ có 2 cổng: cổng thiết lập lại r và cổng cập nhập z. Cổng thiết lập lại sẽ quyết định cách kết hợp giữa đầu vào hiện tại với bộ nhớ trước, còn cổng cập nhập sẽ chỉ định có bao nhiêu thông tin về bộ nhớ trước nên giữa lại. Như vậy RNN thuần cũng là một dạng đặc biệt của GRU, với đầu ra của cổng thiết lập lại là 1 và cổng cập nhập là 0.
What is the difference between GRU & LSTM?
The GRU has 2 gates, LSTM has 3 gates
GRU không có bộ nhớ trong và output gate như LSTM
2 cổng vào và cổng quên được kết hợp lại thành cổng cập nhập z và cổng thiết lập lại r sẽ được áp dụng trực tiếp cho trạng thái ẩn trước.
GRU không sử dụng một hàm phi tuyến tính để tính đầu ra như LSTM
3.5.1.6.4. Bidirectional (BRNN)#
BRNN |
áp dụng |
minh hoạ |
|---|---|---|
BRNN khác RNN một điểm là thay vì process 1 sequense từ trái —> phải thì BRNN process 2 chiều (thêm cả từ phải —> trái) |
Việc phân tích câu cả 2 chiều có khả năng cải thiện performance tuy nhiên chi phí training và số lượng các tham số sẽ phải x2 |
|

3.5.1.6.5. Deep (DRNN)#
DRNN |
áp dụng |
minh hoạ |
|---|---|---|
DRNN |
DRNN |
|

3.5.1.6.6. Practice modelling#
# evaluation
from sklearn.metrics import (
classification_report,
accuracy_score,
precision_recall_fscore_support,
)
def get_performance(y_val, y_pred, model_name="baseline"):
print(classification_report(y_val, y_pred))
precision, recall, fscore, support = precision_recall_fscore_support(
y_val, y_pred
)
class_name = ["class0", "class1"]
df = pd.DataFrame(
[precision, recall, fscore],
columns=class_name,
index=["precision", "recall", "fscore"],
)
df.loc["accuracy"] = accuracy_score(y_val, y_pred)
df = df.reset_index().rename(columns={"index": "metric"})
df["model_name"] = model_name
return df
3.5.1.6.6.1. List models#
3.5.1.6.6.1.1. Model0: baseline model#
Sử dụng TF-IDF formula để convert words sang dạng numeric và model chúng bằng Multinomial Naive Bayes algorithm, model này thường được refering cho các model dữ liệu text
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
# create model pipeline
model_0 = Pipeline(
[
("tfidf", TfidfVectorizer()), # convert words to numbers using TF-IDF
("clf", MultinomialNB()), # model the text
]
)
# fit model
model_0.fit(x_train, y_train)
# evaluate our model
y_pred = model_0.predict(x_val)
model_0_res = get_performance(y_val, y_pred, model_name="0_baseline")
precision recall f1-score support
0 0.80 0.89 0.84 435
1 0.83 0.69 0.76 327
accuracy 0.81 762
macro avg 0.81 0.79 0.80 762
weighted avg 0.81 0.81 0.80 762
3.5.1.6.6.1.2. model1: simple dense#
Với dữ liệu đầu vào, ta thực hiện theo các bước
tokenization ---> embedding ---> average pooling ---> fully connected dence with sigmoid activation
from tensorflow import keras
def build_model(max_vocab_length, max_sequence_length):
# setup TextVectorization
tvect = layers.TextVectorization(
max_tokens=max_vocab_length,
output_sequence_length=max_sequence_length,
output_mode="int",
name="text_vectorization_1",
)
tvect.adapt(x_train)
# setup embedding layer
embedding = layers.Embedding(
input_dim=max_vocab_length, # set input shape
output_dim=128, # set size of embedding vector
embeddings_initializer="uniform", # default, intialize randomly
input_length=max_sequence_length, # how long is each input
name="embedding_1",
)
# create model
inputs = keras.layers.Input(shape=(1,), dtype="string")
x = tvect(inputs)
x = embedding(x)
x = keras.layers.GlobalAveragePooling1D()(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_1_dense")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
return model
model_1 = build_model(10000, 15)
model_1.summary()
Model: "model_1_dense"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 1)] 0
text_vectorization_1 (TextV (None, 15) 0
ectorization)
embedding_1 (Embedding) (None, 15, 128) 1280000
global_average_pooling1d (G (None, 128) 0
lobalAveragePooling1D)
dense_6 (Dense) (None, 1) 129
=================================================================
Total params: 1,280,129
Trainable params: 1,280,129
Non-trainable params: 0
_________________________________________________________________
from tqdm.keras import TqdmCallback
model_1_history = model_1.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
Epoch 1/5
215/215 [==============================] - 4s 17ms/step - loss: 0.6289 - accuracy: 0.6509 - val_loss: 0.5621 - val_accuracy: 0.7493
Epoch 2/5
215/215 [==============================] - 3s 13ms/step - loss: 0.4534 - accuracy: 0.8206 - val_loss: 0.4598 - val_accuracy: 0.7927
Epoch 3/5
215/215 [==============================] - 3s 12ms/step - loss: 0.3400 - accuracy: 0.8673 - val_loss: 0.4364 - val_accuracy: 0.8045
Epoch 4/5
215/215 [==============================] - 2s 11ms/step - loss: 0.2745 - accuracy: 0.8956 - val_loss: 0.4397 - val_accuracy: 0.7913
Epoch 5/5
215/215 [==============================] - 2s 11ms/step - loss: 0.2277 - accuracy: 0.9177 - val_loss: 0.4600 - val_accuracy: 0.7953
# prediction and evaluation
y_pred = model_1.predict(x_val).round().squeeze()
model_1_res = get_performance(y_val, y_pred, model_name="1_simple_dence")
24/24 [==============================] - 0s 3ms/step
precision recall f1-score support
0 0.79 0.87 0.83 435
1 0.80 0.69 0.74 327
accuracy 0.80 762
macro avg 0.80 0.78 0.79 762
weighted avg 0.80 0.80 0.79 762
# create embedding vector and metadata
import io
# Create output writers
out_v = io.open(
"Datasets/nlp_getting_started/embedding_vectors.tsv", "w", encoding="utf-8"
)
out_m = io.open(
"Datasets/nlp_getting_started/embedding_metadata.tsv",
"w",
encoding="utf-8",
)
# get vocab and embedding_weight from model
embed_weights = model_1.get_layer("embedding_1").get_weights()[0]
words_in_vocab = model_1.get_layer("text_vectorization_1").get_vocabulary()
# Write embedding vectors and words to file
for num, word in enumerate(words_in_vocab):
if num == 0:
continue # skip padding token
vec = embed_weights[num]
out_m.write(word + "\n") # write words to file
out_v.write(
"\t".join([str(x) for x in vec]) + "\n"
) # write corresponding word vector to file
out_v.close()
out_m.close()
3.5.1.6.6.1.3. model2: LSTM model#
tensorflow.keras.layers.LSTM()
Input (text) -> Tokenize -> Embedding -> Layers -> Output (label probability)
from tensorflow import keras
def build_lstm(max_vocab_length, max_sequence_length):
# setup TextVectorization
tvect = layers.TextVectorization(
max_tokens=max_vocab_length,
output_sequence_length=max_sequence_length,
output_mode="int",
name="text_vectorization_1",
)
tvect.adapt(x_train)
# setup embedding layer
embedding = layers.Embedding(
input_dim=max_vocab_length, # set input shape
output_dim=128, # set size of embedding vector
embeddings_initializer="uniform", # default, intialize randomly
input_length=max_sequence_length, # how long is each input
name="embedding_1",
)
# create model
inputs = keras.layers.Input(shape=(1,), dtype="string")
x = tvect(inputs)
x = embedding(x)
x = keras.layers.LSTM(64)(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_2_LSTM")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
return model
model_2 = build_lstm(10000, 15)
model_2.summary()
Model: "model_2_LSTM"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) [(None, 1)] 0
text_vectorization_1 (TextV (None, 15) 0
ectorization)
embedding_1 (Embedding) (None, 15, 128) 1280000
lstm (LSTM) (None, 64) 49408
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 1,329,473
Trainable params: 1,329,473
Non-trainable params: 0
_________________________________________________________________
model_2_history = model_2.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
Epoch 1/5
215/215 [==============================] - 10s 44ms/step - loss: 0.5158 - accuracy: 0.7396 - val_loss: 0.4424 - val_accuracy: 0.8071
Epoch 2/5
215/215 [==============================] - 4s 17ms/step - loss: 0.2985 - accuracy: 0.8824 - val_loss: 0.4780 - val_accuracy: 0.7835
Epoch 3/5
215/215 [==============================] - 4s 16ms/step - loss: 0.1931 - accuracy: 0.9295 - val_loss: 0.5891 - val_accuracy: 0.7559
Epoch 4/5
215/215 [==============================] - 3s 16ms/step - loss: 0.1324 - accuracy: 0.9486 - val_loss: 0.7432 - val_accuracy: 0.7835
Epoch 5/5
215/215 [==============================] - 3s 16ms/step - loss: 0.0908 - accuracy: 0.9631 - val_loss: 0.7791 - val_accuracy: 0.7598
# prediction and evaluation
y_pred = model_2.predict(x_val).round().squeeze()
model_2_res = get_performance(y_val, y_pred, model_name="2_lstm")
24/24 [==============================] - 0s 5ms/step
precision recall f1-score support
0 0.77 0.82 0.80 435
1 0.74 0.68 0.71 327
accuracy 0.76 762
macro avg 0.76 0.75 0.75 762
weighted avg 0.76 0.76 0.76 762
3.5.1.6.6.1.4. model3: GRU model#
Input (text) -> Tokenize -> Embedding -> Layers_GRU -> Output (label probability)
from tensorflow import keras
def build_gru(max_vocab_length, max_sequence_length):
# setup TextVectorization
tvect = layers.TextVectorization(
max_tokens=max_vocab_length,
output_sequence_length=max_sequence_length,
output_mode="int",
name="text_vectorization_1",
)
tvect.adapt(x_train)
# setup embedding layer
embedding = layers.Embedding(
input_dim=max_vocab_length, # set input shape
output_dim=128, # set size of embedding vector
embeddings_initializer="uniform", # default, intialize randomly
input_length=max_sequence_length, # how long is each input
name="embedding_1",
)
# create model
inputs = keras.layers.Input(shape=(1,), dtype="string")
x = tvect(inputs)
x = embedding(x)
x = keras.layers.GRU(64)(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_3_GRU")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
return model
model_3 = build_gru(10000, 15)
model_3.summary()
Model: "model_3_GRU"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_7 (InputLayer) [(None, 1)] 0
text_vectorization_1 (TextV (None, 15) 0
ectorization)
embedding_1 (Embedding) (None, 15, 128) 1280000
gru (GRU) (None, 64) 37248
dense_8 (Dense) (None, 1) 65
=================================================================
Total params: 1,317,313
Trainable params: 1,317,313
Non-trainable params: 0
_________________________________________________________________
model_3_history = model_3.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
Epoch 1/5
215/215 [==============================] - 6s 24ms/step - loss: 0.6505 - accuracy: 0.6179 - val_loss: 0.5060 - val_accuracy: 0.7690
Epoch 2/5
215/215 [==============================] - 4s 17ms/step - loss: 0.3814 - accuracy: 0.8348 - val_loss: 0.4461 - val_accuracy: 0.7979
Epoch 3/5
215/215 [==============================] - 3s 16ms/step - loss: 0.2317 - accuracy: 0.9066 - val_loss: 0.5470 - val_accuracy: 0.7848
Epoch 4/5
215/215 [==============================] - 3s 16ms/step - loss: 0.1470 - accuracy: 0.9448 - val_loss: 0.7074 - val_accuracy: 0.7520
Epoch 5/5
215/215 [==============================] - 3s 16ms/step - loss: 0.1061 - accuracy: 0.9594 - val_loss: 0.7763 - val_accuracy: 0.7559
# prediction and evaluation
y_pred = model_3.predict(x_val).round().squeeze()
model_3_res = get_performance(y_val, y_pred, model_name="3_GRU")
24/24 [==============================] - 0s 6ms/step
precision recall f1-score support
0 0.77 0.83 0.79 435
1 0.74 0.66 0.70 327
accuracy 0.76 762
macro avg 0.75 0.74 0.75 762
weighted avg 0.75 0.76 0.75 762
3.5.1.6.6.1.5. model4: Bidirectonal RNN#
tensorflow.keras.layers.Bidirectional là một cách tiếp cận training 2 chiều thay vì một chiều, do đó có thể wrap với bất kỳ layers nào nếu muốn training 2 chiều
from tensorflow import keras
def build_gru_bidir(max_vocab_length, max_sequence_length):
# setup TextVectorization
tvect = layers.TextVectorization(
max_tokens=max_vocab_length,
output_sequence_length=max_sequence_length,
output_mode="int",
name="text_vectorization_1",
)
tvect.adapt(x_train)
# setup embedding layer
embedding = layers.Embedding(
input_dim=max_vocab_length, # set input shape
output_dim=128, # set size of embedding vector
embeddings_initializer="uniform", # default, intialize randomly
input_length=max_sequence_length, # how long is each input
name="embedding_1",
)
# create model
inputs = keras.layers.Input(shape=(1,), dtype="string")
x = tvect(inputs)
x = embedding(x)
x = layers.Bidirectional(keras.layers.GRU(64))(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_4_GRU_bidir")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
return model
model_4 = build_gru(10000, 15)
# model_4.summary()
model_4_history = model_4.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
# prediction and evaluation
y_pred = model_4.predict(x_val).round().squeeze()
model_4_res = get_performance(y_val, y_pred, model_name="model_4_GRU_bidir")
Epoch 1/5
215/215 [==============================] - 6s 25ms/step - loss: 0.6467 - accuracy: 0.6189 - val_loss: 0.4780 - val_accuracy: 0.8005
Epoch 2/5
215/215 [==============================] - 4s 17ms/step - loss: 0.3829 - accuracy: 0.8339 - val_loss: 0.4440 - val_accuracy: 0.8031
Epoch 3/5
215/215 [==============================] - 3s 16ms/step - loss: 0.2445 - accuracy: 0.9053 - val_loss: 0.5274 - val_accuracy: 0.7992
Epoch 4/5
215/215 [==============================] - 3s 16ms/step - loss: 0.1554 - accuracy: 0.9441 - val_loss: 0.6703 - val_accuracy: 0.7546
Epoch 5/5
215/215 [==============================] - 3s 16ms/step - loss: 0.1085 - accuracy: 0.9609 - val_loss: 0.7498 - val_accuracy: 0.7690
24/24 [==============================] - 0s 6ms/step
precision recall f1-score support
0 0.78 0.83 0.80 435
1 0.75 0.69 0.72 327
accuracy 0.77 762
macro avg 0.77 0.76 0.76 762
weighted avg 0.77 0.77 0.77 762
3.5.1.6.6.1.6. model5: Convolutional NN for text#
Khi sử dụng Convolutional layers cho dữ liệu text (sequences) thì điểm khác biệt chính là số chiều sẽ là 1 (thay vì D = 2 khi sử lý dữ liệu dạng image)
Các bước chính trong viêc sử dụng CNN for text data: (chi tiết tại Understanding Convolutional Neural Networks for Text Classification)
Sử dụng
Conv1D()để filter bằng ngram detectors, mỗi 1 filter cụ thể sẽ tạo đặc điểm gần nhất với 1 họ ngrams
an ngram là 1 collection of n-words
Sử dụng Maxpooling trong suốt quá trình extracts những ngrams có liên quan để phục vụ việc ra quyét định
Model sẽ phân loại dựa trên các thông tin sau lớp maxpooling
from tensorflow import keras
def build_cnn_text(max_vocab_length, max_sequence_length):
# setup TextVectorization
tvect = layers.TextVectorization(
max_tokens=max_vocab_length,
output_sequence_length=max_sequence_length,
output_mode="int",
name="text_vectorization_1",
)
tvect.adapt(x_train)
# setup embedding layer
embedding = layers.Embedding(
input_dim=max_vocab_length, # set input shape
output_dim=128, # set size of embedding vector
embeddings_initializer="uniform", # default, intialize randomly
input_length=max_sequence_length, # how long is each input
name="embedding_1",
)
# create model
inputs = keras.layers.Input(shape=(1,), dtype="string")
x = tvect(inputs)
x = embedding(x)
x = layers.Conv1D(filters=32, kernel_size=5, activation="relu")(
x
) # sử dụng ngram với n = 5 words
x = layers.GlobalMaxPool1D()(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_5_Conv1D")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
return model
model_5 = build_cnn_text(10000, 15)
model_5.summary()
Model: "model_5_Conv1D"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_9 (InputLayer) [(None, 1)] 0
text_vectorization_1 (TextV (None, 15) 0
ectorization)
embedding_1 (Embedding) (None, 15, 128) 1280000
conv1d (Conv1D) (None, 11, 32) 20512
global_max_pooling1d (Globa (None, 32) 0
lMaxPooling1D)
dense_10 (Dense) (None, 1) 33
=================================================================
Total params: 1,300,545
Trainable params: 1,300,545
Non-trainable params: 0
_________________________________________________________________
model_5_history = model_5.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
Epoch 1/5
215/215 [==============================] - 5s 21ms/step - loss: 0.5586 - accuracy: 0.7254 - val_loss: 0.4585 - val_accuracy: 0.7913
Epoch 2/5
215/215 [==============================] - 3s 14ms/step - loss: 0.3250 - accuracy: 0.8678 - val_loss: 0.4647 - val_accuracy: 0.7940
Epoch 3/5
215/215 [==============================] - 3s 13ms/step - loss: 0.1881 - accuracy: 0.9355 - val_loss: 0.5576 - val_accuracy: 0.7940
Epoch 4/5
215/215 [==============================] - 3s 12ms/step - loss: 0.1173 - accuracy: 0.9581 - val_loss: 0.6164 - val_accuracy: 0.7927
Epoch 5/5
215/215 [==============================] - 3s 12ms/step - loss: 0.0837 - accuracy: 0.9699 - val_loss: 0.6956 - val_accuracy: 0.7703
# prediction and evaluation
y_pred = model_5.predict(x_val).round().squeeze()
model_5_res = get_performance(y_val, y_pred, model_name="5_Conv1D")
24/24 [==============================] - 0s 4ms/step
precision recall f1-score support
0 0.79 0.81 0.80 435
1 0.74 0.72 0.73 327
accuracy 0.77 762
macro avg 0.77 0.76 0.76 762
weighted avg 0.77 0.77 0.77 762
3.5.1.6.6.1.7. model6: TensorFlow Hub Pretrained Sentence Encoder#
the Universal Sentence Encoder embedding a whole sentence-level (thay vì word-level như layer Embedding phía trên), với mỗi sentence được encode thành vector có 512 dimentional
🔑 Note: An encoder is the name for a model which converts raw data such as text into a numerical representation (feature vector), a decoder converts the numerical representation to a desired output.
# Example of pretrained embedding with universal sentence encoder - https://tfhub.dev/google/universal-sentence-encoder/4
import tensorflow_hub as hub
import tensorflow as tf
def build_USE():
# We can use this encoding layer in place of our text_vectorizer and embedding layer
sentence_encoder_layer = hub.KerasLayer(
"https://tfhub.dev/google/universal-sentence-encoder/4",
input_shape=[], # shape of inputs coming to our model
dtype=tf.string, # data type of inputs coming to the USE layer
trainable=False, # keep the pretrained weights (we'll create a feature extractor)
name="USE",
)
# create model
inputs = tf.keras.layers.Input(shape=[], dtype="string")
x = sentence_encoder_layer(inputs)
x = keras.layers.Dense(64, activation="relu")(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_6_USE")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
return model
model_6 = build_USE()
model_6_history = model_6.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
# prediction and evaluation
y_pred = model_6.predict(x_val).round().squeeze()
model_6_res = get_performance(y_val, y_pred, model_name="model_6_USE")
Epoch 1/5
215/215 [==============================] - 20s 90ms/step - loss: 0.5124 - accuracy: 0.7719 - val_loss: 0.4251 - val_accuracy: 0.8058
Epoch 2/5
215/215 [==============================] - 12s 56ms/step - loss: 0.4283 - accuracy: 0.8067 - val_loss: 0.4156 - val_accuracy: 0.8071
Epoch 3/5
215/215 [==============================] - 11s 50ms/step - loss: 0.4179 - accuracy: 0.8129 - val_loss: 0.4206 - val_accuracy: 0.8097
Epoch 4/5
215/215 [==============================] - 10s 48ms/step - loss: 0.4103 - accuracy: 0.8161 - val_loss: 0.4189 - val_accuracy: 0.8123
Epoch 5/5
215/215 [==============================] - 10s 47ms/step - loss: 0.4049 - accuracy: 0.8196 - val_loss: 0.4201 - val_accuracy: 0.8045
24/24 [==============================] - 4s 155ms/step
precision recall f1-score support
0 0.83 0.82 0.83 435
1 0.77 0.78 0.77 327
accuracy 0.80 762
macro avg 0.80 0.80 0.80 762
weighted avg 0.80 0.80 0.80 762
3.5.1.6.6.1.8. model7: Transformers#
from tensorflow import keras
def build_tfm():
embedding = "https://tfhub.dev/google/nnlm-en-dim50/2"
hub_layer = hub.KerasLayer(
embedding, input_shape=[], dtype=tf.string, trainable=True
)
# create model
inputs = tf.keras.layers.Input(shape=[], dtype="string")
x = hub_layer(inputs)
x = keras.layers.Dense(64, activation="relu")(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs, name="model_7_Transformers")
model.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.legacy.Adam(),
metrics=["accuracy"],
)
print(model.summary())
return model
model_7 = build_tfm()
model_7_history = model_7.fit(
x_train, y_train, epochs=5, validation_data=(x_val, y_val), verbose=1
)
# prediction and evaluation
y_pred = model_7.predict(x_val).round().squeeze()
model_7_res = get_performance(y_val, y_pred, model_name="model_7_Transformers")
Model: "model_7_Transformers"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None,)] 0
keras_layer_3 (KerasLayer) (None, 50) 48190600
dense_4 (Dense) (None, 64) 3264
dense_5 (Dense) (None, 1) 65
=================================================================
Total params: 48,193,929
Trainable params: 48,193,929
Non-trainable params: 0
_________________________________________________________________
None
Epoch 1/5
215/215 [==============================] - 14s 63ms/step - loss: 0.5330 - accuracy: 0.7453 - val_loss: 0.4240 - val_accuracy: 0.8228
Epoch 2/5
215/215 [==============================] - 12s 58ms/step - loss: 0.3394 - accuracy: 0.8568 - val_loss: 0.4291 - val_accuracy: 0.8228
Epoch 3/5
215/215 [==============================] - 12s 58ms/step - loss: 0.2187 - accuracy: 0.9164 - val_loss: 0.5073 - val_accuracy: 0.7874
Epoch 4/5
215/215 [==============================] - 12s 58ms/step - loss: 0.1378 - accuracy: 0.9512 - val_loss: 0.6148 - val_accuracy: 0.7743
Epoch 5/5
215/215 [==============================] - 13s 58ms/step - loss: 0.0953 - accuracy: 0.9667 - val_loss: 0.6857 - val_accuracy: 0.7808
24/24 [==============================] - 0s 6ms/step
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[9], line 24
22 # prediction and evaluation
23 y_pred = model_7.predict(x_val).round().squeeze()
---> 24 model_7_res = get_performance(y_val, y_pred, model_name='model_7_Transformers')
NameError: name 'get_performance' is not defined
3.5.1.6.6.2. Compare performance#
import plotly.express as px
import pandas as pd
res = pd.concat(
[
model_0_res,
model_1_res,
model_2_res,
model_3_res,
model_4_res,
model_5_res,
model_6_res,
model_7_res,
]
)
fig = px.bar(
res,
y="class1",
x="model_name",
color="metric",
barmode="group",
range_y=(0.6, 1),
text_auto=".2f",
)
fig.update_traces(
textfont_size=12, textangle=0, textposition="outside", cliponaxis=False
)

3.5.1.6.6.3. Combining our models (model ensembling/stacking)#
ref: Chapter 6 of the Machine Learning Engineering Book
Sử dụng ensemble để kết hợp nhiều model để make prediction với điều kiện là các models có tính chất uncorrelated với nhau, hay nói cách khác là mỗi model có 1 cách tiếp cận/kiến trúc mạng khác nhau, cách tìm ra patterns khác nhau.
Các phương pháp combine output:
average the probabilities
Majority vote
Model stacking: sử dụng output của model này để làm input cho model khác
# average probability
3.5.1.6.6.4. Saving and loading a trained model#
# use H5 format
model_6.save("models/NLP/H5/model_6.h5")
# Load model with custom Hub Layer (required with HDF5 format)
# do model 6 sử dụng cấu trúc từ nguồn ngoài nên phải khai báo custom_objects
loaded_model_6 = tf.keras.models.load_model(
"models/NLP/H5/model_6.h5", custom_objects={"KerasLayer": hub.KerasLayer}
)
3.5.1.6.6.5. Finding the most wrong examples#
# Create dataframe with validation sentences and best performing model predictions
y_pred = model_6.predict(x_val)
val_df = pd.DataFrame(
{
"text": x_val,
"target": y_val,
"pred": y_pred.round().squeeze(),
"pred_prob": y_pred.squeeze(),
}
)
val_df.head()
24/24 [==============================] - 3s 107ms/step
| text | target | pred | pred_prob | |
|---|---|---|---|---|
| 3289 | make sure evacuate past fire doors questions y... | 0 | 0.0 | 0.474197 |
| 4221 | foodscare offersgo nestleindia slips loss magg... | 1 | 1.0 | 0.526637 |
| 4186 | phiddleface theres choking hazard dont die get | 0 | 0.0 | 0.062413 |
| 5873 | ruin life | 0 | 0.0 | 0.047390 |
| 706 | blazing elwoods blazingelwoods bother doug son... | 0 | 0.0 | 0.036600 |
# Find the wrong predictions and sort by prediction probabilities
most_wrong = val_df[val_df["target"] != val_df["pred"]].sort_values(
"pred_prob", ascending=False
)
most_wrong[:10]
| text | target | pred | pred_prob | |
|---|---|---|---|---|
| 2345 | general news uae demolition houses waterways b... | 0 | 1.0 | 0.921028 |
| 1491 | alaska wolves face catastrophe denali wolves p... | 0 | 1.0 | 0.913840 |
| 3991 | madonnamking rspca site multiple story high ri... | 0 | 1.0 | 0.907247 |
| 3821 | juneau empire first responders turn national n... | 0 | 1.0 | 0.894248 |
| 3506 | government concerned population explosion popu... | 0 | 1.0 | 0.891692 |
| 6070 | could die falling sinkhole still blamed | 0 | 1.0 | 0.872665 |
| 4832 | fredolsencruise please take faroeislands itine... | 0 | 1.0 | 0.852597 |
| 3111 | steveycheese mapmyrun electrocuted way round m... | 0 | 1.0 | 0.829169 |
| 3193 | plan emergency preparedness families children ... | 0 | 1.0 | 0.815358 |
| 2525 | nikostar lakes ohio thought abject desolation ... | 0 | 1.0 | 0.805084 |