3.5.1.4. Embedding#
Embedding là cách ánh xạ mỗi token/từ/câu từ không gian rời rạc sang không gian vector liên tục (thường là vector thực chiều d, ví dụ 100, 300, 768, 1024). Các vector này được thiết kế/huấn luyện sao cho mang thông tin về ngữ nghĩa (meaning) và ngữ cảnh (context & relationship) của từ, bổ sung phần relationships giữa các tokens và có thể learning trong lúc train thay vì chỉ là những con số static
Các từ đồng nghĩa/sát nghĩa thì sau khi chạy qua Embeddings layers/model (ví dụ word2vec) sẽ trả ra các vector gần bằng nhau, thể hiện nếu biểu diễn trong không gian thì các từ này sẽ gần nhau.
Word Embedding (ví dụ: Word2Vec, GloVe, FastText):
Mỗi từ tĩnh (static embedding) có một vector cố định.
Không phân biệt nghĩa khác nhau của từ trong các ngữ cảnh khác nhau (cùng một từ “bank” – “ngân hàng” –> thường có 1 vector duy nhất).
Negative Sampling often use to reduces computational intensity by focusing on a subset of vocabulary for model updates.
1. Word2Vec: based on the idea that words appearing in the same context oftern share similar mearning.
2. GloVe:: Leverages co-occurrence statistics to create embeddings.
3. fastText:: Represents subwords, enhancing rare word embeddings.
Có thể upload các
vector outputkèmlabels(các words) lên TensorFlow Embedding Projector để visualize tính relationships giữa các wordsContextual Embedding (ví dụ: BERT, GPT, ELMo):
Vector biểu diễn từ phụ thuộc vào ngữ cảnh xung quanh.
Từ “bank” trong câu “I put money in the bank” và “he sat on the bank of the river” sẽ có 2 vector khác nhau, nhờ mô hình Transformer/RNN nắm được ngữ cảnh.
Sentence Embedding / Document Embedding:
Thay vì embedding cho từng từ, mô hình tạo vector cho câu hoặc đoạn văn. Ví dụ: Sentence-BERT, Universal Sentence Encoder, InferSent, v.v.
Có 2 hướng tiếp cận Embeddings:
Create your own embedding: Để sử dụng được embedding, text cần phải được turn into numbers, sau đó sử dụng
embedding layer(such astf.keras.layers.Embedding) để learn trong quá trình trainingReuse a pre-learned embedding(prefer): Sử dụng các tham số embedding trong các pre-train model để fine-tune lại own model. Các pre-train này học từ một số lượng lớn text ( Ví dụ như all of Wikipedia) nên có khả năng đại diện chính xác mỗi quan hệ giữa các từ
Sử dụng cách search tương tự như computer vision pretrain model trên TensorFlow Hub để lựa chọn ra một số pre-train model hiệu quả như Word2vec embeddings, GloVe embeddings,..
Ứng dụng
Phân loại văn bản (sentiment, topic): Dùng vector embedding (của từ hoặc câu) làm đầu vào mô hình.
Dịch máy, tóm tắt, chatbot: Hầu như mọi mô hình sequence-to-sequence (seq2seq) đều yêu cầu embedding tốt.
Truy xuất thông tin, tìm kiếm ngữ nghĩa: Tính tương đồng giữa câu truy vấn và câu trong văn bản thông qua cosine similarity, v.v.
Clustering, topic modeling: Nếu có embedding tốt, ta có thể gom nhóm các văn bản (hoặc từ) về chủ đề.
Recommendation, Phân tích đồ thị, …: Embedding được mở rộng không chỉ cho từ mà còn cho người dùng, item, node trong đồ thị (Graph Embedding).
3.5.1.4.1. Word Embedding - Word2Vec#
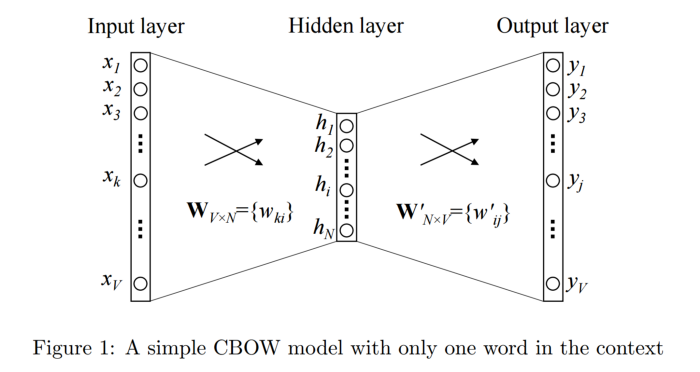
3.5.1.4.1.1. Continuous Bag-of-Words (CBOW)#
Phương pháp này lấy inputs đầu vào là một/nhiều từ context word và cố gắng dự đoán output là target word thông qua một tầng neural đơn giản. Nhờ việc đánh giá output error với target word ở dạng one-hot, mô hình có thể điều chỉnh weight, học được vector biểu diễn cho target word.
Ví dụ ta có một câu tiếng anh như sau : “I love you”. Ta có Input context word là “love” và Output target word là “you”. Ta biến đổi input context đầu vào dưới dạng one-hot đi qua một tầng hidden layer và thực hiện softmax phân loại để dự đoán ra từ tiếp theo là gì.
# import packages
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import Counter
import pandas as pd
import torch.optim as optim
import re
sentences = """ We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells."""
corpus = sentences.split(".")[:-1]
corpus = [sentence.strip() + "." for sentence in corpus]
corpus
['We are about to study the idea of a computational process.',
'Computational processes are abstract beings that inhabit computers.',
'As they evolve, processes manipulate other abstract things called data.',
'The evolution of a process is directed by a pattern of rules called a program.',
'People create programs to direct processes.',
'In effect,\nwe conjure the spirits of the computer with our spells.']
# Build vocab
def text_to_word_sequence(text):
# Remove special characters (.,) and convert to lowercase
text = re.sub(r"[^\w\s]", "", text)
return text.lower().split()
for i in range(len(corpus)):
corpus[i] = text_to_word_sequence(corpus[i])
all_words = [word for sentence in corpus for word in sentence]
word_counts = Counter(all_words)
sorted_word_counts = sorted(
word_counts.items(), key=lambda x: x[1], reverse=True
)
vocab = {"<OOV>": 1}
vocab.update({word: i + 2 for i, (word, _) in enumerate(sorted_word_counts)})
vocab
{'<OOV>': 1,
'the': 2,
'of': 3,
'a': 4,
'processes': 5,
'we': 6,
'are': 7,
'to': 8,
'computational': 9,
'process': 10,
'abstract': 11,
'called': 12,
'about': 13,
'study': 14,
'idea': 15,
'beings': 16,
'that': 17,
'inhabit': 18,
'computers': 19,
'as': 20,
'they': 21,
'evolve': 22,
'manipulate': 23,
'other': 24,
'things': 25,
'data': 26,
'evolution': 27,
'is': 28,
'directed': 29,
'by': 30,
'pattern': 31,
'rules': 32,
'program': 33,
'people': 34,
'create': 35,
'programs': 36,
'direct': 37,
'in': 38,
'effect': 39,
'conjure': 40,
'spirits': 41,
'computer': 42,
'with': 43,
'our': 44,
'spells': 45}
# Define some parameters
# + 1 for index of padding <PAD> because we will use padding in the future
# Ta đệm (padding) thêm một token đặc biệt <PAD> vào các câu ngắn hơn để tất cả câu trong batch có cùng độ dài với câu dài nhất.
# Padding sẽ giúp đồng nhất độ dài các câu trong batch
vocab_size = len(vocab) + 1
# Number of words to the left and right of the target word
window_size = 2
def texts_to_sequences(texts, vocab):
"""
Convert a list of texts to sequences of integers based on the vocab dictionary.
Each word in the text is replaced with its corresponding index from the vocab.
"""
texts = texts[0].split()
return [vocab[word] for word in texts if word in vocab]
def to_categorical(label, vocab):
"""
Convert a label to a categorical array based on the vocab dictionary.
The label is the target word, and the vocab dictionary maps words to their indices.
The function returns an array of zeros with length equal to the size of the vocab,
and sets the index corresponding to the label to 1.
"""
# Create an array with length is len(vocab) + 1 with all values are 0
categorical_array = [0.0] * (len(vocab) + 1)
# # If label is in vocab, set the value at the label's index to 1
if label in vocab:
index = vocab[label]
categorical_array[index] = 1.0
return categorical_array
def generate_pairs(window_size, corpus, vocab):
X = []
y = []
for words in corpus:
print(words)
start = 0
while start + window_size * 2 < len(words):
end = start + window_size * 2
tar_i = start + window_size
# Select the current word as the label
label = words[tar_i]
# Join k words on the left and k words on the right of this word into 1 sentence
x = [" ".join(words[start:tar_i] + words[tar_i + 1 : end + 1])]
print(" * ", x, "--->", label)
start += 1
X.append(texts_to_sequences(x, vocab))
y.append(to_categorical(label, vocab))
return X, y
X_train, y_train = generate_pairs(window_size, corpus, vocab)
['we', 'are', 'about', 'to', 'study', 'the', 'idea', 'of', 'a', 'computational', 'process']
* ['we are to study'] ---> about
* ['are about study the'] ---> to
* ['about to the idea'] ---> study
* ['to study idea of'] ---> the
* ['study the of a'] ---> idea
* ['the idea a computational'] ---> of
* ['idea of computational process'] ---> a
['computational', 'processes', 'are', 'abstract', 'beings', 'that', 'inhabit', 'computers']
* ['computational processes abstract beings'] ---> are
* ['processes are beings that'] ---> abstract
* ['are abstract that inhabit'] ---> beings
* ['abstract beings inhabit computers'] ---> that
['as', 'they', 'evolve', 'processes', 'manipulate', 'other', 'abstract', 'things', 'called', 'data']
* ['as they processes manipulate'] ---> evolve
* ['they evolve manipulate other'] ---> processes
* ['evolve processes other abstract'] ---> manipulate
* ['processes manipulate abstract things'] ---> other
* ['manipulate other things called'] ---> abstract
* ['other abstract called data'] ---> things
['the', 'evolution', 'of', 'a', 'process', 'is', 'directed', 'by', 'a', 'pattern', 'of', 'rules', 'called', 'a', 'program']
* ['the evolution a process'] ---> of
* ['evolution of process is'] ---> a
* ['of a is directed'] ---> process
* ['a process directed by'] ---> is
* ['process is by a'] ---> directed
* ['is directed a pattern'] ---> by
* ['directed by pattern of'] ---> a
* ['by a of rules'] ---> pattern
* ['a pattern rules called'] ---> of
* ['pattern of called a'] ---> rules
* ['of rules a program'] ---> called
['people', 'create', 'programs', 'to', 'direct', 'processes']
* ['people create to direct'] ---> programs
* ['create programs direct processes'] ---> to
['in', 'effect', 'we', 'conjure', 'the', 'spirits', 'of', 'the', 'computer', 'with', 'our', 'spells']
* ['in effect conjure the'] ---> we
* ['effect we the spirits'] ---> conjure
* ['we conjure spirits of'] ---> the
* ['conjure the of the'] ---> spirits
* ['the spirits the computer'] ---> of
* ['spirits of computer with'] ---> the
* ['of the with our'] ---> computer
* ['the computer our spells'] ---> with
# define model with CBOW architecture
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_size, window_size):
super(CBOW, self).__init__()
self.embedding = nn.Embedding(
num_embeddings=vocab_size, embedding_dim=embedding_size
)
self.linear = nn.Linear(embedding_size, vocab_size)
self.window_size = window_size
def forward(self, x):
# x: (batch_size, window_size*2)
embedded = self.embedding(
x
) # (batch_size, window_size*2, embedding_size)
mean_embedding = embedded.mean(dim=1) # (batch_size, embedding_size)
output = self.linear(mean_embedding) # (batch_size, vocab_size)
return F.log_softmax(output, dim=1)
embedding_size = 128
model = CBOW(
vocab_size=vocab_size,
embedding_size=embedding_size,
window_size=window_size,
)
# Print model
print(model)
CBOW(
(embedding): Embedding(46, 128)
(linear): Linear(in_features=128, out_features=46, bias=True)
)
# Install optimizer and loss function
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# Convert data to tensor
X_train_tensor = torch.tensor(X_train, dtype=torch.long)
y_train_tensor = torch.tensor(np.argmax(y_train, axis=1), dtype=torch.long)
# Training
model.train()
for epoch in range(30):
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
# Calculate accuracy
_, predicted = torch.max(outputs, 1)
correct = (predicted == y_train_tensor).sum().item()
accuracy = correct / y_train_tensor.size(0)
loss.backward()
optimizer.step()
print(
f"Epoch {epoch + 1}/{30}, Loss: {loss.item()}, Accuracy: {accuracy:.4f}"
)
Epoch 1/30, Loss: 3.838930606842041, Accuracy: 0.0000
Epoch 2/30, Loss: 3.786792039871216, Accuracy: 0.0000
Epoch 3/30, Loss: 3.734938383102417, Accuracy: 0.0000
Epoch 4/30, Loss: 3.683373212814331, Accuracy: 0.0526
Epoch 5/30, Loss: 3.6321029663085938, Accuracy: 0.0526
Epoch 6/30, Loss: 3.58113169670105, Accuracy: 0.1053
Epoch 7/30, Loss: 3.5304622650146484, Accuracy: 0.1842
Epoch 8/30, Loss: 3.480098009109497, Accuracy: 0.2105
Epoch 9/30, Loss: 3.4300448894500732, Accuracy: 0.2368
Epoch 10/30, Loss: 3.380302906036377, Accuracy: 0.2895
Epoch 11/30, Loss: 3.330876350402832, Accuracy: 0.2895
Epoch 12/30, Loss: 3.2817680835723877, Accuracy: 0.4474
Epoch 13/30, Loss: 3.2329814434051514, Accuracy: 0.5526
Epoch 14/30, Loss: 3.184518814086914, Accuracy: 0.5526
Epoch 15/30, Loss: 3.136383295059204, Accuracy: 0.5526
Epoch 16/30, Loss: 3.088578224182129, Accuracy: 0.6053
Epoch 17/30, Loss: 3.0411055088043213, Accuracy: 0.6579
Epoch 18/30, Loss: 2.993968963623047, Accuracy: 0.6842
Epoch 19/30, Loss: 2.9471707344055176, Accuracy: 0.7368
Epoch 20/30, Loss: 2.900712728500366, Accuracy: 0.7895
Epoch 21/30, Loss: 2.854599714279175, Accuracy: 0.8158
Epoch 22/30, Loss: 2.808833360671997, Accuracy: 0.8158
Epoch 23/30, Loss: 2.7634170055389404, Accuracy: 0.8421
Epoch 24/30, Loss: 2.718353748321533, Accuracy: 0.8684
Epoch 25/30, Loss: 2.6736466884613037, Accuracy: 0.8684
Epoch 26/30, Loss: 2.6292998790740967, Accuracy: 0.8947
Epoch 27/30, Loss: 2.5853171348571777, Accuracy: 0.8947
Epoch 28/30, Loss: 2.541701316833496, Accuracy: 0.9211
Epoch 29/30, Loss: 2.4984564781188965, Accuracy: 0.9474
Epoch 30/30, Loss: 2.455587148666382, Accuracy: 0.9474
def predict(model, example, vocab):
example = text_to_word_sequence(example)
# Convert word to index in vocab
example_indices = [
vocab.get(word, vocab["<OOV>"]) for word in example
] # Using <OOV> if word not exsist in vocab
# Ensure correct input size
if len(example_indices) < window_size * 2:
example_indices = [vocab["<OOV>"]] * (
window_size * 2 - len(example_indices)
) + example_indices
elif len(example_indices) > window_size * 2:
example_indices = example_indices[: window_size * 2]
# Convert index to tensor
example_tensor = torch.tensor(
[example_indices], dtype=torch.long
) # Change size to (1, window_size*2)
# Predicting
model.eval()
with torch.no_grad():
output = model(example_tensor)
# Get prediction index
prediction = torch.argmax(output, dim=1)
predicted_index = prediction.item()
# Convert predicted index to word
# Reverse vocab to get word from index
reverse_vocab = {v: k for k, v in vocab.items()}
return reverse_vocab.get(predicted_index, "Unknown")
example = "processes are beings that"
predict(model, example, vocab)
'abstract'
# Get weight of embedding layers
embedding_weights = model.embedding.weight.data.numpy()
embedding_weights = embedding_weights[1:] # Skip index 0 if it exists
# Convert weights to DataFrame
index = vocab.keys()
weights_df = pd.DataFrame(embedding_weights, index=index)
weights_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <OOV> | 0.389905 | -1.109480 | 1.644835 | -0.084169 | 0.057254 | -0.388765 | 0.045481 | 0.510196 | -0.794192 | -1.389454 | ... | 0.047143 | 0.325154 | 0.495515 | -0.732145 | 1.556470 | -0.125722 | 0.789184 | 0.612393 | -1.492640 | -0.254231 |
| the | -0.520417 | 0.683357 | 0.150257 | -0.045347 | 0.078930 | -0.088360 | 0.585286 | 0.204338 | -0.014623 | -0.819285 | ... | 1.160652 | 0.545298 | 1.006853 | 0.604770 | -0.906252 | 0.178453 | -0.938106 | -0.297223 | 2.197748 | -0.289560 |
| of | 1.400890 | -0.366025 | -0.977540 | 0.313851 | -0.351913 | -0.219751 | 0.301517 | 0.067768 | 0.064606 | 1.333917 | ... | -0.914267 | -0.005108 | -1.234752 | 0.981580 | -0.022175 | 1.856215 | -0.409921 | 0.729456 | 0.529162 | -0.979227 |
| a | 0.698702 | 0.618517 | -2.586899 | 0.659361 | 0.090039 | -0.345328 | -1.025897 | 0.795209 | -0.372867 | -1.407884 | ... | 0.051746 | 0.413118 | -0.005534 | -2.331634 | 0.267473 | 2.177905 | -1.517501 | -0.091842 | 0.221622 | 0.352464 |
| processes | -1.871820 | 0.962786 | 0.183841 | 0.332889 | 0.129025 | 0.133761 | 0.510126 | 0.450583 | 0.097102 | 1.229218 | ... | -0.229935 | 0.295959 | 0.354461 | -0.346432 | 1.752465 | 0.281848 | -0.920316 | -0.707775 | -0.965361 | -0.193560 |
| we | -1.110633 | 2.273843 | 1.683168 | -0.572802 | -1.125646 | -0.321904 | -0.873070 | -0.031077 | 0.295630 | 0.165363 | ... | -0.251594 | -2.213977 | 1.511951 | -1.886557 | -1.325644 | 1.241680 | -0.103040 | -1.300793 | -0.773364 | 0.190041 |
| are | 1.184452 | 0.347906 | -0.586051 | -0.261324 | 1.279664 | -0.336277 | -1.554830 | -0.951343 | -0.797251 | -0.115993 | ... | 0.571703 | 1.463430 | -1.060516 | 2.251875 | 0.131436 | 1.128954 | -1.559592 | 0.348998 | 1.077532 | -0.954482 |
| to | -2.388144 | -3.279280 | 1.125953 | 0.249960 | 0.916533 | -1.122409 | 0.290604 | 0.363455 | 0.618836 | -2.346579 | ... | 0.127895 | -0.916398 | 1.649432 | 0.907613 | 0.452089 | 0.888680 | -1.922471 | 0.991467 | 0.930343 | 0.723473 |
| computational | 1.774628 | 0.919428 | 0.637574 | -0.953115 | 2.978288 | 1.038176 | 0.986467 | 0.545089 | 1.099326 | -0.012502 | ... | -0.170953 | 2.650867 | -1.587984 | 1.317023 | 0.009458 | -0.551282 | -1.282117 | 0.223824 | 1.503281 | 1.617118 |
| process | -1.076078 | -0.349448 | 0.337552 | 2.675912 | 0.419905 | 0.027344 | -0.248149 | 0.037624 | -0.769814 | 0.243457 | ... | -1.383801 | 0.656899 | 0.022202 | 2.422990 | 0.427883 | -0.747099 | -1.180036 | 0.250964 | 1.876283 | -0.112510 |
| abstract | -1.559569 | 0.376366 | 1.957361 | -0.151613 | -1.243255 | -0.506213 | 0.825848 | -0.385836 | -0.762876 | -0.568150 | ... | 1.509223 | -0.644056 | 0.137628 | -0.431314 | -0.597012 | 0.724987 | -0.149198 | 0.503822 | -0.600391 | 0.314436 |
| called | -1.153575 | -1.071967 | 0.373456 | 0.655706 | 0.012618 | 0.553886 | -0.149536 | 1.078371 | 1.311121 | -2.216889 | ... | -1.390038 | 0.702334 | -0.375287 | 1.053986 | 0.274326 | -0.563583 | 0.000981 | 0.975736 | -0.115859 | 0.802493 |
| about | -0.706870 | -0.347965 | 0.424825 | -0.503087 | 0.351095 | 1.326115 | -1.303409 | -0.278064 | -0.117394 | -1.009162 | ... | 0.206419 | 1.031866 | 0.007151 | -0.981727 | -0.802130 | 0.835246 | -0.294596 | -1.239981 | -1.044984 | -0.148896 |
| study | -0.800565 | 0.829534 | -0.076641 | -0.686089 | -0.074184 | 1.252382 | -0.537267 | -0.089313 | 0.808643 | -3.199857 | ... | -0.850738 | 0.526582 | -0.454397 | 1.835986 | -1.164915 | 0.424618 | -0.664887 | 0.962456 | -0.177345 | -0.035343 |
| idea | -0.206204 | -1.886486 | -0.428327 | 2.290668 | -1.111690 | -0.171741 | -0.467612 | 0.047293 | 0.226488 | -0.485143 | ... | 0.232785 | -0.282702 | 0.825645 | 0.366724 | -1.785908 | 0.168768 | -0.088936 | 0.258363 | 1.903383 | -1.481879 |
| beings | -0.161902 | -2.255521 | 1.038807 | 0.499999 | -1.150301 | -0.693483 | -1.664936 | 0.118847 | -0.981710 | 3.145262 | ... | 2.314237 | 0.878266 | -1.729433 | -0.894151 | -0.461789 | 0.277239 | 2.293493 | -0.346626 | 0.174897 | 1.601838 |
| that | -0.782520 | 0.336544 | 0.070398 | -1.729684 | 1.108842 | 1.011329 | -0.338714 | 0.566059 | -0.238380 | 0.744824 | ... | 1.056964 | 0.430033 | 0.068781 | -0.642583 | 0.314800 | 1.491622 | -0.562195 | -0.350003 | 1.185323 | 0.172630 |
| inhabit | -1.144505 | 0.452644 | 0.365277 | 1.450293 | 0.317337 | -2.021997 | 1.346021 | -0.044700 | 0.286285 | -1.208633 | ... | -0.121872 | -0.453584 | -0.171603 | 1.512890 | 0.779996 | 0.987772 | 0.627441 | -0.067811 | 1.667943 | 0.455289 |
| computers | -0.420561 | 0.537444 | -0.019816 | -0.286590 | 0.611461 | 1.224485 | -0.219410 | 0.707176 | 0.975171 | -0.670666 | ... | -0.228098 | -0.893896 | 1.689232 | 0.387431 | -1.231503 | 0.884282 | 0.036442 | -0.489979 | 0.723711 | 1.160673 |
| as | -0.029885 | -0.695728 | -1.404447 | 0.162199 | 1.652434 | 1.318908 | -0.128423 | -0.354262 | 2.571842 | 0.643864 | ... | -0.415330 | -0.107298 | -0.617345 | 0.811452 | 0.752607 | 0.455825 | -0.638011 | 0.023436 | -0.459059 | 0.094958 |
| they | 0.196826 | 0.842831 | 1.201567 | 0.342371 | 1.231678 | 0.771180 | -0.871926 | -0.513613 | 0.460500 | 0.285778 | ... | -0.790325 | 1.456155 | 0.231301 | -0.107728 | -0.207540 | -0.076259 | -0.764928 | -1.024361 | 0.214045 | 0.363687 |
| evolve | 0.598765 | 0.068511 | -1.178954 | -0.235061 | 0.761872 | 0.332118 | 0.325140 | -0.601806 | -0.586687 | -0.297438 | ... | 0.441475 | 0.488338 | 1.324055 | -1.463396 | -0.714418 | 0.484404 | -1.871947 | -0.574838 | 1.028217 | 0.079396 |
| manipulate | -1.875156 | -1.133062 | 2.030073 | 1.308441 | -0.777917 | -0.474085 | 0.110099 | -0.182845 | -1.841565 | 1.260355 | ... | 0.221633 | -0.848960 | 1.043558 | 0.445250 | 0.250964 | -1.373600 | 1.099058 | 0.649576 | 0.398968 | 0.069455 |
| other | 0.345579 | -0.267770 | 0.335381 | 0.365605 | -0.625975 | -0.384050 | 0.691765 | 0.137578 | -0.628057 | -0.349274 | ... | -1.213021 | 1.265893 | 0.019957 | -0.257245 | -1.113999 | 0.883545 | -0.236375 | 0.021677 | 0.427439 | 1.460741 |
| things | -0.774673 | 0.564864 | -0.724971 | -0.492967 | 0.351058 | 0.743898 | -0.091001 | 0.389419 | -2.779512 | -0.693562 | ... | 0.615814 | 0.977540 | -2.452293 | -0.670593 | 0.503653 | 1.139080 | -0.217506 | 0.305190 | -0.656644 | 0.693821 |
| data | 0.933478 | 1.207034 | -1.067945 | 0.220860 | 0.133937 | 1.427764 | -1.748536 | -1.609127 | -0.811456 | -0.622103 | ... | 0.819180 | 0.156776 | -0.275815 | 2.290039 | 0.837897 | -0.701205 | -1.810462 | -1.336117 | -1.653702 | 1.212743 |
| evolution | -0.499973 | -0.543294 | -0.265168 | 1.149998 | -0.642530 | -0.535560 | -1.445030 | -0.209829 | -0.562035 | 0.256610 | ... | 0.480614 | 0.726418 | 0.983529 | 0.172286 | -1.410851 | 0.558578 | -2.548260 | 0.249937 | 0.704336 | -0.830058 |
| is | -0.060665 | 0.645943 | 0.089892 | 0.310678 | 1.562536 | -0.868201 | -0.831157 | 2.130910 | -0.509453 | 1.238699 | ... | 0.946537 | -0.513233 | 0.220490 | -1.676867 | -0.145599 | -0.543162 | 0.339634 | -0.227970 | -0.867677 | 1.644346 |
| directed | 1.563055 | 0.944555 | -1.540993 | -1.014104 | 0.396449 | 0.602750 | -0.375010 | -1.231941 | -0.299601 | -0.009049 | ... | 0.970187 | 0.211740 | 0.864893 | -1.243098 | -0.101371 | 1.373770 | 0.082078 | -2.027137 | 1.773082 | -0.876459 |
| by | 0.981246 | -2.208191 | 0.569337 | -0.023361 | 1.954634 | -2.074385 | -0.942472 | -0.037129 | -0.753785 | -0.260478 | ... | -0.620423 | -0.989020 | 0.683757 | 1.204119 | -0.965255 | -0.544274 | -0.220261 | -0.469252 | -1.192678 | -0.922694 |
| pattern | -1.404842 | 0.332627 | 0.947307 | 0.270091 | 2.589576 | 1.156730 | -1.026824 | -0.353888 | -1.054356 | -0.659345 | ... | -1.292369 | 0.054826 | 0.699363 | -0.782870 | -1.856931 | -0.029919 | -0.008692 | 0.065518 | 0.279610 | 0.966822 |
| rules | -0.648125 | 2.612951 | 0.775006 | 0.219306 | -0.097076 | -1.515775 | 0.186654 | -1.345861 | 0.521192 | -1.321733 | ... | -0.248553 | -0.297070 | 0.915678 | -0.936971 | -2.250454 | 0.390572 | 0.866540 | -0.922744 | -0.249872 | 0.944300 |
| program | -2.404007 | 0.786411 | -1.435886 | 0.262833 | 0.286659 | -1.244712 | -1.894936 | 0.506701 | 0.196545 | 1.788678 | ... | 1.150650 | -0.356291 | 0.551741 | 1.073620 | -0.007841 | 0.161835 | -0.545711 | 0.100331 | 1.594621 | 1.259699 |
| people | -1.479939 | -1.196984 | 0.269099 | -0.733605 | -0.274215 | -1.233066 | 1.011360 | -0.219507 | 0.107396 | 0.792114 | ... | 0.902993 | -0.764037 | -0.365080 | 2.370440 | 2.116214 | -0.691730 | 0.767627 | -0.492605 | 0.439039 | -0.159369 |
| create | 0.709594 | 0.720891 | 0.992078 | 1.111071 | 0.535927 | -0.137024 | 0.713421 | 0.998501 | 0.984884 | 0.161421 | ... | -0.229916 | -0.050509 | -0.524228 | -0.761472 | 0.657602 | -1.671643 | 0.589586 | 0.425244 | 1.451697 | 0.617334 |
| programs | 0.511966 | -0.077811 | -0.578497 | 0.675147 | -0.691260 | -1.088627 | -1.798949 | 0.699919 | -0.492844 | 0.706752 | ... | 0.000995 | -0.515531 | 1.926324 | -0.185987 | -0.631142 | 0.251135 | -0.429048 | -1.278306 | 0.767339 | -1.460164 |
| direct | 0.684587 | -1.295853 | 0.944508 | 1.032779 | -0.486186 | 0.685241 | 1.046272 | 0.013886 | -0.384525 | 1.384538 | ... | 0.741920 | -0.124455 | -0.571142 | -0.425331 | 1.051508 | -0.189589 | 0.872114 | 0.436657 | -1.603436 | -0.119165 |
| in | 0.244387 | 1.659079 | 0.622630 | 1.055894 | 0.842217 | -1.170623 | -1.100417 | -0.391081 | -1.318887 | 0.359003 | ... | -0.175114 | 0.636793 | -1.347118 | 0.753074 | 1.010129 | 1.551061 | -0.949753 | -0.337274 | -0.115705 | 0.574228 |
| effect | -0.968377 | -0.016783 | 0.094222 | -0.869936 | -0.218656 | -0.552416 | -0.753232 | 0.639868 | 0.026900 | 2.397774 | ... | 0.179294 | -0.543968 | -0.550502 | 0.792435 | 0.857214 | 0.701954 | 0.493094 | -0.374487 | 0.497056 | 0.028637 |
| conjure | -1.927167 | 0.760767 | -0.866464 | 0.560511 | -1.200336 | 0.084711 | 0.769606 | 1.539853 | -0.946284 | 0.727085 | ... | 1.776117 | -0.567390 | -0.407423 | -0.175225 | -0.518835 | 1.848010 | 0.788261 | 1.194978 | -0.052777 | -1.174419 |
| spirits | -0.418067 | -1.041535 | -1.381170 | 0.073989 | 2.145814 | -0.989302 | 0.114157 | -1.322287 | 0.836442 | -1.366719 | ... | -1.249380 | -1.828778 | 0.247502 | -1.595745 | -0.007575 | 0.413673 | 1.105864 | -1.417030 | -0.282312 | -0.339513 |
| computer | 1.025333 | -0.319281 | 0.458756 | 0.301170 | -0.385315 | 1.117744 | -0.524368 | 0.377584 | 0.135663 | -0.630051 | ... | -1.338736 | 0.583641 | -1.239743 | 0.670664 | 0.973175 | 1.922511 | 0.993696 | -0.842684 | -1.609831 | 0.235565 |
| with | 1.783579 | -0.697985 | 2.215325 | 0.726890 | -0.051695 | -0.135712 | -0.638182 | 0.335758 | -0.606271 | 0.497625 | ... | 0.247313 | 0.742886 | -0.461458 | 1.926098 | 0.195732 | -1.942122 | 0.766953 | -1.475732 | -0.552128 | -0.734228 |
| our | -1.526021 | -1.221914 | 0.422485 | -0.758308 | 1.354038 | -0.137776 | -0.061893 | -1.518895 | 1.150087 | 1.790547 | ... | -0.010596 | 0.272812 | -1.217184 | -1.195146 | -0.340570 | 1.461178 | -0.467636 | 2.070754 | 1.039894 | -0.297796 |
| spells | -0.955305 | -1.521193 | 0.434127 | -0.757081 | -0.670492 | -1.680328 | -1.736734 | -0.944105 | 0.363679 | -0.008323 | ... | -0.146392 | 0.724460 | -0.793535 | -0.576869 | 2.113383 | -0.109628 | -0.270393 | -1.963311 | 0.212646 | -0.604857 |
45 rows × 128 columns
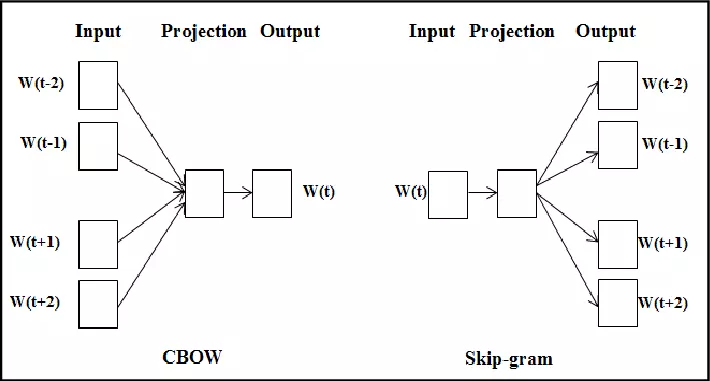
3.5.1.4.1.2. Skip-gram#
Nếu như CBOW sử dụng input là context word và cố gắng dự đoán từ đầu ra (target word) thì ngược lại, mô hình Skip-gram sử dụng input là target word và cố gắng dự đoán ra các từ hàng xóm của nó. Chúng định nghĩa các từ là hàng xóm (neightbor word) của nó thông qua tham số window size.
Ví dụ nếu bạn có một câu như sau: “Tôi thích ăn cua hoàng đế”. Và input target word ban đầu là từ cua. Với kích thước window size = 2, ta sẽ có các neighbor word (thích, ăn, hoàng, đế ). Và chúng ta sẽ có 4 cặp input-output như sau: (cua, thích ), (cua, hoàng ), (cua, đế ), (cua, ăn ). Các neightbor word được coi như nhau trong quá trình training.
3.5.1.4.2. Best Practice cho Embedding#
Sử dụng mô hình pre-trained (fine-tuned khi cần):
Mô hình Transformer hiện đại (BERT, RoBERTa, GPT, XLM-R, PhoBERT, v.v.) thường cung cấp embedding có chất lượng rất tốt.
Nếu dữ liệu bạn chuyên biệt (y tế, tài chính) hoặc tiếng Việt, nên dùng hoặc fine-tune mô hình pre-trained phù hợp (chẳng hạn PhoBERT cho tiếng Việt).
Chọn loại embedding:
Tĩnh (Word2Vec, GloVe): Đơn giản, dễ dùng, ít tài nguyên; nhưng không xử lý được từ đồng âm đa nghĩa theo ngữ cảnh.
Ngữ cảnh (Contextual, ví dụ BERT): Chính xác hơn, nắm bắt được meaning tùy ngữ cảnh, nhưng nặng về tính toán, phức tạp.
Khai thác “last hidden state” hay “pooler output” của BERT: Khi muốn lấy embedding từ BERT, ta có thể lấy vector ẩn tại layer cuối, hoặc Mean Pooling hay [CLS] token (tuỳ mô hình). Chẳng hạn:
BERT gốc dùng vector tại [CLS] như “sentence embedding”, nhưng hiệu quả có thể kém hơn so với Mean Pooling.
Sentence-BERT đã tinh chỉnh cách lấy embedding câu.
Khuyến nghị: Thử Mean Pooling toàn bộ token (hoặc fine-tune mô hình “sentence embedding” chuyên dụng) để có câu embedding tốt hơn.
Fine-tune nếu có đủ dữ liệu:
Nếu bài toán của bạn có sẵn dữ liệu labeled và quan trọng về chất lượng, hãy fine-tune mô hình pre-trained.
Fine-tune có thể cải thiện đáng kể độ chính xác so với chỉ dùng embedding tĩnh hoặc dùng mô hình pre-trained “thô”.
Quản lý OOV (Out-of-Vocabulary):
Với embedding tĩnh (Word2Vec, GloVe), từ mới không có trong từ điển => mô hình không có vector. Cần kỹ thuật fallback (như sử dụng vector trung bình).
Subword embedding (BERT) giảm thiểu vấn đề OOV, vì từ mới được chia nhỏ thành subword.
Kiểm tra trực quan (phân tích PCA, t-SNE)
Để đảm bảo embedding phản ánh tốt, bạn có thể trực quan hoá vector trong không gian 2D/3D.
Ví dụ, các từ/câu cùng chủ đề sẽ gần nhau, các từ/câu khác nghĩa sẽ xa nhau.
3.5.1.4.2.1. Embedding by keras#
Sử dụng tf.keras.layers.Embedding với một số params như sau:
input_dim- The size of the vocabulary (e.g. len(text_vectorizer.get_vocabulary()).output_dim- The size of the output embedding vector, for example, a value of 100 outputs a feature vector of size 100 for each word.embeddings_initializer- How to initialize the embeddings matrix, default is"uniform"which randomly initalizes embedding matrix with uniform distribution. This can be changed for using pre-learned embeddings.input_length- Length of sequences being passed to embedding layer.
from tensorflow.keras import layers
# mỗi 1 token sẽ được embedding thành 1 vector có chiều dài là output_dim
# mỗi 1 sequence được embedding thành 1 tensor có shape là (input_length, output_dim)
# số lượng weights params là (output_dim * input_dim)
embedding = layers.Embedding(
input_dim=max_vocab_length, # set input shape
output_dim=128, # set size of embedding vector
embeddings_initializer="uniform", # default, intialize randomly
input_length=max_sequence_length, # how long is each input
name="embedding_1",
)
embedding(tvect(["water main break disrupts trolley service"]))
<tf.Tensor: shape=(1, 15, 128), dtype=float32, numpy=
array([[[-0.02957509, 0.03379121, 0.04258261, ..., -0.04872347,
-0.00656006, 0.01681853],
[-0.02690672, -0.02275765, -0.01154822, ..., 0.02936261,
0.04035657, 0.01228539],
[ 0.0207009 , 0.00322819, -0.02702802, ..., -0.01606815,
0.00701294, 0.04634335],
...,
[ 0.0172099 , -0.03784468, 0.03696242, ..., -0.03041265,
-0.03056842, 0.0070639 ],
[ 0.0172099 , -0.03784468, 0.03696242, ..., -0.03041265,
-0.03056842, 0.0070639 ],
[ 0.0172099 , -0.03784468, 0.03696242, ..., -0.03041265,
-0.03056842, 0.0070639 ]]], dtype=float32)>
Các giá trị embedding này được khởi tạo bàn đầu ngẫu nhiên, trong quá trình train thì sẽ được learn để tạo ra relationship phù hợp
Visualize the embedding on Embedding Projector
To visualize on Embedding Projector, cần chuẩn bị 2 file bao gồm:
The embedding vector (embedding weights)
the meta data of vector (vocabulary)
Then:
Click on “Load data”
Upload the two files you downloaded (embedding_vectors.tsv and embedding_metadata.tsv)
Explore
Optional: You can share the data you’ve created by clicking “Publish”
# create embedding vector and metadata
import io
# Create output writers
out_v = io.open("embedding_vectors.tsv", "w", encoding="utf-8")
out_m = io.open("embedding_metadata.tsv", "w", encoding="utf-8")
# get vocab and embedding_weight from model
embed_weights = model_1.get_layer("embedding_1").get_weights()[0]
words_in_vocab = model_1.get_layer("text_vectorization_1").get_vocabulary()
# Write embedding vectors and words to file
for num, word in enumerate(words_in_vocab):
if num == 0:
continue # skip padding token
vec = embed_weights[num]
out_m.write(word + "\n") # write words to file
out_v.write(
"\t".join([str(x) for x in vec]) + "\n"
) # write corresponding word vector to file
out_v.close()
out_m.close()