3.6.5. Lang Chain#
Langchain version: 0.3.x
!pip install -qU "langchain[openai]"==0.3.22
3.6.5.1. Overview#
Langchain is a framework for developing applications powered by language models. It provides a standard interface for interacting with different LLMs, as well as tools for chaining together multiple components and simplifies every stage of LLM app lifecycle to create more complex applications:

Development: Build your applications using LangChain’s open-source components and third-party integrations. Use LangGraph to build stateful agents with first-class streaming and human-in-the-loop support.
Productionization: Use LangSmith to inspect, monitor and evaluate your applications, so that you can continuously optimize and deploy with confidence.
Deployment: Turn your LangGraph applications into production-ready APIs and Assistants with LangGraph Platform.
3.6.5.2. Key Features & Components#
1. THIRD-PARTY INTEGRATIONS:
LLMs: OpenAI, Hugging Face, Cohere, Anthropic, etc.
Document Loaders: CSV, JSON, HTML, PDF, etc.
Vector Stores: Pinecone, Weaviate, ChromaDB, etc.
2. CORE ELEMENTS:
Retrievers: Vector-based and keyword-based retrievers.
Chains: Sequential and parallel chains for combining multiple components.
Agents: Tools for building applications that can reason and act on their own, make decisions based on input (e.g. decide what task to perform next).
3. COMPONENTS:
Prompts and parsers:
Prompt Templates: Create dynamic prompts using templates.
Message: Define the content and role of messages exchanged between user and LLM.
Output Parsers: Parse and format the output from LLMs.
Example Selectors: Choose examples based on specific criteria.
Data processing:
Document Loaders: Load and preprocess documents from various sources.
Text Splitters: Split text into smaller chunks for processing.
Embeddings: Generate embeddings for text data.
Retrievers: Retrieve relevant documents based on queries.
Vector Stores: Store and manage embeddings for efficient retrieval.
Indexing: Create and manage indexes for efficient searching.
Chains & Agents:
Chat Models: LLMs exposed via a chat API that process sequences of messages as input and output a message.
Sequential Chains: Execute a series of steps in a specific order.
Memory: Keeps track of past conversations to maintain context.
Tools: implementation of the function to call by the agent.
Multimodal: Support for multiple input/output types (e.g. text, images).
Router Chains: Route input to different chains based on conditions.
Agent: Use LLMs to decide which tools to use and in what order.
Callbacks: Monitor workflows for debugging or analysis.
Additional features:
Serialization: Save and load components for reuse.
Customization: Extend and customize components for specific use cases.
3.6.5.2.1. Concept#
3.6.5.2.1.1. Message#
A message typically consists of the following pieces of information:
Role: The role of the message (e.g., “user”, “assistant”).
Content: The content of the message (e.g., text, multimodal data).
Additional metadata: id, name, token usage and other model-specific metadata.
1. Message role
Role |
Description |
|---|---|
system |
Used to tell the chat model how to behave and provide additional context. Not supported by all chat model providers. |
user |
Represents input from a user interacting with the model, usually in the form of text or other interactive input. |
assistant |
Represents a response from the model, which can include text or a request to invoke tools. |
tool |
A message used to pass the results of a tool invocation back to the model after external data or processing has been retrieved. Used with chat models that support tool calling. |
2. Message content
SystemMessage – for content which should be passed to direct the conversation
HumanMessage – for content in the input from the user.
AIMessage – for content in the response from the model.
AIMessageChunk – for content in the response from the model, but chunked into smaller pieces.
Multimodality – for more information on multimodal content.
OtherMessage:
ID: An optional unique identifier for the message.
Name: An optional name property which allows differentiate between different entities/speakers with the same role. Not all models support this!
Metadata: Additional information about the message, such as timestamps, token usage, etc.
Tool Calls: A request made by the model to call one or more tools> See tool calling for more information.
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
AIMessagePromptTemplate,
)
template = "You are a girl friend, cute and lovely."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
example_human = HumanMessagePromptTemplate.from_template("Hi")
example_ai = AIMessagePromptTemplate.from_template("Hello baby")
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, example_human, example_ai, human_message_prompt]
)
print(chat_prompt.invoke({"text": "I love you"}).to_string())
System: You are a girl friend, cute and lovely.
Human: Hi
AI: Hello baby
Human: I love you
3.6.5.2.2. Prompt & Parser#
# Streaming output
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-sonnet-20240229")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
parser = StrOutputParser()
chain = prompt | model | parser
async for event in chain.astream_events({"topic": "parrot"}):
kind = event["event"]
if kind == "on_chat_model_stream":
print(event, end="|", flush=True)
3.6.5.2.2.1. Prompt Templates#
Prompt templates help to translate user input and parameters into instructions for a language model. This can be used to guide a model’s response, helping it understand the context and generate relevant and coherent language-based output.
Take as input a dictionary, where each key represents a variable in the prompt template to fill in.
Get output a PromptValue. This PromptValue can be passed to an LLM or a ChatModel, and can also be cast to a string or a list of messages. The reason this PromptValue exists is to make it easy to switch between strings and messages.
String PromptTemplates
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"})
StringPromptValue(text='Tell me a joke about cats')
ChatPromptTemplates: Cấu trúc cho các mẫu hội thoại, bao gồm các thành phần như:
SystemMessagePromptTemplate: message template cho các thông điệp hệ thống.
HumanMessagePromptTemplate: message template cho các query của người dùng.
AIMessagePromptTemplate: message template cho các phản hồi của AI.
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate(
[
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}"),
]
)
prompt_template.invoke({"topic": "cats"})
ChatPromptValue(messages=[SystemMessage(content='You are a helpful assistant', additional_kwargs={}, response_metadata={}), HumanMessage(content='Tell me a joke about cats', additional_kwargs={}, response_metadata={})])
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
AIMessagePromptTemplate,
)
template = "You are a girl friend, cute and lovely."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
example_human = HumanMessagePromptTemplate.from_template("Hi")
example_ai = AIMessagePromptTemplate.from_template("Hello baby")
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, example_human, example_ai, human_message_prompt]
)
chat_prompt.invoke({"text": "I love you"})
ChatPromptValue(messages=[SystemMessage(content='You are a girl friend, cute and lovely.', additional_kwargs={}, response_metadata={}), HumanMessage(content='Hi', additional_kwargs={}, response_metadata={}), AIMessage(content='Hello baby', additional_kwargs={}, response_metadata={}), HumanMessage(content='I love you', additional_kwargs={}, response_metadata={})])
Kết hợp với FewShotPromptTemplate: Tạo các mẫu đầu vào cho các mô hình học sâu bằng cách sử dụng một số ví dụ cụ thể để hướng dẫn mô hình trong việc tạo ra đầu ra mong muốn.
from langchain import PromptTemplate, FewShotPromptTemplate
# create our examples
examples = [
{
"query": "Giờ có nên đi học thêm không?",
"answer": "Học hành như cá kho tiêu, Kho nhiều thì mặn, học nhiều thì ngu.!",
},
{
"query": "Em có yêu anh không?",
"answer": "Hôm nay em bận yêu đời, Hẹn anh hôm khác chúng mình yêu nhau..",
},
]
# create an example template
example_template = """
User: {query}
AI: {answer}
"""
# create a prompt example from above template
example_prompt = PromptTemplate(
input_variables=["query", "answer"], template=example_template
)
# now break our previous prompt into a prefix and suffix
# the prefix is our instructions
prefix = """The following are excerpts from conversations with an AI
assistant. The assistant is known for its humor and wit, providing
entertaining and amusing responses to users' questions. Here are some
examples:
"""
# and the suffix our user input and output indicator
suffix = """
User: {query}
AI: """
# now create the few-shot prompt template
few_shot_prompt_template = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["query"],
example_separator="\n",
)
print(
few_shot_prompt_template.invoke(
{"query": "Em có yêu anh không?"}
).to_string()
)
The following are excerpts from conversations with an AI
assistant. The assistant is known for its humor and wit, providing
entertaining and amusing responses to users' questions. Here are some
examples:
User: Giờ có nên đi học thêm không?
AI: Học hành như cá kho tiêu, Kho nhiều thì mặn, học nhiều thì ngu.!
User: Em có yêu anh không?
AI: Hôm nay em bận yêu đời, Hẹn anh hôm khác chúng mình yêu nhau..
User: Em có yêu anh không?
AI:
3.6.5.2.2.2. Example Selectors#
This object selects examples based on similarity to the inputs. It does this by finding the examples with the embeddings that have the greatest cosine similarity with the inputs.
!pip install -qU "langchain-chroma>=0.1.2"
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
load_dotenv(r"contents\theory\aiml_algorithms\dl_llm\.env")
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
example_selector = SemanticSimilarityExampleSelector.from_examples(
# The list of examples available to select from.
examples,
# The embedding class used to produce embeddings which are used to measure semantic similarity.
embedding_model,
# The VectorStore class that is used to store the embeddings and do a similarity search over.
Chroma,
# The number of examples to produce.
k=1,
)
similar_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
# Input is a feeling, so should select the happy/sad example
print(similar_prompt.format(adjective="worried"))
Give the antonym of every input
Input: happy
Output: sad
Input: worried
Output:
# Input is a measurement, so should select the tall/short example
print(similar_prompt.format(adjective="large"))
Give the antonym of every input
Input: tall
Output: short
Input: large
Output:
# You can add new examples to the SemanticSimilarityExampleSelector as well
similar_prompt.example_selector.add_example(
{"input": "enthusiastic", "output": "apathetic"}
)
print(similar_prompt.format(adjective="passionate"))
Give the antonym of every input
Input: enthusiastic
Output: apathetic
Input: passionate
Output:
3.6.5.2.2.3. Output Parsers#
Name |
Supports Streaming |
Has Format Instructions |
Calls LLM |
Output Type |
Description |
|---|---|---|---|---|---|
✅ |
String |
Parses texts from message objects. Useful for handling variable formats of message content (e.g., extracting text from content blocks). |
|||
✅ |
✅ |
JSON object |
Returns a JSON object as specified. You can specify a Pydantic model and it will return JSON for that model. Probably the most reliable output parser for getting structured data that does NOT use function calling. |
||
✅ |
✅ |
|
Returns a dictionary of tags. Use when XML output is needed. Use with models that are good at writing XML (like Anthropic’s). |
||
✅ |
✅ |
|
Returns a list of comma separated values. |
||
✅ |
Wraps another output parser. If that output parser errors, then this will pass the error message and the bad output to an LLM and ask it to fix the output. |
||||
✅ |
Wraps another output parser. If that output parser errors, then this will pass the original inputs, the bad output, and the error message to an LLM and ask it to fix it. Compared to OutputFixingParser, this one also sends the original instructions. |
||||
✅ |
|
Takes a user defined Pydantic model and returns data in that format. |
|||
✅ |
|
Takes a user defined Pydantic model and returns data in that format. Uses YAML to encode it. |
|||
✅ |
|
Useful for doing operations with pandas DataFrames. |
|||
✅ |
|
Parses response into one of the provided enum values. |
|||
✅ |
|
Parses response into a datetime string. |
|||
✅ |
|
An output parser that returns structured information. It is less powerful than other output parsers since it only allows for fields to be strings. This can be useful when you are working with smaller LLMs. |
3.6.5.2.2.3.1. Config output structure#
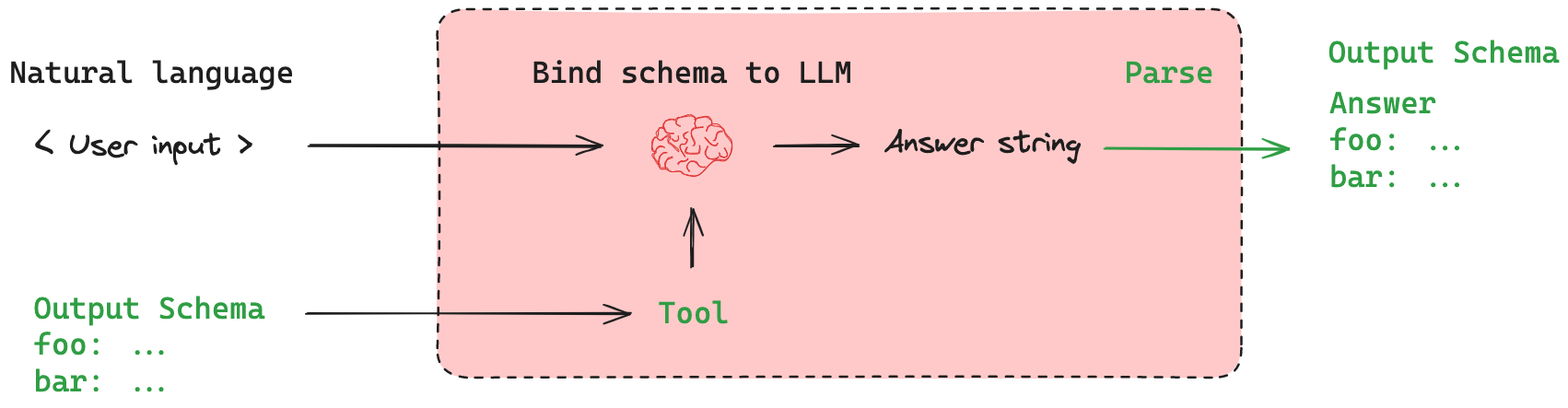
Non-structured output
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
ai_msg = model.invoke(
"Return a JSON object with key 'random_ints' and a value of 10 random ints in [0-99]"
)
ai_msg
AIMessage(content='Here is a JSON object containing a key `\'random_ints\'` with a value of 10 random integers in the range of 0 to 99:\n\n```json\n{\n "random_ints": [12, 45, 67, 23, 89, 34, 76, 54, 1, 99]\n}\n```\n\n(Note: The numbers are randomly chosen for this example; you can generate different sets of random integers as needed.)', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 98, 'prompt_tokens': 32, 'total_tokens': 130, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_b376dfbbd5', 'id': 'chatcmpl-BI9vI5ru9yr9IqrjTHTYP4AtPetCE', 'finish_reason': 'stop', 'logprobs': None}, id='run-1cd09edf-308a-4bbf-9dca-00ef1ddc1538-0', usage_metadata={'input_tokens': 32, 'output_tokens': 98, 'total_tokens': 130, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})
Structured output: The output is structured in a way that can be easily parsed and understood by the system. This is typically done using a specific format, such as JSON or XML, which allows for easy extraction of relevant information.
model_json_output = ChatOpenAI(model="gpt-4o-mini").with_structured_output(
method="json_mode"
)
ai_msg = model_json_output.invoke(
"Return a JSON object with key 'random_ints' and a value of 10 random ints in [0-99]"
)
ai_msg
{'random_ints': [23, 47, 58, 12, 74, 33, 91, 6, 85, 39]}
Structured output with pydantic Class
from pydantic import BaseModel, Field
class ModelOutput(BaseModel):
random_ints: list[int] = Field(description="List of random integers")
model = ChatOpenAI(model="gpt-4o-mini").with_structured_output(ModelOutput)
ai_msg = model.invoke(
"Return a JSON object with key 'random_ints' and a value of 10 random ints in [0-99]"
)
ai_msg
ModelOutput(random_ints=[5, 12, 36, 58, 73, 84, 27, 44, 90, 11])
from pydantic import BaseModel, Field
class ModelOutput(BaseModel):
random_ints: list[int] = Field(description="List of random integers")
model = ChatOpenAI(model="gpt-4o-mini").bind_tools([ModelOutput])
ai_msg = model.invoke(
"Return a JSON object with key 'random_ints' and a value of 10 random ints in [0-99]"
)
ai_msg.tool_calls[0]["args"]
{'random_ints': [80, 29, 63, 76, 8, 72, 11, 54, 58, 24]}
3.6.5.2.2.3.2. Pydantic Output Parser#
Nhận kết quả từ một mô hình ngôn ngữ và phân tích cú pháp nó thành một đối tượng Pydantic. Điều này cho phép bạn dễ dàng làm việc với đầu ra có cấu trúc và đảm bảo rằng nó tuân theo các quy tắc xác thực đã định nghĩa trước đó.
from langchain_openai import ChatOpenAI
from langchain import LLMChain
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, field_validator
from typing import List
model_name = "gpt-4o-mini"
temperature = 0.0
model = ChatOpenAI(model="gpt-4o-mini")
class Suggestions(BaseModel):
words: List[str] = Field(
description="list of substitue words based on context"
)
# Throw error in case of recieving a numbered-list from API
@field_validator("words")
def not_start_with_number(cls, field):
if field[0].isnumeric():
raise ValueError("The word can not start with numbers!")
return field
parser = PydanticOutputParser(pydantic_object=Suggestions)
template = """
Offer a list of suggestions to substitue the specified target_word based the presented context.
{format_instructions}
target_word={target_word}
context={context}
"""
target_word = "behaviour"
context = "The behaviour of the students in the classroom was disruptive and made it difficult for the teacher to conduct the lesson."
prompt_template = PromptTemplate(
template=template,
input_variables=["target_word", "context"],
partial_variables={
"format_instructions": parser.get_format_instructions()
},
)
chain = prompt_template | model | parser
result = chain.invoke(
{
"target_word": target_word,
"context": context,
}
)
result
Suggestions(words=['conduct', 'manner', 'conductivity', 'actions', 'performance', 'attitude', 'response', 'approach'])
3.6.5.2.2.3.3. Comma Separated List Output Parser#
Phân tích cú pháp đầu ra thành danh sách các mục được phân tách bằng dấu phẩy. Điều này hữu ích khi bạn muốn lấy một danh sách các mục từ đầu ra của mô hình ngôn ngữ mà không cần phải xử lý cú pháp phức tạp.
Similar: DatetimeOutputParser
from langchain_core.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
template = """
Offer a list of suggestions to substitue the word '{target_word}' based the presented the following text: {context}.
{format_instructions}
"""
prompt_template = PromptTemplate(
template=template,
input_variables=["target_word", "context"],
partial_variables={"format_instructions": format_instructions},
)
chain = prompt_template | model | output_parser
result = chain.invoke(
{
"target_word": target_word,
"context": context,
}
)
result
['conduct',
'demeanor',
'actions',
'conduct',
'habits',
'performance',
'attitude',
'demeanor',
'responses',
'approach']
3.6.5.2.2.3.4. Output Fixing Parser#
Wraps another output parser, and in the event that the first one fails it calls out to another LLM to fix any errors. This is useful when you want to ensure that the output is always valid, even if the first parser fails. The second LLM can be used to correct any mistakes or provide additional context to the output.
from typing import List
from langchain.output_parsers import OutputFixingParser
from langchain_core.exceptions import OutputParserException
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
class Actor(BaseModel):
name: str = Field(description="name of an actor")
film_names: List[str] = Field(
description="list of names of films they starred in"
)
model = ChatOpenAI(model="gpt-4o-mini")
parser = PydanticOutputParser(pydantic_object=Actor)
new_parser = OutputFixingParser.from_llm(
parser=parser, llm=ChatOpenAI(model="gpt-4o-mini")
)
prompt_template = PromptTemplate(
template="Tạo ngẫu nhiên 1 bộ phim do một diễn viên đóng.",
input_variables=[],
)
chain = prompt_template | model
output = chain.invoke({})
try:
parser.invoke(output.content)
except OutputParserException as e:
print(e)
print("======= Fixing =======")
print(new_parser.invoke(output.content))
Invalid json output: Tên phim: **"Ánh Sáng Cuối Cùng"**
Diễn viên chính: **Trần Minh Hòa**
Nội dung: Bộ phim xoay quanh câu chuyện của một nhà báo điều tra, Minh Hòa, người phát hiện ra một âm mưu lớn đằng sau cái chết của một nhà hoạt động nhân quyền nổi tiếng. Trong hành trình tìm kiếm sự thật, anh phải đối mặt với những thế lực mạnh mẽ đang cố gắng ngăn cản anh. Bộ phim không chỉ nói về cuộc chiến giữa ánh sáng và bóng tối mà còn khai thác sâu sắc những khía cạnh của lòng dũng cảm và sự hy sinh.
Địa điểm quay: Các địa danh nổi tiếng tại Việt Nam như Hà Nội, Đà Nẵng và TP. Hồ Chí Minh.
Thể loại: Hành động, Chính trị, Tâm lý.
Điểm nhấn: Trần Minh Hòa mang đến một màn trình diễn xuất sắc, thể hiện sự quyết tâm và những giằng xé nội tâm của nhân vật trong bối cảnh đầy căng thẳng và hồi hộp.
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
======= Fixing =======
name='Trần Minh Hòa' film_names=['Ánh Sáng Cuối Cùng']
3.6.5.2.2.3.5. Retry Output Parser#
Áp dụng cho các trường hợp mà đầu ra của mô hình ngôn ngữ có thể không chính xác hoặc không đầy đủ. Nếu đầu ra không đạt yêu cầu, nó sẽ gọi lại mô hình ngôn ngữ với các thông tin bổ sung để cải thiện kết quả bằng cách gửi lại yêu cầu với thông tin lỗi và đầu ra ban đầu để mô hình ngôn ngữ có thể sửa lỗi và cung cấp một kết quả chính xác hơn.
Trường hợp Output Fixing Parser không giải quyết được, mà phải cần Retry Output Parser:
Khi đầu ra của mô hình ngôn ngữ không chỉ đơn giản là một lỗi cú pháp mà còn liên quan đến việc hiểu sai ngữ cảnh hoặc yêu cầu.
Thiếu thông tin: Nếu đầu ra chỉ chứa một phần thông tin cần thiết,
Output Fixing Parsersẽ không biết cách bổ sung thông tin còn thiếu.
Trong trường hợp này, Retry Output Parser sẽ gửi lại yêu cầu với thông tin lỗi và đầu ra ban đầu để mô hình ngôn ngữ có thể cung cấp thông tin đầy đủ hơn.
from langchain import PromptTemplate
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser, RetryOutputParser
from pydantic import BaseModel
# Định nghĩa mô hình dữ liệu cho thông tin phòng
class RoomInfo(BaseModel):
room_type: str = Field(description="Loại phòng")
available: bool = Field(description="Có phòng trống không")
# Tạo parser cho thông tin phòng
parser = PydanticOutputParser(pydantic_object=RoomInfo)
template = """
Tôi muốn đặt một {room_type} tại {location} vào ngày {date}. Có phòng trống không?
{format_instructions}
"""
# Tạo template cho yêu cầu đặt phòng
prompt_template = PromptTemplate(
template=template,
input_variables=["room_type", "location", "date"],
partial_variables={
"format_instructions": parser.get_format_instructions()
},
)
# Tạo chuỗi để lấy đầu ra từ mô hình ngôn ngữ
completion_chain = prompt_template | ChatOpenAI(
model="gpt-4o-mini", temperature=0
)
# Thực hiện chuỗi
result_1 = completion_chain.invoke(
{
"room_type": "phòng đơn",
"location": "Hà Nội",
"date": "15 tháng 4 năm 2024",
}
)
parser.parse(result_1.content) # Kết quả đầu ra từ mô hình ngôn ngữ
RoomInfo(room_type='phòng đơn', available=True)
# Tạo Retry Output Parser
retry_parser = RetryOutputParser.from_llm(
parser=parser, llm=ChatOpenAI(model="gpt-4o-mini", temperature=0)
)
retry_parser.parse_with_prompt(result_1.content, prompt_template)
RoomInfo(room_type='phòng đơn', available=True)
3.6.5.2.3. Data Processing#
3.6.5.2.3.1. Document Loaders#
Detail up-to-date: Document Loaders
3.6.5.2.3.1.1. PDF#
%pip install -qU pypdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path)
pages = []
async for page in loader.alazy_load():
pages.append(page)
Vector search over PDFs in memory
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
vector_store = InMemoryVectorStore.from_documents(pages, OpenAIEmbeddings())
docs = vector_store.similarity_search("What is LayoutParser?", k=2)
for doc in docs:
print(f"Page {doc.metadata['page']}: {doc.page_content[:300]}\n")
3.6.5.2.3.1.2. Webpage#
2 types of web page loaders:
Simple and fast parsing: in which we recover one Document per web page with its content represented as a “flattened” string;
%pip install -qU langchain-community beautifulsoup4
Note: you may need to restart the kernel to use updated packages.
# parse all text of web page, contain extraneous information like headings, navigation,...
import bs4
from langchain_community.document_loaders import WebBaseLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = WebBaseLoader(web_paths=[page_url])
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
assert len(docs) == 1
doc = docs[0]
print(f"{doc.metadata}\n")
print(doc.page_content[:500].strip())
{'source': 'https://python.langchain.com/docs/how_to/chatbots_memory/', 'title': 'How to add memory to chatbots | 🦜️🔗 LangChain', 'description': 'A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:', 'language': 'en'}
How to add memory to chatbots | 🦜️🔗 LangChain
Skip to main contentJoin us at Interrupt: The Agent AI Conference by LangChain on May 13 & 14 in San Francisco!IntegrationsAPI ReferenceMoreContributingPeopleError referenceLangSmithLangGraphLangChain HubLangChain JS/TSv0.3v0.3v0.2v0.1💬SearchIntroductionTutorialsBuild a Question Answering application over a Graph DatabaseTutorialsBuild a simple LLM application with chat models and prompt templatesBuild a ChatbotBuild a Retrieval Augmented
# parse only content of article
loader = WebBaseLoader(
web_paths=[page_url],
bs_kwargs={
"parse_only": bs4.SoupStrainer(class_="theme-doc-markdown markdown"),
},
bs_get_text_kwargs={"separator": " | ", "strip": True},
)
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
assert len(docs) == 1
doc = docs[0]
print(f"{doc.metadata}\n")
print(doc.page_content[:500])
{'source': 'https://python.langchain.com/docs/how_to/chatbots_memory/'}
How to add memory to chatbots | A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including: | Simply stuffing previous messages into a chat model prompt. | The above, but trimming old messages to reduce the amount of distracting information the model has to deal with. | More complex modifications like synthesizing summaries for long running conversations. | We'll go into more detail on a few t
Advanced parsing: in which we recover multiple Document objects per page, allowing one to identify and traverse sections, links, tables, and other structures.
from langchain_unstructured import UnstructuredLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = UnstructuredLoader(web_url=page_url)
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
for doc in docs[:5]:
print(doc.page_content)
Open In Colab
Open on GitHub
How to add memory to chatbots
A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:
Simply stuffing previous messages into a chat model prompt.
# Extracting content from specific sections
for doc in docs[:5]:
print(f"{doc.metadata['category']}: {doc.page_content}")
Image: Open In Colab
Image: Open on GitHub
Title: How to add memory to chatbots
NarrativeText: A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:
ListItem: Simply stuffing previous messages into a chat model prompt.
Multi webpage setup
from typing import List
from collections import defaultdict
from langchain_core.documents import Document
async def _get_setup_docs_from_url(url: str) -> List[Document]:
loader = UnstructuredLoader(web_url=url)
setup_docs = []
parent_id = -1
async for doc in loader.alazy_load():
if doc.metadata["category"] == "Title" and doc.page_content.startswith(
"Setup"
):
parent_id = doc.metadata["element_id"]
if doc.metadata.get("parent_id") == parent_id:
setup_docs.append(doc)
return setup_docs
page_urls = [
"https://python.langchain.com/docs/how_to/chatbots_memory/",
"https://python.langchain.com/docs/how_to/chatbots_tools/",
]
setup_docs = []
for url in page_urls:
page_setup_docs = await _get_setup_docs_from_url(url)
setup_docs.extend(page_setup_docs)
setup_text = defaultdict(str)
for doc in setup_docs:
url = doc.metadata["url"]
setup_text[url] += f"{doc.page_content}\n"
dict(setup_text)
{'https://python.langchain.com/docs/how_to/chatbots_memory/': 'You\'ll need to install a few packages, and have your OpenAI API key set as an environment variable named OPENAI_API_KEY:\n%pip install --upgrade --quiet langchain langchain-openai langgraph\n\nimport getpass\nimport os\n\nif not os.environ.get("OPENAI_API_KEY"):\n os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")\nOpenAI API Key: ········\nLet\'s also set up a chat model that we\'ll use for the below examples.\nfrom langchain_openai import ChatOpenAI\n\nmodel = ChatOpenAI(model="gpt-4o-mini")\nAPI Reference:ChatOpenAI\n',
'https://python.langchain.com/docs/how_to/chatbots_tools/': 'For this guide, we\'ll be using a tool calling agent with a single tool for searching the web. The default will be powered by Tavily, but you can switch it out for any similar tool. The rest of this section will assume you\'re using Tavily.\nYou\'ll need to sign up for an account on the Tavily website, and install the following packages:\n%pip install --upgrade --quiet langchain-community langchain-openai tavily-python langgraph\n\nimport getpass\nimport os\n\nif not os.environ.get("OPENAI_API_KEY"):\n os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")\n\nif not os.environ.get("TAVILY_API_KEY"):\n os.environ["TAVILY_API_KEY"] = getpass.getpass("Tavily API Key:")\nOpenAI API Key: ········\nTavily API Key: ········\nYou will also need your OpenAI key set as OPENAI_API_KEY and your Tavily API key set as TAVILY_API_KEY.\n'}
Vector search over page content
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
load_dotenv(r"contents\theory\aiml_algorithms\dl_llm\.env")
vector_store = InMemoryVectorStore.from_documents(
setup_docs, OpenAIEmbeddings()
)
retrieved_docs = vector_store.similarity_search("Install Tavily", k=2)
for doc in retrieved_docs:
print(f"Page {doc.metadata['url']}: {doc.page_content[:300]}\n")
Page https://python.langchain.com/docs/how_to/chatbots_tools/: You'll need to sign up for an account on the Tavily website, and install the following packages:
Page https://python.langchain.com/docs/how_to/chatbots_tools/: For this guide, we'll be using a tool calling agent with a single tool for searching the web. The default will be powered by Tavily, but you can switch it out for any similar tool. The rest of this section will assume you're using Tavily.
3.6.5.2.3.1.3. CSV#
3.6.5.2.3.1.4. Custom loader#
3.6.5.2.3.2. Text Splitters#
Lý do chính cần sử dụng Text Splitters này:
Xử lý văn bản không đồng đều: Văn bản trong thế giới thực thường có độ dài khác nhau. Việc chia văn bản giúp đảm bảo rằng tất cả văn bản được xử lý một cách nhất quán.
Vượt qua giới hạn kích thước đầu vào của mô hình: Nhiều mô hình ngôn ngữ và mô hình nhúng có giới hạn về kích thước đầu vào. Chia văn bản cho phép xử lý các văn bản vượt quá giới hạn này.
Cải thiện chất lượng biểu diễn: Đối với văn bản dài, chất lượng biểu diễn (như nhúng) có thể giảm do phải nắm bắt quá nhiều thông tin. Chia văn bản giúp tạo ra biểu diễn tập trung và chính xác hơn cho từng phần.
Tối ưu hóa tài nguyên tính toán: Làm việc với các phần nhỏ hơn giúp tiết kiệm bộ nhớ và cho phép song song hóa các nhiệm vụ xử lý tốt hơn.
Cải thiện độ chính xác của tìm kiếm: Trong hệ thống tìm kiếm, chia văn bản giúp tăng độ chính xác của kết quả tìm kiếm bằng cách cho phép tìm kiếm chính xác hơn trong từng phần của văn bản.
3.6.5.2.3.2.1. Chia theo Length-based#
Phương pháp chia văn bản dựa trên Length-based là một cách tiếp cận trực quan và hiệu quả. Ưu điểm của phương pháp này bao gồm:
Triển khai đơn giản: Dễ dàng thực hiện.
Kích thước đoạn văn nhất quán: Mỗi phần đều có kích thước tương tự.
Dễ dàng thích nghi với yêu cầu của mô hình khác nhau.
Có hai loại chia văn bản dựa trên độ dài:
Dựa trên token: Chia văn bản dựa trên số lượng token, phù hợp khi làm việc với mô hình ngôn ngữ.
Dựa trên ký tự: Chia văn bản dựa trên số lượng ký tự, mang lại sự nhất quán cao hơn trên các loại văn bản khác nhau
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(document)
3.6.5.2.3.2.2. Chia theo Text-structured based#
Văn bản tự nhiên được tổ chức thành các đơn vị phân cấp như đoạn văn, câu và từ. Chúng ta có thể tận dụng cấu trúc này để thông tin cho chiến lược chia văn bản, tạo ra các phần chia mà vẫn giữ được dòng chảy ngôn ngữ tự nhiên và sự mạch lạc ngữ nghĩa trong mỗi phần chia. LangChain cung cấp công cụ RecursiveCharacterTextSplitter để thực hiện điều này:
Giữ nguyên các đơn vị lớn hơn (ví dụ: đoạn văn) nếu có thể.
Chia nhỏ hơn (ví dụ: câu) nếu đơn vị lớn hơn vượt quá kích thước phần chia.
Tiếp tục quy trình này cho đến khi đạt đến mức từ nếu cần thiết.
Phương pháp này giúp duy trì sự mạch lạc ngữ nghĩa và dòng chảy ngôn ngữ tự nhiên trong văn bản sau khi chia.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(document)
3.6.5.2.3.2.3. Document-structured based#
Một số tài liệu như HTML, Markdown hoặc JSON có cấu trúc nội tại. Việc chia tài liệu dựa trên cấu trúc này có lợi vì nó thường nhóm các văn bản liên quan về mặt ngữ nghĩa lại với nhau. Ưu điểm của phương pháp chia dựa trên cấu trúc bao gồm:
Bảo tồn tổ chức logic của tài liệu.
Duy trì ngữ cảnh trong mỗi phần chia.
Có thể hiệu quả hơn cho các nhiệm vụ tiếp theo như tìm kiếm hoặc tóm tắt.
Ví dụ về chia dựa trên cấu trúc:
Markdown: Chia dựa trên tiêu đề (ví dụ:
#,##,###).HTML: Chia sử dụng thẻ.
JSON: Chia theo các phần tử đối tượng hoặc mảng.
Source code: Chia theo hàm, lớp hoặc khối logic.
3.6.5.2.3.2.4. Semantic-based#
Chia văn bản theo ngữ nghĩa khác biệt với các phương pháp trước vì nó trực tiếp phân tích nội dung văn bản thay vì dựa vào cấu trúc hay độ dài. Cách tiếp cận này xác định điểm chia dựa trên sự thay đổi đáng kể về ý nghĩa trong văn bản.
Cách triển khai điển hình:
Sử dụng cửa sổ trượt để tạo embedding (biểu diễn vector) cho từng nhóm câu.
So sánh các embedding liên tiếp để phát hiện khác biệt ngữ nghĩa lớn.
Chọn các điểm khác biệt này làm ranh giới giữa các phần văn bản.
Ưu điểm chính:
Tạo ra các đoạn văn bản mạch lạc về mặt ngữ nghĩa.
Cải thiện hiệu quả cho các tác vụ như tìm kiếm thông tin hoặc tóm tắt.
Phù hợp với văn bản không có cấu trúc rõ ràng.
Phương pháp này đòi hỏi tính toán phức tạp hơn nhưng mang lại kết quả tối ưu khi xử lý các văn bản đa nghĩa hoặc chuyên sâu.
3.6.5.2.3.3. Embeddings#
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!",
]
)
len(embeddings), len(embeddings[0])
(5, 1536)
# embed a single text
query_embedding = embeddings_model.embed_query("What is the meaning of life?")
len(query_embedding)
1536
3.6.5.2.3.4. Vector Stores#
A vector store stores embedded data and performs similarity search.
Please see the full list of LangChain vectorstore integrations.
Cosine Similarity: Measures the cosine of the angle between two vectors.
Euclidean Distance: Measures the straight-line distance between two points.
Dot Product: Measures the projection of one vector onto another.
Hybrid search: Hybrid search combines keyword and semantic similarity, marrying the benefits of both approaches.
Maximal Marginal Relevance (MMR): When needing to diversify search results, MMR attempts to diversify the results of a search to avoid returning similar and redundant documents.
Initialization
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
from langchain_core.vectorstores import InMemoryVectorStore
# Initialize with an embedding model
vector_store = InMemoryVectorStore(embedding=embeddings)
Adding documents
from langchain_core.documents import Document
document_1 = Document(
page_content="I had chocalate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
document_3 = Document(
page_content="The movie was a thrilling adventure with stunning visual effects and a captivating storyline.",
metadata={"source": "news"},
)
document_4 = Document(
page_content="I love to watch romantic movie on the weekends.",
metadata={"source": "tweet"},
)
document_5 = Document(
page_content="This film was a heartwarming tale of love and friendship",
metadata={"source": "tweet"},
)
documents = [document_1, document_2, document_3, document_4, document_5]
vector_store.add_documents(documents=documents)
['599fd76e-e86a-4c2e-a5d1-21a452728fd4',
'532721ed-1f85-43e4-bd42-b0e98fe839eb',
'91b2e127-f0da-40a2-867f-2b66306f9eb5',
'f44187f6-7d10-4458-84d5-e1cd70a5ddf0',
'2d8538f7-4dee-4029-b0f3-f3cd970791d9']
Deleting documents
vector_store.delete(ids=["c98a069c-be15-4091-8226-6e6e2b7070d4"])
len(vector_store.store)
5
Search documents
query = "movie emotional"
docs = vector_store.similarity_search(query, k=2)
docs
[Document(id='2d8538f7-4dee-4029-b0f3-f3cd970791d9', metadata={'source': 'tweet'}, page_content='This film was a heartwarming tale of love and friendship'),
Document(id='91b2e127-f0da-40a2-867f-2b66306f9eb5', metadata={'source': 'news'}, page_content='The movie was a thrilling adventure with stunning visual effects and a captivating storyline.')]
# Filter by metadata
docs = vector_store.similarity_search(query, k=2, filter={"source": "tweet"})
docs
3.6.5.2.3.5. Retrievers#
how to use retrievers in LangChain
# convert to retriever
retriever = vector_store.as_retriever()
standard retriever
retriever.invoke("what kind of movie do you like?", k=1)
[Document(id='f44187f6-7d10-4458-84d5-e1cd70a5ddf0', metadata={'source': 'tweet'}, page_content='I love to watch romantic movie on the weekends.')]
Ensemble retriever: sử dụng nhiều retriever khác nhau để cải thiện độ chính xác và độ tin cậy của kết quả tìm kiếm. Bằng cách kết hợp các phương pháp khác nhau, nó có thể cung cấp một cái nhìn toàn diện hơn về dữ liệu và giúp giảm thiểu sai sót trong việc tìm kiếm thông tin.
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import ConfigurableField
doc_list_1 = [
"I like apples",
"I like oranges",
"Apples and oranges are fruits",
]
# initialize the bm25 retriever and faiss retriever
bm25_retriever = BM25Retriever.from_texts(
doc_list_1, metadatas=[{"source": 1}] * len(doc_list_1)
)
bm25_retriever.k = 2
doc_list_2 = [
"You like apples",
"You like oranges",
]
embedding = OpenAIEmbeddings()
faiss_vectorstore = FAISS.from_texts(
doc_list_2, embedding, metadatas=[{"source": 2}] * len(doc_list_2)
)
faiss_retriever = faiss_vectorstore.as_retriever(
search_kwargs={"k": 2}
).configurable_fields(
search_kwargs=ConfigurableField(
id="search_kwargs_faiss",
name="Search Kwargs",
description="The search kwargs to use",
)
)
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
docs = ensemble_retriever.invoke("apples")
docs
[Document(metadata={'source': 1}, page_content='I like apples'),
Document(id='1aed61e8-aa92-4d89-8ee3-01ee763329c7', metadata={'source': 2}, page_content='You like apples'),
Document(metadata={'source': 1}, page_content='Apples and oranges are fruits'),
Document(id='bb8a8aaf-8786-403a-9503-d8eb0a2d9628', metadata={'source': 2}, page_content='You like oranges')]
3.6.5.2.3.6. Indexing#
The indexing API lets you load and keep in sync documents from any source into a vector store, save you time and money, as well as improve your vector search results. It helps:
Avoid writing duplicated content into the vector store
Avoid re-writing unchanged content
Avoid re-computing embeddings over unchanged content
Indexing API will work even with documents that have gone through several transformation steps (e.g., via text chunking) with respect to the original source documents.
3.6.5.2.4. Chains & Agents#
3.6.5.2.4.1. Chat Models#
(updating…)
3.6.5.2.4.2. Sequential Chains#
(updating…)
3.6.5.2.4.3. Memory#
(updating…)
3.6.5.2.4.4. Tools#
(updating…)
3.6.5.2.4.5. Multimodal#
(updating…)
3.6.5.2.4.6. Router Chains#
(updating…)
3.6.5.2.4.7. Agent#
(updating…)
3.6.5.2.4.8. Callbacks#
(updating…)
3.6.5.2.5. Additional Features#
3.6.5.2.5.1. Serialization#
(updating)
3.6.5.2.5.2. Customization#
(updating)
3.6.5.3. Langchain Ecosystem#
3.6.5.3.1. LangGraph#
LangGraph là một thư viện mở rộng từ LangChain, giúp bạn xây dựng các ứng dụng điều khiển bởi đồ thị (graph-based apps), nơi các bước xử lý (node) có thể phân nhánh, lặp lại, và lưu trạng thái — phù hợp với các use case như chatbot phức tạp, multi-agent system, hay những workflow cần lặp logic theo điều kiện.
Nhiệm vụ cụ thể:
Tạo ra đồ thị trạng thái (state machine) cho các ứng dụng LLM.
Hỗ trợ logic phức tạp như loop, branching, retry, hoặc agent tương tác với nhau.
Mỗi node trong graph đại diện cho một hành động: gọi LLM, truy vấn CSDL, phân tích chuỗi, v.v.
Có thể dùng để xây dựng ứng dụng như: multi-turn conversation, code generation with review, autonomous agents (autoGPT-style).
Tối ưu khi bạn muốn quản lý trạng thái nội bộ qua nhiều vòng lặp tương tác.
👉 Ví dụ: Xây dựng một bot tài chính tự động kiểm tra dữ liệu, hỏi lại user nếu thiếu input, truy xuất thông tin thị trường, rồi đề xuất hành động — tất cả được tổ chức qua LangGraph như một flow linh hoạt.
3.6.5.3.2. LangSmith#
LangSmith là một nền tảng giám sát (observability) và debug cho các ứng dụng dùng LLM. Nó ghi lại chi tiết từng bước gọi model, đầu vào/đầu ra, thời gian, chi phí, để bạn dễ dàng kiểm thử, theo dõi và cải tiến các chain hoặc agent.
Nhiệm vụ cụ thể:
Debug và theo dõi quá trình gọi LLM, API, tool… trong ứng dụng.
Log và lưu lại trace của từng cuộc gọi — thấy được input, prompt, response, độ trễ, error, v.v.
Cho phép so sánh kết quả giữa các phiên bản model/prompt (A/B testing).
Dùng để huấn luyện RAG, hoặc tinh chỉnh prompt và logic xử lý.
Tích hợp tốt với LangChain & LangGraph để quan sát toàn bộ pipeline từ đầu đến cuối.
👉 Ví dụ: Khi triển khai một chatbot chứng khoán, LangSmith giúp bạn xem lại cuộc hội thoại người dùng, hiểu tại sao LLM trả lời sai, kiểm tra lại dữ liệu hoặc prompt để tối ưu độ chính xác.
3.6.5.4. Mini-labs#
3.6.5.4.1. Summarize web pages#
r.jina.ai: Get content from a web page then convert to Markdown
import requests
from langchain_core.documents import Document
url = "https://cafef.vn/ong-trump-tuyen-bo-san-sang-dam-phan-thue-quan-188250404103344639.chn"
response = requests.get(f"https://r.jina.ai/{url}")
markdown_content = response.text
# Tạo document cho LangChain
documents = [Document(page_content=markdown_content, metadata={"source": url})]
print(documents[0].page_content)
Title: Ông Trump tuyên bố sẵn sàng đàm phán thuế quan
URL Source: https://cafef.vn/ong-trump-tuyen-bo-san-sang-dam-phan-thue-quan-188250404103344639.chn
Published Time: 2025-04-04T10:33:00
Markdown Content:
Ông Trump tuyên bố sẵn sàng đàm phán thuế quan
===============
[](https://cafef.vn/ "Kênh thông tin kinh tế - tài chính Việt Nam")
* Chọn mã CK
cần theo dõi
* Chọn mã CK
cần theo dõi
* Chọn mã CK
cần theo dõi
* Chọn mã CK
cần theo dõi
* Chọn mã CK
cần theo dõi
* Chọn mã CK
cần theo dõi
* Chọn mã CK
cần theo dõi
[](javascript:;)
[](javascript:;)
[Xóa toàn bộ](javascript:;)
[Bảng giá điện tử](http://liveboard.cafef.vn/ "Bảng giá điện tử") [Danh mục đầu tư](https://cafef.vn/du-lieu/danh-muc-dau-tu.chn "Danh mục đầu tư")
MỚI NHẤT!
[Đọc nhanh \>\>](https://cafef.vn/doc-nhanh.chn "Đọc nhanh")
* 15:10 [Nỗi khổ tuổi 35: Khủng hoảng độ tuổi chưa kịp đi qua thì làn sóng AI đã ập tới, không nắm được ‘mật mã làm giàu’, đời này coi như mãi ì ạch!](https://cafef.vn/noi-kho-tuoi-35-khung-hoang-do-tuoi-chua-kip-di-qua-thi-lan-song-ai-da-ap-toi-khong-nam-duoc-mat-ma-lam-giau-doi-nay-coi-nhu-mai-i-ach-188250404135414924.chn "Nỗi khổ tuổi 35: Khủng hoảng độ tuổi chưa kịp đi qua thì làn sóng AI đã ập tới, không nắm được ‘mật mã làm giàu’, đời này coi như mãi ì ạch!")
* 15:05 [Thị trường ngập sắc đỏ và xanh sàn, một cổ phiếu ngân hàng vẫn tím lịm](https://cafef.vn/thi-truong-ngap-sac-do-va-xanh-san-mot-co-phieu-ngan-hang-van-tim-lim-188250404150544609.chn "Thị trường ngập sắc đỏ và xanh sàn, một cổ phiếu ngân hàng vẫn tím lịm")
* 15:05 [Bộ Công an cảnh báo về thủ đoạn lừa đảo mới, chưa từng xuất hiện liên quan đến ship hàng](https://cafef.vn/bo-cong-an-canh-bao-ve-thu-doan-lua-dao-moi-chua-tung-xuat-hien-lien-quan-den-ship-hang-188250404142120161.chn "Bộ Công an cảnh báo về thủ đoạn lừa đảo mới, chưa từng xuất hiện liên quan đến ship hàng")
* 15:00 [Ông Trump khoe ‘thẻ vàng’ trị giá 5 triệu USD đầu tiên của Mỹ, dự kiến ra mắt chính thức trong 2 tuần nữa](https://cafef.vn/ong-trump-khoe-the-vang-tri-gia-5-trieu-usd-dau-tien-cua-my-du-kien-ra-mat-chinh-thuc-trong-2-tuan-nua-18825040414045325.chn "Ông Trump khoe ‘thẻ vàng’ trị giá 5 triệu USD đầu tiên của Mỹ, dự kiến ra mắt chính thức trong 2 tuần nữa")
* 15:00 [Kinh tế TP Hồ Chí Minh tăng cao nhất kể từ năm 2020](https://cafef.vn/kinh-te-tp-ho-chi-minh-tang-cao-nhat-ke-tu-nam-2020-188250403143306928.chn "Kinh tế TP Hồ Chí Minh tăng cao nhất kể từ năm 2020")
* 14:57 [Mỹ áp thuế 46% với Việt Nam là lời "cảnh tỉnh" về mô hình sản xuất chi phí thấp, nhưng doanh nghiệp nào làm được điều này sẽ có cơ hội chiếm lĩnh thị trường](https://cafef.vn/my-ap-thue-46-voi-viet-nam-la-loi-canh-tinh-ve-mo-hinh-san-xuat-chi-phi-thap-nhung-doanh-nghiep-nao-lam-duoc-dieu-nay-se-co-co-hoi-chiem-linh-thi-truong-188250404145723917.chn "Mỹ áp thuế 46% với Việt Nam là lời \"cảnh tỉnh\" về mô hình sản xuất chi phí thấp, nhưng doanh nghiệp nào làm được điều này sẽ có cơ hội chiếm lĩnh thị trường")
* 14:54 [Vingroup đề xuất thực hiện dự án khu đô thị kết hợp sân golf tại Thanh Oai (Hà Nội), quy mô 1.470ha với tổng vốn 75.000 tỷ đồng](https://cafef.vn/vingroup-de-xuat-thuc-hien-du-an-khu-do-thi-ket-hop-san-golf-tai-thanh-oai-ha-noi-quy-mo-1470ha-voi-tong-von-75000-ty-dong-188250404140003188.chn "Vingroup đề xuất thực hiện dự án khu đô thị kết hợp sân golf tại Thanh Oai (Hà Nội), quy mô 1.470ha với tổng vốn 75.000 tỷ đồng")
* 14:48 [Thời kỳ việc ổn lương cao đã hết, lập trình viên còn phải trả 10.000 USD để tìm được công việc ưng ý](https://cafef.vn/thoi-ky-viec-on-luong-cao-da-het-lap-trinh-vien-con-phai-tra-10000-usd-de-tim-duoc-cong-viec-ung-y-188250404133510713.chn "Thời kỳ việc ổn lương cao đã hết, lập trình viên còn phải trả 10.000 USD để tìm được công việc ưng ý")
* 14:46 [Khánh Ly nói về lần gặp Trịnh Công Sơn năm 1967 ở TP.HCM](https://cafef.vn/khanh-ly-noi-ve-lan-gap-trinh-cong-son-nam-1967-o-tphcm-188250404141917607.chn "Khánh Ly nói về lần gặp Trịnh Công Sơn năm 1967 ở TP.HCM")
* 14:45 [Chuyên trang Anh đánh giá đây là thực phẩm tốt nhất thế giới: Việt Nam trồng nhiều, năng suất cao bất ngờ](https://cafef.vn/chuyen-trang-anh-danh-gia-day-la-thuc-pham-tot-nhat-the-gioi-viet-nam-trong-nhieu-nang-suat-cao-bat-ngo-188250404140503718.chn "Chuyên trang Anh đánh giá đây là thực phẩm tốt nhất thế giới: Việt Nam trồng nhiều, năng suất cao bất ngờ")
* 14:45 [Đỗ Vinh Quang - Đỗ Mỹ Linh: Cặp đôi mạnh nhất làng bóng đá, chồng giữ 2 chức Chủ tịch, vợ cũng làm "sếp to"](https://cafef.vn/do-vinh-quang-do-my-linh-cap-doi-manh-nhat-lang-bong-da-chong-giu-2-chuc-chu-tich-vo-cung-lam-sep-to-188250404135128494.chn "Đỗ Vinh Quang - Đỗ Mỹ Linh: Cặp đôi mạnh nhất làng bóng đá, chồng giữ 2 chức Chủ tịch, vợ cũng làm \"sếp to\"")
* 14:43 [Tin mới vụ nam sinh từ thủ khoa thành trượt cấp 3 ở Thanh Hóa: Có dấu hiệu trầm cảm, nghỉ học chờ thi lại](https://cafef.vn/tin-moi-vu-nam-sinh-tu-thu-khoa-thanh-truot-cap-3-o-thanh-hoa-co-dau-hieu-tram-cam-nghi-hoc-cho-thi-lai-188250404142611323.chn "Tin mới vụ nam sinh từ thủ khoa thành trượt cấp 3 ở Thanh Hóa: Có dấu hiệu trầm cảm, nghỉ học chờ thi lại")
* 14:42 [Nhựa Bình Minh đặt kế hoạch quay lại mốc lãi sau thuế nghìn tỷ, sếp người Thái nhận lương 6,2 tỷ xin nghỉ](https://cafef.vn/nhua-binh-minh-dat-ke-hoach-quay-lai-moc-lai-sau-thue-nghin-ty-sep-nguoi-thai-nhan-luong-62-ty-xin-nghi-188250404144213248.chn "Nhựa Bình Minh đặt kế hoạch quay lại mốc lãi sau thuế nghìn tỷ, sếp người Thái nhận lương 6,2 tỷ xin nghỉ")
* 14:33 [Phú Thọ dừng lễ hội, hoạt động dâng hương các Vua Hùng vẫn diễn ra](https://cafef.vn/phu-tho-dung-le-hoi-hoat-dong-dang-huong-cac-vua-hung-van-dien-ra-188250404143339557.chn "Phú Thọ dừng lễ hội, hoạt động dâng hương các Vua Hùng vẫn diễn ra")
* 14:33 [Giới siêu giàu Mỹ tăng mạnh tìm kiếm và mua nhiều hầm trú ẩn xa xỉ](https://cafef.vn/gioi-sieu-giau-my-tang-manh-tim-kiem-va-mua-nhieu-ham-tru-an-xa-xi-188250404142727921.chn "Giới siêu giàu Mỹ tăng mạnh tìm kiếm và mua nhiều hầm trú ẩn xa xỉ")
* 14:31 [Cổ phiếu Vietnam Airlines bất ngờ "bay cao" trong phiên cuối tuần 4/4](https://cafef.vn/co-phieu-vietnam-airlines-bat-ngo-bay-cao-trong-phien-cuoi-tuan-4-4-188250404143129439.chn "Cổ phiếu Vietnam Airlines bất ngờ \"bay cao\" trong phiên cuối tuần 4/4")
* 14:31 [Thất bại lớn nhất sự nghiệp Elon Musk: Làm Cybertruck để tiết kiệm 200 triệu USD xây xưởng sơn nhưng tiêu tốn cả thập kỷ nghiên cứu, vừa hoạt động 13 tháng đã bị thu hồi 8 lần](https://cafef.vn/that-bai-lon-nhat-su-nghiep-elon-musk-lam-cybertruck-de-tiet-kiem-200-trieu-usd-xay-xuong-son-nhung-tieu-ton-ca-thap-ky-nghien-cuu-vua-hoat-dong-13-thang-da-bi-thu-hoi-8-lan-188250404131404159.chn "Thất bại lớn nhất sự nghiệp Elon Musk: Làm Cybertruck để tiết kiệm 200 triệu USD xây xưởng sơn nhưng tiêu tốn cả thập kỷ nghiên cứu, vừa hoạt động 13 tháng đã bị thu hồi 8 lần")
* 14:29 [Động thái của Thùy Tiên](https://cafef.vn/dong-thai-cua-thuy-tien-18825040413561771.chn "Động thái của Thùy Tiên")
* 14:28 [Sợ KPI ở các công ty lớn, thạc sỹ báo chí đi làm phục vụ căng tin](https://cafef.vn/so-kpi-o-cac-cong-ty-lon-thac-sy-bao-chi-di-lam-phuc-vu-cang-tin-188250404140337498.chn "Sợ KPI ở các công ty lớn, thạc sỹ báo chí đi làm phục vụ căng tin")
* 14:25 [Bị Mỹ đưa dầu thô vào tầm ngắm, xuất khẩu của một quốc gia OPEC lao dốc chỉ trong 1 tháng, khách hàng Trung Quốc, Ấn Độ dần tránh xa](https://cafef.vn/bi-my-dua-dau-tho-vao-tam-ngam-xuat-khau-cua-mot-quoc-gia-opec-lao-doc-chi-trong-1-thang-khach-hang-trung-quoc-an-do-dan-tranh-xa-18825040414184466.chn "Bị Mỹ đưa dầu thô vào tầm ngắm, xuất khẩu của một quốc gia OPEC lao dốc chỉ trong 1 tháng, khách hàng Trung Quốc, Ấn Độ dần tránh xa")
* [](https://cafef.vn/ "Trang chủ")
* [XÃ HỘI](https://cafef.vn/xa-hoi.chn "XÃ HỘI")
* [CHỨNG KHOÁN](https://cafef.vn/thi-truong-chung-khoan.chn "CHỨNG KHOÁN")
* [BẤT ĐỘNG SẢN](https://cafef.vn/bat-dong-san.chn "BẤT ĐỘNG SẢN")
* [DOANH NGHIỆP](https://cafef.vn/doanh-nghiep.chn "DOANH NGHIỆP")
* [NGÂN HÀNG](https://cafef.vn/tai-chinh-ngan-hang.chn "NGÂN HÀNG")
* [SMART MONEY](https://cafef.vn/smart-money.chn "Smart Money")
* [TÀI CHÍNH QUỐC TẾ](https://cafef.vn/tai-chinh-quoc-te.chn "TÀI CHÍNH QUỐC TẾ")
* [VĨ MÔ](https://cafef.vn/vi-mo-dau-tu.chn "VĨ MÔ")
* [KINH TẾ SỐ](https://cafef.vn/kinh-te-so.chn "KINH TẾ SỐ")
* [THỊ TRƯỜNG](https://cafef.vn/thi-truong.chn "THỊ TRƯỜNG")
* [SỐNG](https://cafef.vn/song.chn "SỐNG")
* [LIFESTYLE](https://cafef.vn/lifestyle.chn "LIFESTYLE")
* [](javascript:;)
Tin tức [Xã hội](https://cafef.vn/xa-hoi.chn "xã hội") [Doanh nghiệp](https://cafef.vn/doanh-nghiep.chn "doanh nghiệp") [Kinh tế vĩ mô](https://cafef.vn/vi-mo-dau-tu.chn "kinh tế vĩ mô")
Tài chính - Chứng khoán [Chứng khoán](https://cafef.vn/thi-truong-chung-khoan.chn "chứng khoáng") [Tài chính ngân hàng](https://cafef.vn/tai-chinh-ngan-hang.chn "tài chính ngân hàng") [Tài chính quốc tế](https://cafef.vn/tai-chinh-quoc-te.chn "tài chính quốc tế")
Bất động sản [Tin tức](https://cafef.vn/bat-dong-san.chn "tin tức") [Dự án](https://cafef.vn/du-an.chn "dự án") [Bản đồ dự án](https://cafef.vn/ban-do-du-an.chn "bản đồ dự án")
Khác [Hàng hóa nguyên liệu](https://cafef.vn/hang-hoa-nguyen-lieu.chn "hàng hóa nguyên liệu") [Sống](https://cafef.vn/song.chn "sống") [Lifestyle](https://cafef.vn/lifestyle.chn "Lifestyle")
CHỦ ĐỀ NÓNG
* [Đánh thức dòng tiền nhàn rỗi](https://cafef.vn/su-kien/danh-thuc-dong-tien-nhan-roi-950.chn "Đánh thức dòng tiền nhàn rỗi")
* [Chủ Thẻ thông minh](https://cafef.vn/su-kien/chu-the-thong-minh-927.chn "Chủ Thẻ thông minh")
* [Smart Money](https://cafef.vn/su-kien/smart-money-953.chn "Smart Money")
[Magazine](https://cafef.vn/nhom-chu-de/emagazine.chn)
* [Dữ liệu](https://cafef.vn/du-lieu.chn "Dữ liệu")
* [CafeF Lists](https://cafef.vn/du-lieu/cafeflists.chn "CafeF Lists")
Ông Trump tuyên bố sẵn sàng đàm phán thuế quan
==============================================
04-04-2025 - 10:33 AM | [Tài chính quốc tế](https://cafef.vn/tai-chinh-quoc-te.chn "Tài chính quốc tế")
[Chia sẻ 13](javascript:;)
[](https://cafef.vn/ "Trang chủ")
[](javascript:; "Chia sẻ")
[](mailto:email@domain.com?subject=%C3%94ng%20Trump%20tuy%C3%AAn%20b%E1%BB%91%20s%E1%BA%B5n%20s%C3%A0ng%20%C4%91%C3%A0m%20ph%C3%A1n%20thu%E1%BA%BF%20quan&body=https%3A%2F%2Fcafef.vn%2Fong-trump-tuyen-bo-san-sang-dam-phan-thue-quan-188250404103344639.chn "email")
Tổng thống Mỹ Donald Trump để ngỏ khả năng đàm phán thuế quan với các đối tác thương mại.
-----------------------------------------------------------------------------------------
* 04-04-2025[Chứng khoán Mỹ rung chuyển vì thuế quan: Dow Jones chốt phiên giảm 1600 điểm,...](https://cafef.vn/chung-khoan-my-rung-chuyen-vi-thue-quan-dow-jones-chot-phien-giam-1600-diem-sp-500-ghi-nhan-ngay-te-nhat-5-nam-188250404080736639.chn "Chứng khoán Mỹ rung chuyển vì thuế quan: Dow Jones chốt phiên giảm 1600 điểm, S&P 500 ghi nhận ngày tệ nhất 5 năm")
* 04-04-2025[Ông Trump: Trung Quốc sẽ được giảm thuế nếu thỏa thuận bán TikTok thành công](https://cafef.vn/ong-trump-trung-quoc-se-duoc-giam-thue-neu-thoa-thuan-ban-tiktok-thanh-cong-188250404080632352.chn "Ông Trump: Trung Quốc sẽ được giảm thuế nếu thỏa thuận bán TikTok thành công")
* 04-04-2025[Báo Hàn nói ông Trump tính thuế bằng một phép toán sai, Seoul áp thuế thấp hơn...](https://cafef.vn/bao-han-noi-ong-trump-tinh-thue-bang-mot-phep-toan-sai-seoul-ap-thue-thap-hon-nhieu-thong-tin-tu-my-188250404060254574.chn "Báo Hàn nói ông Trump tính thuế bằng một phép toán sai, Seoul áp thuế thấp hơn nhiều thông tin từ Mỹ")
[TIN MỚI](javascript:; "TIN MỚI")
* [](https://lg1.logging.admicro.vn/nd?nid=188250404110544154&zid=-1&dmn=https%3A%2F%2Fcafef.vn&cov=1&url=%2F/hai-nhom-co-phieu-bat-ngo-nguoc-duong-nguoc-gio-giua-luc-thi-truong-roi-manh-188250404110544154.chn&re=https://cafef.vn/hai-nhom-co-phieu-bat-ngo-nguoc-duong-nguoc-gio-giua-luc-thi-truong-roi-manh-188250404110544154.chn&covid=0&gid=188250404110544154&ext=lastid_0&bx=5&dsp=53&alg=136 "Hai nhóm cổ phiếu bất ngờ “ngược đường, ngược gió” giữa lúc thị trường rơi mạnh")
[Hai nhóm cổ phiếu bất ngờ “ngược đường, ngược gió” giữa lúc thị trường rơi mạnh](https://lg1.logging.admicro.vn/nd?nid=188250404110544154&zid=-1&dmn=https%3A%2F%2Fcafef.vn&cov=1&url=%2F/hai-nhom-co-phieu-bat-ngo-nguoc-duong-nguoc-gio-giua-luc-thi-truong-roi-manh-188250404110544154.chn&re=https://cafef.vn/hai-nhom-co-phieu-bat-ngo-nguoc-duong-nguoc-gio-giua-luc-thi-truong-roi-manh-188250404110544154.chn&covid=0&gid=188250404110544154&ext=lastid_0&bx=5&dsp=53&alg=136 "Hai nhóm cổ phiếu bất ngờ “ngược đường, ngược gió” giữa lúc thị trường rơi mạnh")
* [](https://lg1.logging.admicro.vn/nd?nid=1882504041039395&zid=-1&dmn=https%3A%2F%2Fcafef.vn&cov=1&url=%2F/nguyen-bo-truong-y-te-co-vi-pham-nghiem-trong-tai-2-benh-vien-lang-phi-nghin-ty-1882504041039395.chn&re=https://cafef.vn/nguyen-bo-truong-y-te-co-vi-pham-nghiem-trong-tai-2-benh-vien-lang-phi-nghin-ty-1882504041039395.chn&covid=0&gid=1882504041039395&ext=lastid_0&bx=5&dsp=53&alg=136 "Nguyên Bộ trưởng Y tế có vi phạm nghiêm trọng tại 2 bệnh viện lãng phí nghìn tỷ")
[Nguyên Bộ trưởng Y tế có vi phạm nghiêm trọng tại 2 bệnh viện lãng phí nghìn tỷ](https://lg1.logging.admicro.vn/nd?nid=1882504041039395&zid=-1&dmn=https%3A%2F%2Fcafef.vn&cov=1&url=%2F/nguyen-bo-truong-y-te-co-vi-pham-nghiem-trong-tai-2-benh-vien-lang-phi-nghin-ty-1882504041039395.chn&re=https://cafef.vn/nguyen-bo-truong-y-te-co-vi-pham-nghiem-trong-tai-2-benh-vien-lang-phi-nghin-ty-1882504041039395.chn&covid=0&gid=1882504041039395&ext=lastid_0&bx=5&dsp=53&alg=136 "Nguyên Bộ trưởng Y tế có vi phạm nghiêm trọng tại 2 bệnh viện lãng phí nghìn tỷ")
* [](https://lg1.logging.admicro.vn/nd?nid=18825040317001393&zid=-1&dmn=https%3A%2F%2Fcafef.vn&cov=1&url=%2F/nu-tiep-vien-hang-khong-bi-hanh-khach-can-vao-tay-chuyen-bay-khoi-hanh-cham-2-tieng-18825040317001393.chn&re=https://cafef.vn/nu-tiep-vien-hang-khong-bi-hanh-khach-can-vao-tay-chuyen-bay-khoi-hanh-cham-2-tieng-18825040317001393.chn&covid=0&gid=18825040317001393&ext=lastid_0&bx=5&dsp=53&alg=136 "Nữ tiếp viên hàng không bị hành khách cắn vào tay, chuyến bay khởi hành chậm 2 tiếng")
[Nữ tiếp viên hàng không bị hành khách cắn vào tay, chuyến bay khởi hành chậm 2 tiếng](https://lg1.logging.admicro.vn/nd?nid=18825040317001393&zid=-1&dmn=https%3A%2F%2Fcafef.vn&cov=1&url=%2F/nu-tiep-vien-hang-khong-bi-hanh-khach-can-vao-tay-chuyen-bay-khoi-hanh-cham-2-tieng-18825040317001393.chn&re=https://cafef.vn/nu-tiep-vien-hang-khong-bi-hanh-khach-can-vao-tay-chuyen-bay-khoi-hanh-cham-2-tieng-18825040317001393.chn&covid=0&gid=18825040317001393&ext=lastid_0&bx=5&dsp=53&alg=136 "Nữ tiếp viên hàng không bị hành khách cắn vào tay, chuyến bay khởi hành chậm 2 tiếng")
[](https://cafefcdn.com/203337114487263232/2025/4/4/trump-1743737576576-17437375770951818566279.jpg)
Tổng thống Mỹ Donald Trump cho biết ông sẵn sàng thỏa thuận thuế quan với các quốc gia khác, trái ngược với tuyên bố trước đó của quan chức Nhà Trắng.
Trên chuyên cơ Không Lực Một, ông Trump khẳng định sẵn sàng đàm phán nếu các đối tác đưa ra “điều gì đó tốt đẹp”, Reuters cho biết.
Phát biểu của Tổng thống Mỹ trái ngược với Peter Navarro, cố vấn thương mại của ông Trump. Navarro nói với CNBC rằng các mức thuế quan đối ứng này không phải để đàm phán.
Ông Trump cũng tiết lộ các mức thuế quan bổ sung đối với chip bán dẫn và dược phẩm sẽ sớm có hiệu lực, CNN đưa tin. Tổng thống Mỹ cảnh báo thuế dược phẩm sẽ ở mức chưa từng thấy. Chất bán dẫn và dược phẩm là hai trong số những mặt hàng được Tổng thống Trump loại trừ trong thuế suất mà ông công bố ngày 2/4.
Trước thông tin thị trường chứng khoán Mỹ trải qua ngày tồi tệ chưa từng có kể từ 2020, ông Trump nhận định đó là “điều dễ hiểu” và nền kinh tế đang trong “giai đoạn chuyển tiếp”.
Ngày 2/4, Tổng thống Mỹ Donald Trump công bố áp thuế cơ bản 10% đối với hàng hóa nhập khẩu vào Mỹ (hiệu lực từ 5/4) và các mức thuế đối ứng với từng đối tác thương mại (hiệu lực từ 9/4).
Chính sách thuế quan của ông Trump đã khiến thị trường chao đảo. Chỉ số S&P 500 giảm 4,84%, chốt phiên 3/4 ở 5.396,52 điểm, mức thấp nhất kể từ tháng 6/2020. Chỉ số trung bình công nghiệp Dow Jones giảm 1.679,39 điểm (tương đương 3,98%), chốt phiên ở mức 40.545,93 điểm. Trong khi đó, Nasdaq Composite lao dốc 5,97%, đóng cửa ở 16.550,61 điểm. Đây cũng là mức giảm mạnh nhất kể từ tháng 3/2020.
Theo CNBC, CNN
[Nền kinh tế 2.500 tỷ USD tự tin có thể là ‘người chiến thắng’ trong cuộc chiến thương mại toàn cầu](https://cafef.vn/nen-kinh-te-2500-ty-usd-tu-tin-co-the-la-nguoi-chien-thang-trong-cuoc-chien-thuong-mai-toan-cau-188250402134613182.chn "Nền")
Y Vân
Nhịp Sống Thị Trường
[Theo Nhịp Sống Thị Trường _Copy link_ 04/04/2025 10:28 (GMT +7)](javascript:; "Nhịp Sống Thị Trường")
Link bài gốc _Lấy link!_ https://markettimes.vn/ong-trump-tuyen-bo-san-sang-dam-phan-thue-quan-80184.html
[](https://lg1.logging.admicro.vn/cpx_cms?dmn=https%3A%2F%2Fcafef.vn%2Fong-trump-tuyen-bo-san-sang-dam-phan-thue-quan-188250404103344639.chn&zid=kq8zddh7&pli=kzmggxbg&cmpg=kzmfiuu4&items=kzmggxxw&cat=%2ftai-chinh-quoc-te%2fdetail%2f&cov=1&pgid=1743754257953108754&uid=1743754257953108754&re=https%3A%2F%2Fcafef.vn%2Fdownload-app.html&lc=)
[Chia sẻ 13](javascript:;)
**Từ Khóa:**
[nhà trắng,](https://cafef.vn/nha-trang.html "nhà trắng") [donald trump,](https://cafef.vn/donald-trump.html " donald trump") [tổng thống mỹ,](https://cafef.vn/tong-thong-my.html " tổng thống mỹ") [thương mại,](https://cafef.vn/thuong-mai.html " thương mại") [chất bán dẫn](https://cafef.vn/chat-ban-dan.html " chất bán dẫn")
### CÙNG CHUYÊN MỤC
Xem theo ngày XEM
[](https://cafef.vn/chung-khoan-my-cam-dau-lao-doc-dow-jones-giam-gan-1500-diem-sp-500-rot-xuong-muc-thap-nhat-trong-2-nam-ruoi-sau-khi-ong-trump-ap-thue-188250403214429273.chn "Chứng khoán Mỹ cắm đầu lao dốc, Dow Jones giảm gần 1.500 điểm, S&P 500 rớt xuống mức thấp nhất trong 2 năm rưỡi sau khi ông Trump áp thuế")
#### [Chứng khoán Mỹ cắm đầu lao dốc, Dow Jones giảm gần 1.500 điểm, S&P 500 rớt xuống mức thấp nhất trong 2 năm rưỡi sau khi ông Trump áp thuế](https://cafef.vn/chung-khoan-my-cam-dau-lao-doc-dow-jones-giam-gan-1500-diem-sp-500-rot-xuong-muc-thap-nhat-trong-2-nam-ruoi-sau-khi-ong-trump-ap-thue-188250403214429273.chn "Chứng khoán Mỹ cắm đầu lao dốc, Dow Jones giảm gần 1.500 điểm, S&P 500 rớt xuống mức thấp nhất trong 2 năm rưỡi sau khi ông Trump áp thuế") Nổi bật
[](https://cafef.vn/nha-dau-tu-chot-loi-gia-vang-giam-gan-25-sau-khi-dat-dinh-moi-thoi-dai-vi-thue-quan-cua-ong-trump-18825040321175785.chn "Nhà đầu tư chốt lời, giá vàng giảm gần 2,5% sau khi đạt đỉnh mọi thời đại vì thuế quan của ông Trump")
#### [Nhà đầu tư chốt lời, giá vàng giảm gần 2,5% sau khi đạt đỉnh mọi thời đại vì thuế quan của ông Trump](https://cafef.vn/nha-dau-tu-chot-loi-gia-vang-giam-gan-25-sau-khi-dat-dinh-moi-thoi-dai-vi-thue-quan-cua-ong-trump-18825040321175785.chn "Nhà đầu tư chốt lời, giá vàng giảm gần 2,5% sau khi đạt đỉnh mọi thời đại vì thuế quan của ông Trump") Nổi bật
[](https://cafef.vn/warren-buffett-doc-tho-khi-chung-khoan-giam-manh-nhat-5-nam-chang-may-khi-co-mua-vang-hay-di-lay-xo-hung-lay-co-hoi-loi-khuyen-cua-ty-phu-94-tuoi-voi-334-ty-usd-tien-mat-da-san-sang-188250404102134651.chn "Warren Buffett đọc thơ khi chứng khoán giảm mạnh nhất 5 năm: ‘Chẳng mấy khi có mưa vàng, hãy đi lấy xô hứng lấy cơ hội’, lời khuyên của tỷ phú 94 tuổi với 334 tỷ USD tiền mặt 'đã sẵn sàng'")
#### [Warren Buffett đọc thơ khi chứng khoán giảm mạnh nhất 5 năm: ‘Chẳng mấy khi có mưa vàng, hãy đi lấy xô hứng lấy cơ hội’, lời khuyên của tỷ phú 94 tuổi với 334 tỷ USD tiền mặt 'đã sẵn sàng'](https://cafef.vn/warren-buffett-doc-tho-khi-chung-khoan-giam-manh-nhat-5-nam-chang-may-khi-co-mua-vang-hay-di-lay-xo-hung-lay-co-hoi-loi-khuyen-cua-ty-phu-94-tuoi-voi-334-ty-usd-tien-mat-da-san-sang-188250404102134651.chn "Warren Buffett đọc thơ khi chứng khoán giảm mạnh nhất 5 năm: ‘Chẳng mấy khi có mưa vàng, hãy đi lấy xô hứng lấy cơ hội’, lời khuyên của tỷ phú 94 tuổi với 334 tỷ USD tiền mặt 'đã sẵn sàng'")
2 giờ trước
[](https://cafef.vn/nhung-am-thanh-la-duoc-phat-hien-tu-xac-tau-titanic-duoi-do-sau-3810-m-co-nguon-goc-tu-dau-188250404090430472.chn "Những âm thanh lạ được phát hiện từ xác tàu Titanic dưới độ sâu 3.810 m có nguồn gốc từ đâu?")
#### [Những âm thanh lạ được phát hiện từ xác tàu Titanic dưới độ sâu 3.810 m có nguồn gốc từ đâu?](https://cafef.vn/nhung-am-thanh-la-duoc-phat-hien-tu-xac-tau-titanic-duoi-do-sau-3810-m-co-nguon-goc-tu-dau-188250404090430472.chn "Những âm thanh lạ được phát hiện từ xác tàu Titanic dưới độ sâu 3.810 m có nguồn gốc từ đâu?")
2 giờ trước
[](https://cafef.vn/nu-ty-phu-madam-pang-cuc-than-thai-chiem-tron-spotlight-khi-den-ha-noi-sau-vu-khoc-nuc-no-vi-khoan-no-300ty-188250404091954013.chn "Nữ tỷ phú Madam Pang cực thần thái, chiếm trọn \"spotlight\" khi đến Hà Nội sau vụ khóc nức nở vì khoản nợ 300tỷ")
#### [Nữ tỷ phú Madam Pang cực thần thái, chiếm trọn "spotlight" khi đến Hà Nội sau vụ khóc nức nở vì khoản nợ 300tỷ](https://cafef.vn/nu-ty-phu-madam-pang-cuc-than-thai-chiem-tron-spotlight-khi-den-ha-noi-sau-vu-khoc-nuc-no-vi-khoan-no-300ty-188250404091954013.chn "Nữ tỷ phú Madam Pang cực thần thái, chiếm trọn \"spotlight\" khi đến Hà Nội sau vụ khóc nức nở vì khoản nợ 300tỷ")
1 giờ trước
[](https://cafef.vn/tai-sao-mot-cuoc-dien-thoai-duoc-thuc-hien-tren-via-he-cach-day-hon-50-nam-lai-co-the-thay-doi-cuoc-song-cua-toan-bo-nhan-loai-188250404082528473.chn "Tại sao một cuộc điện thoại được thực hiện trên vỉa hè cách đây hơn 50 năm lại có thể thay đổi cuộc sống của toàn bộ nhân loại?")
#### [Tại sao một cuộc điện thoại được thực hiện trên vỉa hè cách đây hơn 50 năm lại có thể thay đổi cuộc sống của toàn bộ nhân loại?](https://cafef.vn/tai-sao-mot-cuoc-dien-thoai-duoc-thuc-hien-tren-via-he-cach-day-hon-50-nam-lai-co-the-thay-doi-cuoc-song-cua-toan-bo-nhan-loai-188250404082528473.chn "Tại sao một cuộc điện thoại được thực hiện trên vỉa hè cách đây hơn 50 năm lại có thể thay đổi cuộc sống của toàn bộ nhân loại?")
34 phút trước
[](javascript:; "Tìm kiếm")
Công ty Tin tức Lãnh đạo
* [](https://cafef.vn/ "Trang chủ")
* [XÃ HỘI](https://cafef.vn/xa-hoi.chn "XÃ HỘI")
* [CHỨNG KHOÁN](https://cafef.vn/thi-truong-chung-khoan.chn "CHỨNG KHOÁN")
* [BẤT ĐỘNG SẢN](https://cafef.vn/bat-dong-san.chn "BẤT ĐỘNG SẢN")
* [DOANH NGHIỆP](https://cafef.vn/doanh-nghiep.chn "DOANH NGHIỆP")
* [NGÂN HÀNG](https://cafef.vn/tai-chinh-ngan-hang.chn "NGÂN HÀNG")
* [TÀI CHÍNH QUỐC TẾ](https://cafef.vn/tai-chinh-quoc-te.chn "TÀI CHÍNH QUỐC TẾ")
* [VĨ MÔ](https://cafef.vn/vi-mo-dau-tu.chn "VĨ MÔ")
* [KINH TẾ SỐ](https://cafef.vn/kinh-te-so.chn "KINH TẾ SỐ")
* [THỊ TRƯỜNG](https://cafef.vn/thi-truong.chn "THỊ TRƯỜNG")
* [SỐNG](https://cafef.vn/song.chn "SỐNG")
* [LIFESTYLE](https://cafef.vn/lifestyle.chn "LIFESTYLE")
* [Dữ liệu](https://cafef.vn/du-lieu.chn "Dữ liệu")
* [Top 200](https://cafef.vn/du-lieu/top/ceo.chn "Top 200")
Địa chỉ: Tầng 21 Tòa nhà Center Building. Số 1 Nguyễn Huy Tưởng, Thanh Xuân, Hà Nội.
Điện thoại: 024 7309 5555 Máy lẻ 292. Fax: 024-39744082
Email: info@cafef.vn | Hotline: 0926 864 344
Chịu trách nhiệm nội dung: Ông Nguyễn Thế Tân
**Liên hệ quảng cáo**
Hotline: 02473007108
Email: doanhnghiep@admicro.vn
[Chat với tư vấn viên](https://www.messenger.com/t/108804609142280 "Xem chi tiết")
[](http://www.vccorp.vn/ "Công ty Cổ phần VCCorp")
**© Copyright 2007 - 2025 - Công ty Cổ phần VCCorp.**
Giấy phép thiết lập trang thông tin điện tử tổng hợp trên mạng số 2216/GP-TTĐT do Sở Thông tin và Truyền thông Hà Nội cấp ngày 10 tháng 4 năm 2019.
[Chính sách bảo mật](https://cafef.vn/static/chinh-sach-bao-mat.html "Chính sách bảo mật")
Trở lên trên
Get specific content via BeatifulSoup
from langchain_community.document_loaders import WebBaseLoader
from bs4 import SoupStrainer
url = "https://cafef.vn/ong-trump-tuyen-bo-san-sang-dam-phan-thue-quan-188250404103344639.chn"
strainer = SoupStrainer("div", attrs={"class": "detail-content afcbc-body"})
loader = WebBaseLoader(url, bs_kwargs={"parse_only": strainer})
documents = loader.load()
print(documents[0].page_content)
TIN MỚI
Tổng thống Mỹ Donald Trump cho biết ông sẵn sàng thỏa thuận thuế quan với các quốc gia khác, trái ngược với tuyên bố trước đó của quan chức Nhà Trắng. Trên chuyên cơ Không Lực Một, ông Trump khẳng định sẵn sàng đàm phán nếu các đối tác đưa ra “điều gì đó tốt đẹp”, Reuters cho biết. Phát biểu của Tổng thống Mỹ trái ngược với Peter Navarro, cố vấn thương mại của ông Trump. Navarro nói với CNBC rằng các mức thuế quan đối ứng này không phải để đàm phán. Ông Trump cũng tiết lộ các mức thuế quan bổ sung đối với chip bán dẫn và dược phẩm sẽ sớm có hiệu lực, CNN đưa tin. Tổng thống Mỹ cảnh báo thuế dược phẩm sẽ ở mức chưa từng thấy. Chất bán dẫn và dược phẩm là hai trong số những mặt hàng được Tổng thống Trump loại trừ trong thuế suất mà ông công bố ngày 2/4. Trước thông tin thị trường chứng khoán Mỹ trải qua ngày tồi tệ chưa từng có kể từ 2020, ông Trump nhận định đó là “điều dễ hiểu” và nền kinh tế đang trong “giai đoạn chuyển tiếp”. Ngày 2/4, Tổng thống Mỹ Donald Trump công bố áp thuế cơ bản 10% đối với hàng hóa nhập khẩu vào Mỹ (hiệu lực từ 5/4) và các mức thuế đối ứng với từng đối tác thương mại (hiệu lực từ 9/4). Chính sách thuế quan của ông Trump đã khiến thị trường chao đảo. Chỉ số S&P 500 giảm 4,84%, chốt phiên 3/4 ở 5.396,52 điểm, mức thấp nhất kể từ tháng 6/2020. Chỉ số trung bình công nghiệp Dow Jones giảm 1.679,39 điểm (tương đương 3,98%), chốt phiên ở mức 40.545,93 điểm. Trong khi đó, Nasdaq Composite lao dốc 5,97%, đóng cửa ở 16.550,61 điểm. Đây cũng là mức giảm mạnh nhất kể từ tháng 3/2020. Theo CNBC, CNN Nền kinh tế 2.500 tỷ USD tự tin có thể là ‘người chiến thắng’ trong cuộc chiến thương mại toàn cầu
# Extracting content from specific sections
import re
def multi_pattern_strip(text, patterns):
"""
Remove any of the given patterns if they appear at the start or end
of the string, including if they repeat or mix together.
Patterns in the middle remain untouched.
"""
# Escape each pattern (so special regex characters won't break things)
combined = "|".join(re.escape(p) for p in patterns)
# Build regex that matches one or more occurrences of any pattern at start
start_regex = r"^(?:" + combined + r")+"
# Build regex that matches one or more occurrences of any pattern at end
end_regex = r"(?:" + combined + r")+$"
# Strip from the start
text = re.sub(start_regex, "", text)
# Strip from the end
text = re.sub(end_regex, "", text)
# replace special characters
text = re.sub(r"\ufeff", " ", text)
text = re.sub(r"\s+", " ", text)
return text
# Example usage:
patterns = ["\n", "TIN MỚI", " "]
content = multi_pattern_strip(documents[0].page_content, patterns)
content
'Tổng thống Mỹ Donald Trump cho biết ông sẵn sàng thỏa thuận thuế quan với các quốc gia khác, trái ngược với tuyên bố trước đó của quan chức Nhà Trắng. Trên chuyên cơ Không Lực Một, ông Trump khẳng định sẵn sàng đàm phán nếu các đối tác đưa ra “điều gì đó tốt đẹp”, Reuters cho biết. Phát biểu của Tổng thống Mỹ trái ngược với Peter Navarro, cố vấn thương mại của ông Trump. Navarro nói với CNBC rằng các mức thuế quan đối ứng này không phải để đàm phán. Ông Trump cũng tiết lộ các mức thuế quan bổ sung đối với chip bán dẫn và dược phẩm sẽ sớm có hiệu lực, CNN đưa tin. Tổng thống Mỹ cảnh báo thuế dược phẩm sẽ ở mức chưa từng thấy. Chất bán dẫn và dược phẩm là hai trong số những mặt hàng được Tổng thống Trump loại trừ trong thuế suất mà ông công bố ngày 2/4. Trước thông tin thị trường chứng khoán Mỹ trải qua ngày tồi tệ chưa từng có kể từ 2020, ông Trump nhận định đó là “điều dễ hiểu” và nền kinh tế đang trong “giai đoạn chuyển tiếp”. Ngày 2/4, Tổng thống Mỹ Donald Trump công bố áp thuế cơ bản 10% đối với hàng hóa nhập khẩu vào Mỹ (hiệu lực từ 5/4) và các mức thuế đối ứng với từng đối tác thương mại (hiệu lực từ 9/4). Chính sách thuế quan của ông Trump đã khiến thị trường chao đảo. Chỉ số S&P 500 giảm 4,84%, chốt phiên 3/4 ở 5.396,52 điểm, mức thấp nhất kể từ tháng 6/2020. Chỉ số trung bình công nghiệp Dow Jones giảm 1.679,39 điểm (tương đương 3,98%), chốt phiên ở mức 40.545,93 điểm. Trong khi đó, Nasdaq Composite lao dốc 5,97%, đóng cửa ở 16.550,61 điểm. Đây cũng là mức giảm mạnh nhất kể từ tháng 3/2020. Theo CNBC, CNN Nền kinh tế 2.500 tỷ USD tự tin có thể là ‘người chiến thắng’ trong cuộc chiến thương mại toàn cầu'
from bs4 import BeautifulSoup
# Load the web page content
html_content = loader.load()[0].page_content
# Parse the HTML to extract the title
soup = BeautifulSoup(html_content, "html.parser")
title = soup.title.string.strip() if soup.title else "No title found"
print(title)
No title found
import requests
from bs4 import BeautifulSoup
# Fetch the webpage content
response = requests.get(url)
html_content = response.text
# Parse the HTML to extract the title
soup = BeautifulSoup(html_content, "html.parser")
title = soup.title.string.strip() if soup.title else "No title found"
print(title)
Ông Trump tuyên bố sẵn sàng đàm phán thuế quan
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from dotenv import load_dotenv
load_dotenv(r"contents\theory\aiml_algorithms\dl_llm\.env")
# Load the OpenAI model
model = ChatOpenAI(model="gpt-4o-mini", temperature=0.0)
system_message_prompt = SystemMessagePromptTemplate.from_template(
"You are an advanced AI assistant that summarizes online articles into bulleted lists."
)
human_message_prompt = HumanMessagePromptTemplate.from_template(
"""Here's the article you need to summarize.
==================
Title: {title}
{content}
==================
Now, provide a summarized version of the article in a bulleted list format in Vietnamese."
"""
)
# format prompt
prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, human_message_prompt]
).format_messages(
title=title,
content=content,
)
# Invoke the model with the formatted prompt
ai_msg = model.invoke(prompt)
print(ai_msg.content)
- Tổng thống Mỹ Donald Trump tuyên bố sẵn sàng đàm phán thuế quan với các quốc gia khác.
- Tuyên bố này trái ngược với quan điểm của Peter Navarro, cố vấn thương mại của ông Trump, người cho rằng các mức thuế quan không thể đàm phán.
- Ông Trump thông báo sẽ áp dụng các mức thuế quan bổ sung đối với chip bán dẫn và dược phẩm, với mức thuế dược phẩm được cho là chưa từng thấy.
- Các mặt hàng chip bán dẫn và dược phẩm đã được loại trừ khỏi thuế suất công bố ngày 2/4.
- Thị trường chứng khoán Mỹ trải qua ngày tồi tệ nhất kể từ 2020, với chỉ số S&P 500 giảm 4,84%.
- Chỉ số Dow Jones giảm 1.679,39 điểm (3,98%), trong khi Nasdaq Composite giảm 5,97%.
- Ông Trump cho rằng sự sụt giảm của thị trường là "điều dễ hiểu" và nền kinh tế đang trong "giai đoạn chuyển tiếp".
- Chính sách thuế quan mới của ông Trump có hiệu lực từ 5/4 và các mức thuế đối ứng từ 9/4.
3.6.5.4.2. QA chatbot#
# Load docs
from langchain.document_loaders import WebBaseLoader
from langchain.prompts import PromptTemplate
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
len(data)
1
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
len(all_splits)
131
%pip install -qU tiktoken faiss-cpu
Note: you may need to restart the kernel to use updated packages.
from langchain.vectorstores import FAISS
from langchain.chains import ConversationalRetrievalChain
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
# Your existing code to create 'all_splits' list of Document objects:
# all_splits = [...]
# 1) Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(all_splits, embedding=embeddings)
# 2) Initialize your Language Model
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# 3) Create a retriever from your vector store
retriever = vectorstore.as_retriever()
# 4) Build the chain that orchestrates retrieval + LLM Q&A
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
# return_source_documents=True, # set to True if you want to see which docs were referenced
)
def run(qa_chain=qa_chain):
# 5) Simulate a small chat loop
chat_history = []
print("Starting chat. Type 'exit' or 'quit' to end.\n")
while True:
user_query = input("User: ")
if user_query.lower() in ("exit", "quit"):
print("Goodbye!")
break
print("User query:", user_query)
# Ask the chain
result = qa_chain(
{"question": user_query, "chat_history": chat_history}
)
# The 'result' dict typically includes:
# - "answer": the chain's best answer
# - "source_documents": any docs retrieved (if return_source_documents=True)
print(f"Assistant: {result['answer']}\n")
# Update chat history so the chain can keep context
chat_history.append((user_query, result["answer"]))
# OPTIONAL: If you want to see the sources used:
# for i, doc in enumerate(result["source_documents"]):
# print(f"Source Document {i + 1} Metadata: {doc.metadata}")
# # print(doc.page_content) # Or the text excerpt itself
print()
run()
Starting chat. Type 'exit' or 'quit' to end.
Assistant: Hello! How can I assist you today?
Assistant: The topic of the documents revolves around the synthesis of chemical weapon agents, the risks associated with illicit drugs and bioweapons, and the testing of an agent's ability to synthesize these substances. It also discusses the decision-making process involved in accepting or rejecting synthesis requests based on documentation and prompts.
Assistant: CoT, or Chain of Thought, is a prompting technique that enhances model performance on complex tasks by instructing the model to "think step by step." This approach allows the model to decompose hard tasks into smaller and simpler steps, transforming big tasks into multiple manageable tasks. It also provides insight into the model's thinking process.
Assistant: Nothing more to clarify.
Assistant: Self-reflection is a process that allows autonomous agents to improve by analyzing their past actions, learning from mistakes, and refining their decision-making. It involves using examples of failed actions and ideal reflections to guide future changes in plans. This process is crucial in real-world tasks where trial and error are common. In the context of frameworks like Reflexion, self-reflection is integrated with dynamic memory and reasoning skills to enhance the agent's performance.
Assistant: Nothing more to clarify.
Alternative ways
from langchain.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from dotenv import load_dotenv
load_dotenv(r"contents\theory\aiml_algorithms\dl_llm\.env")
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(all_splits, embedding=embeddings)
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
retriever = vectorstore.as_retriever()
from langchain_core.prompts import ChatPromptTemplate
system_prompt = (
"You are a helpful assistant that provides answers based on the retrieved information"
"\n\n"
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
# Create a chain that uses the retriever and the prompt
question_answer_chain = create_stuff_documents_chain(llm, prompt)
# Then, combine this with the retriever to form the retrieval chain:
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
# invoke the chain with a user’s question
result = rag_chain.invoke(
{"input": "What is the main topic of the documents?"}
)
print(result["answer"])
The main topic of the documents revolves around the development and testing of language model (LLM)-centered agents, particularly focusing on their capabilities and limitations in synthesizing chemical weapon agents and the associated risks with illicit drugs and bioweapons. The documents discuss the outcomes of tests conducted on these agents, including acceptance and rejection rates of synthesis requests.
# invoke the chain with a user’s question
result = rag_chain.invoke({"input": "what is the API-Bank?"})
print(result["answer"])
API-Bank is a benchmark designed to evaluate the performance of tool-augmented large language models (LLMs). It includes 53 commonly used API tools, a complete workflow for tool-augmented LLMs, and 264 annotated dialogues that involve a total of 568 API calls. The APIs included in API-Bank cover a wide range of functionalities, such as search engines, calculators, calendar queries, smart home control, schedule management, health data management, and account authentication workflows. The benchmark allows for the assessment of LLMs' decision-making abilities, particularly in planning and executing multiple API calls to address complex user requests.
Web page
from bs4 import SoupStrainer
from langchain_community.document_loaders import WebBaseLoader
content_and_title = SoupStrainer(
"div",
attrs={
"class": [
"the_content"
# , "title-main"
]
},
)
page_url = "https://pinetree.vn/post/dich-vu/mo-tai-khoan-chung-khoan-khach-hang-ca-nhan/"
content_loader = WebBaseLoader(
web_path=page_url, bs_kwargs={"parse_only": content_and_title}
)
docs = content_loader.load()
docs
[Document(metadata={'source': 'https://pinetree.vn/post/dich-vu/mo-tai-khoan-chung-khoan-khach-hang-ca-nhan/'}, page_content='\nMở tài khoản chứng khoán tại Pinetree chưa bao giờ dễ dàng đến thế. Quý khách chỉ cần\xa02 phút\xa0để đăng ký và có thể giao dịch ngay sau khi tạo tài khoản online thành công.\nCông ty chứng khoán duy nhất MIỄN PHÍ GIAO DỊCH TRỌN ĐỜI! Lãi suất Margin chỉ 9.9%/ năm không kèm theo điều kiện.\nCác cách mở tài khoản chứng khoán tại Pinetree:\nCÁCH 1: MỞ TÀI KHOẢN TẠI QUẦY\nQuý khách vui lòng mang theo CMND hoặc CCCD còn hiệu lực theo quy định đến trực tiếp tại trụ sở của Pinetree theo địa chỉ như sau: Phòng\xa0Dịch\xa0vụ\xa0Khách hàng\nCông ty Cổ phần Chứng khoán Pinetree\nĐịa chỉ: Tầng 20, Tòa nhà ROX Tower, 54A Nguyễn Chí Thanh, Láng Thượng, Đống Đa, Hà NộiChuyên viên Pinetree sẽ hỗ trợ và hướng dẫn Quý khách đăng ký mở tài khoản tại quầy. \nCÁCH 2: MỞ TÀI KHOẢN E-KYC – TÀI KHOẢN ĐƯỢC ACTIVE GIAO DỊCH NGAY TRONG NGÀY\nBước 1:\xa0Quý khách truy cập App store/ CH play, tải về 1 trong 2 ứng dụng Alphatrading hoặc PineX.\nBước 2:\xa0Chuẩn bị chứng minh thư bản gốc.\nBước 3:\xa0Thực hiện theo hướng dẫn\xa0tại đây.\nCÁCH 3: MỞ TÀI KHOẢN TẠI WEBSITE\xa0– Mất 3-4 ngày để hoàn tất hồ sơ\nBước 1:\xa0Quý khách truy cập vào website của Công ty Cổ phần Chứng khoán Pinetree theo đường dẫn sau: https://pinetree.vn/\nBước 2:\xa0Nhấp chuột vào “MỞ TÀI KHOẢN” như hình dưới:\n\nBước 3:\xa0Sau khi chọn “MỞ TÀI KHOẢN”, Quý khách sẽ được chuyển đến trang điền thông tin mở tài khoản. Quý khách vui lòng điền thông tin đầy đủ và chính xác theo hướng dẫn.\nLưu ý:\nSố điện thoại: Số điện thoại dùng để xác thực tạo tài khoản chứng khoán, xác thực giao dịch và liên hệ với Pinetree.Thông tin cá nhân:\nHọ và tên: Quý khách vui lòng nhập thông tin đầy đủ họ và tên và viết có dấu như trong thông tin ghi trên CMND/CCCD.\nEmail: Hòm thư dùng để xác thực mở tài khoản, nhận thông tin từ Pinetree.\nGiới tính: Quý khách tích chọn Nam hoặc Nữ\nNgày sinh: Thông tin trùng khớp với thông tin trong CMT hoặc Thẻ căn cước.\nThông tin CMT/Thẻ căn Cước: Thông tin số CMT/Thẻ căn cước, ngày cấp và nơi cấp\nThông tin địa chỉ: Quý khách ghi đầy đủ Địa chỉ thường trú và Địa chỉ liên lạc bao gồm: Số nhà, Phường/Xã, Quận/Huyện, Tỉnh/Thành Phố.\nThông tin ngân hàng: Quý khách vui lòng điền thông tin ngân hàng mà Quý khách đang sử dụng để sau này thực hiện chuyển tiền từ tài khoản chứng khoán ra ngoài.\n(Trong trường hợp chưa có tài khoản ngân hàng, Quý khách có thể bỏ qua và bổ sung thêm tài khoản sau khi Đăng ký mở tài khoản thành công)\nBước 4:\xa0Pinetree thông báo tạo tài khoản chứng khoán thành công:\nQuý khách vui lòng kiểm tra Email hoặc tin nhắn điện thoại đã đăng ký khi mở tài khoản để biết thông tin Số tài khoản, thông tin đăng nhập tài khoản chứng khoán và trải nghiệm hệ sinh thái của Pinetree.\nBước 5: Quý khách hàng hoàn thiện hợp đồng mở tài khoản để kích hoạt đầy đủ các dịch vụ tiện ích.\n(Hướng dẫn chi tiết trong mục HƯỚNG DẪN HOÀN THIỆN HỢP ĐỒNG MỞ TK TẠI PINETREE).\n\nLưu ý: Việc đăng ký mở tài khoản và hoàn thiện hồ sơ cần được thực hiện bởi chính chủ tài khoản. \n')]