3.6.4. Retrieval-Augmented Generation (RAG)#
3.6.4.1. RAG Foundation#
3.6.4.1.1. RAG Overview#
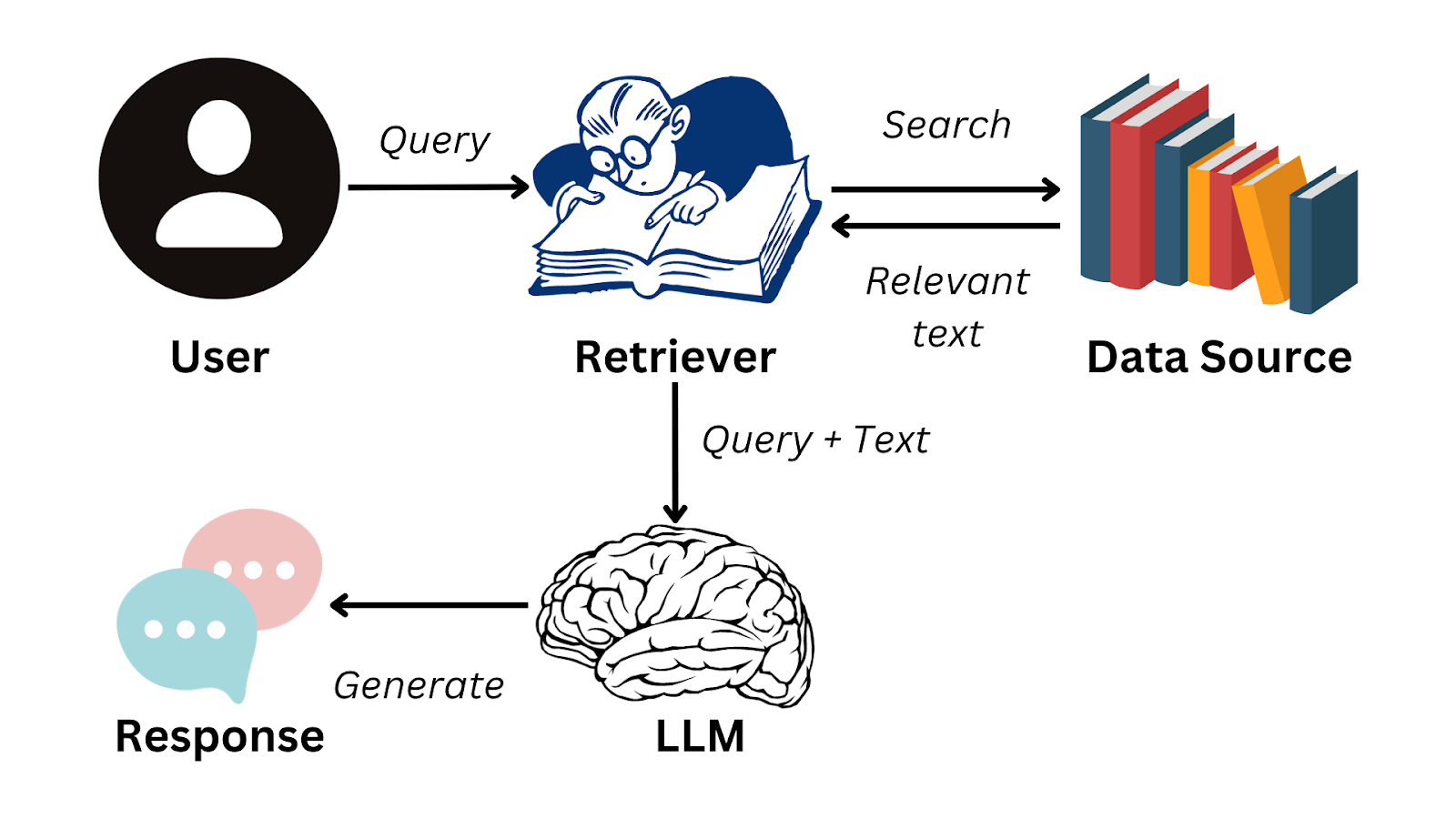
Retrieval-Augmented Generation (RAG) is a model that combines the strengths of retrieval-based and generation-based models. It uses a retriever to find relevant passages from a large corpus of text and a generator to generate the final output. The retriever helps the generator by providing relevant context, which can improve the quality of the generated text.
Boosts the accuracy of the generated text by providing relevant context from a large corpus of text.
Reduce false information
Source Citing: Ability to cite sources in reponses, increase user trust
Integration: Supports frequently updated & domain-specific knowledge integration
Data Source: Private documents, PDFs, Codebase, SQL Database
Cons:
Increased latency due to more text processing
Protential accuracy decline if information is scattered
Inefficient resource usage with large datasets
Factor to consider:
Applications requirements
Acceptable latency
Desired accuracy
Available computational resources
Terms:

RAG Applications:
Hỗ trợ khách hàng qua Chatbot: Sử dụng RAG để truy xuất dữ liệu nội bộ (FAQ, tài liệu sản phẩm…) và tạo câu trả lời tự nhiên, rút ngắn thời gian phản hồi và giải quyết câu hỏi phức tạp.
Phân tích tài liệu pháp lý: Áp dụng RAG để tìm và tóm tắt các điều khoản, tiền lệ quan trọng trong văn bản pháp lý, giúp luật sư nghiên cứu nhanh hơn và chính xác hơn.
Hỗ trợ nghiên cứu khoa học: RAG giúp truy xuất, tổng hợp thông tin từ bài báo, dữ liệu hoặc thí nghiệm khoa học, hỗ trợ rà soát tài liệu, kiểm chứng và khám phá chủ đề phức tạp.
Hỗ trợ quyết định y tế: Ứng dụng RAG để truy xuất hồ sơ bệnh nhân, tài liệu y khoa, hướng dẫn điều trị, cung cấp khuyến nghị chính xác, cập nhật và bảo mật thông tin.
Cá nhân hóa giáo dục: Tận dụng RAG để tìm nội dung học tập phù hợp với trình độ, đưa ra giải thích vừa sức người học, giúp lấp “lỗ hổng” kiến thức hiệu quả.
Tìm kiếm tài liệu kỹ thuật: RAG hỗ trợ rà soát, trích xuất giải pháp từ tài liệu chuyên môn, mã nguồn, hướng dẫn, giúp nhà phát triển và kỹ sư giải quyết vấn đề nhanh chóng và chi tiết.
Tại sao cần RAG?
LLMs are trained on vast amounts of text from books, Wikipedia, websites, and code from GitHub repositories. However, their training data is limited to information available up to a specific date. This means their knowledge is cut off at that date.
Nếu không có RAG:
LLMs cannot answer queries about events or facts that occurred after their training cutoff.
They may generate incorrect or hallucinated responses, making them unreliable for up-to-date information.
Nếu có RAG:
Retrieves relevant content from an external knowledge source (e.g., databases, APIs, or private documents).
Provides the retrieved relevant content as context to the LLM along with query, enabling it to generate factually accurate answers.
Ensures the response is grounded in retrieved information, reducing hallucination.
Thus, RAG enhances LLMs by keeping them updated without requiring frequent retraining.
RAG flow
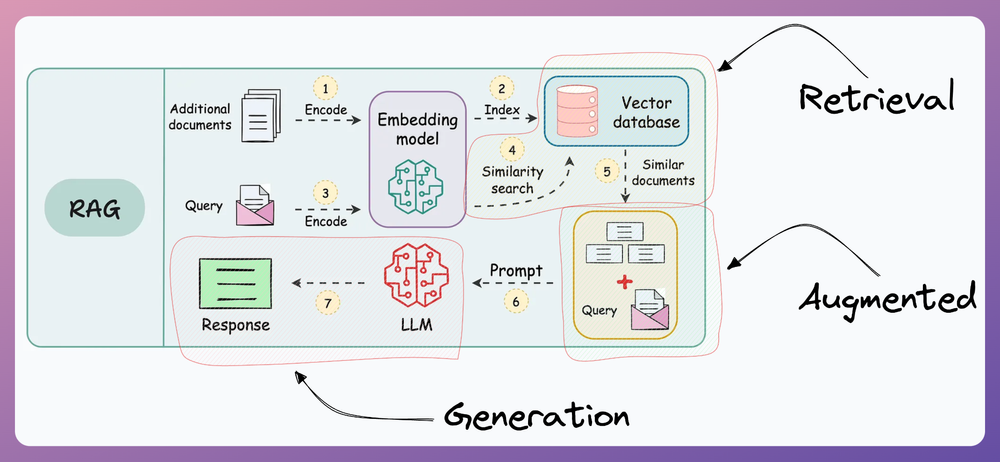
1. Indexing
Indexing in RAG involves processing raw documents by first extracting their content (parsing) and then splitting them into smaller, meaningful chunks. These chunks are then converted into vector embeddings using an embedding model and stored in a vector database, enabling efficient retrieval during query-time.
Parse: Extract raw text from documents (PDFs, web pages, etc.).
Chunk: Split text into smaller, meaningful segments for retrieval.
Encode: Convert chunks into dense vector embeddings using an embedding model.
Store: Save embeddings in a vector database for fast similarity search.

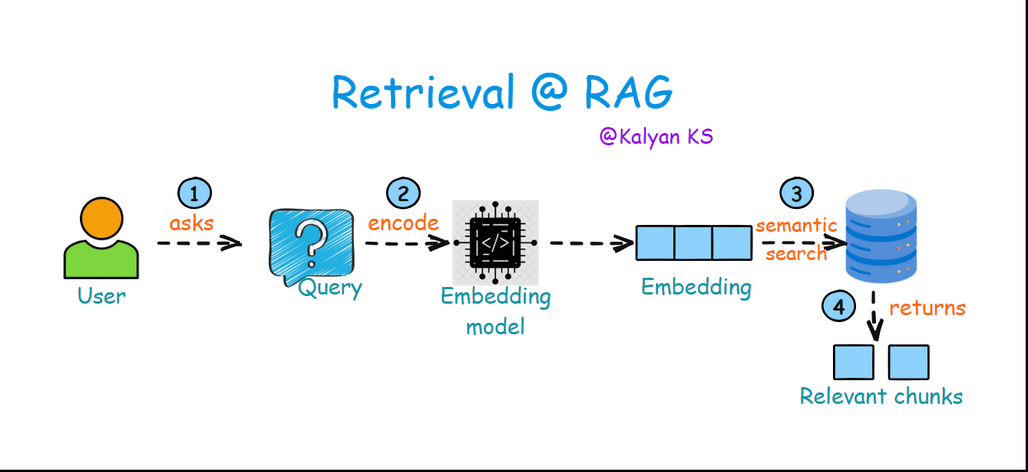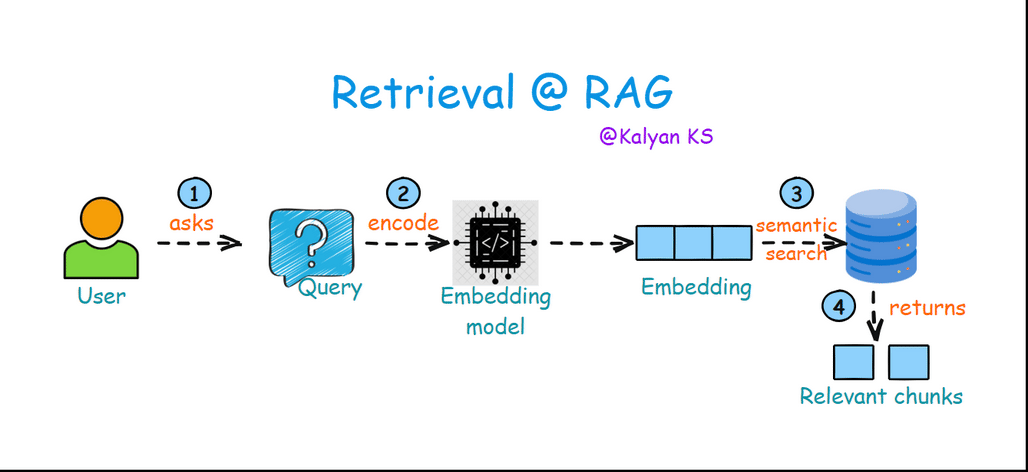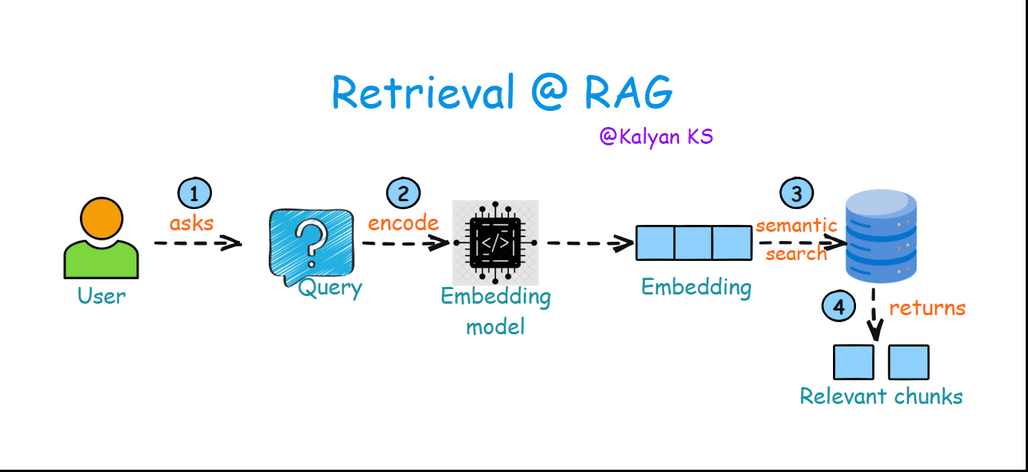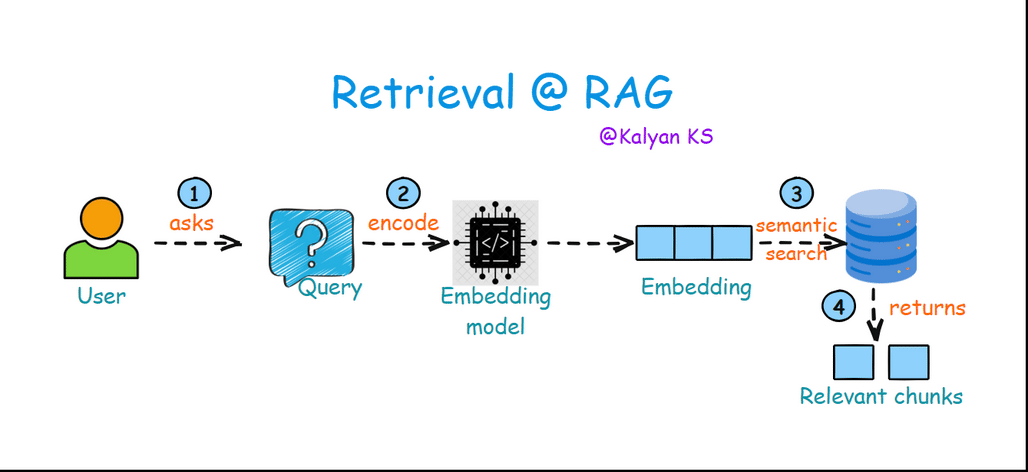
2. Retrieval
The user asks a query which is converted into a dense vector (embedding) using the same embedding model used in indexing step. This vector representation is then used in semantic search to find the most relevant chunks of information from a vector database.
Query: The user inputs a question or prompt.
Encode: The query is converted into a dense vector representation using an embedding model.
Semantic Search: The encoded query is compared against the embeddings in the vector database to find the most relevant embeddings.
Relevant Chunks: The retrieved chunks of text are returned as context for generating a response.
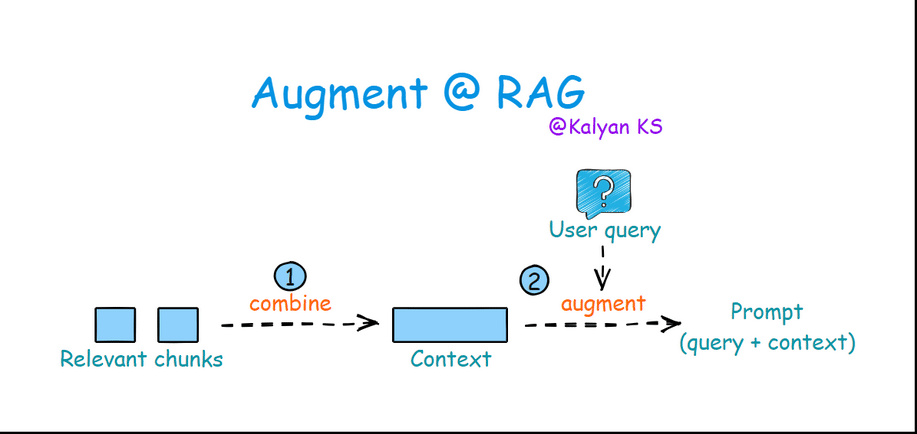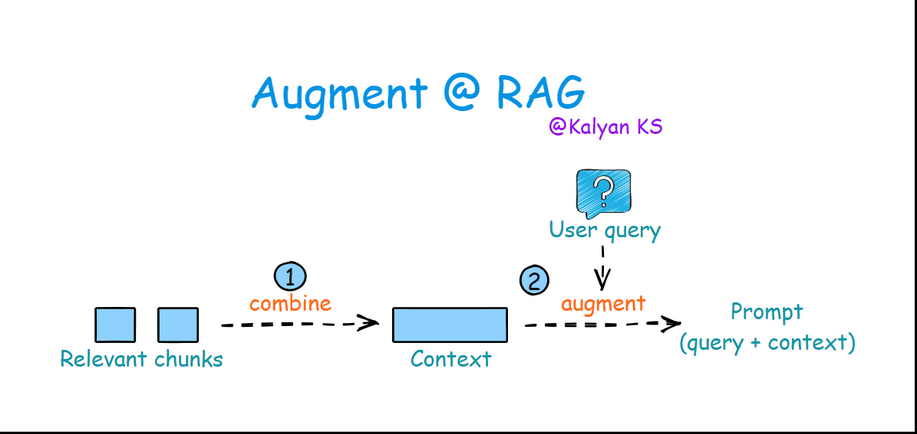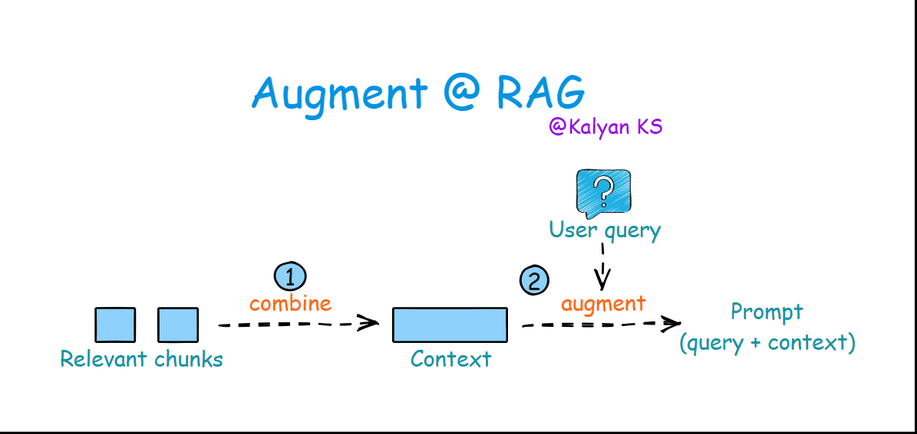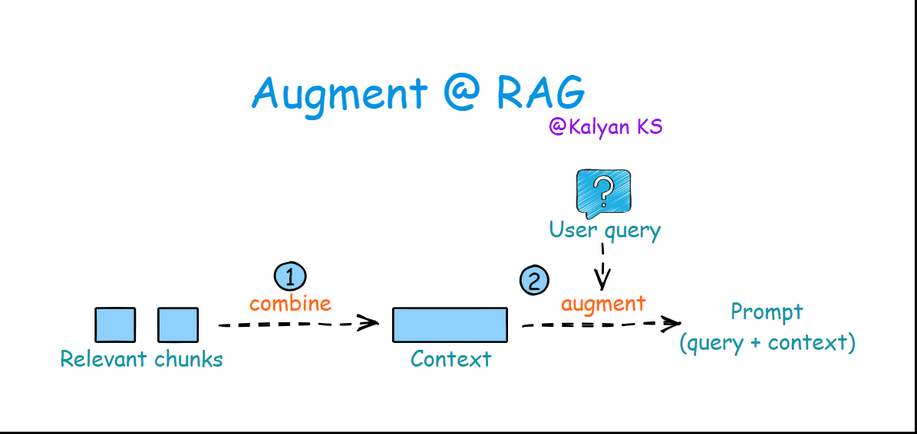
3. Augmentation
In this step, retrieved relevant chunks are combined to form a context. Then the query is merged with this context to construct a prompt for the LLM.
Combine: Relevant chunks are combined to form the context.
Augment: The query is merged with the context to create a prompt for the LLM.
4. Generation
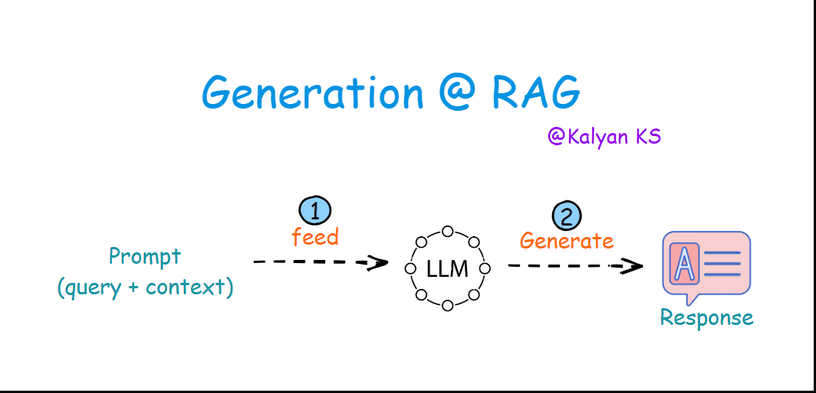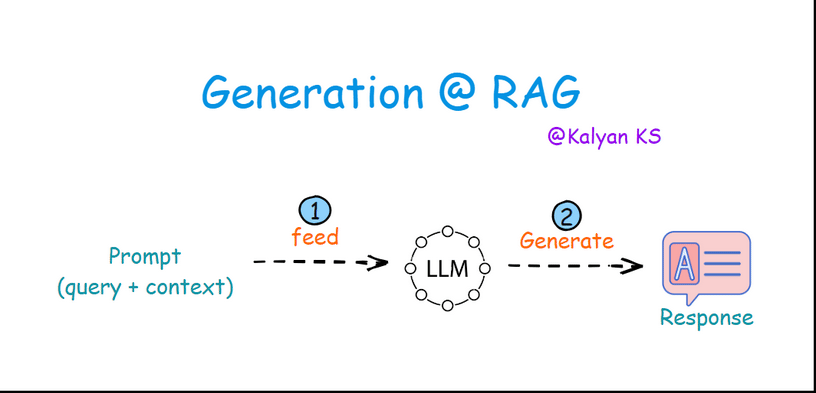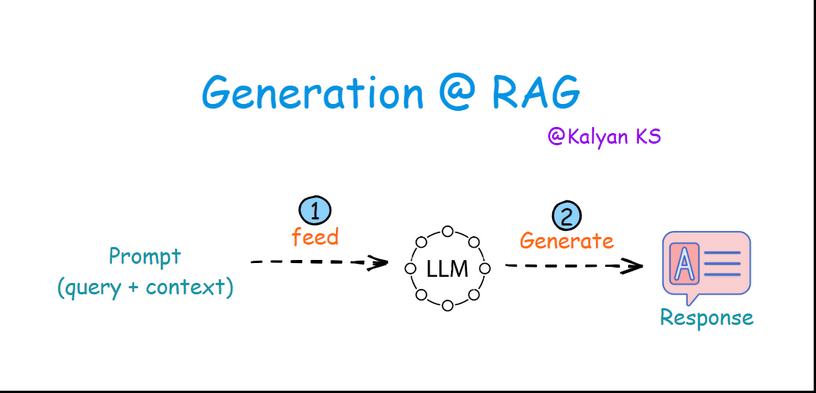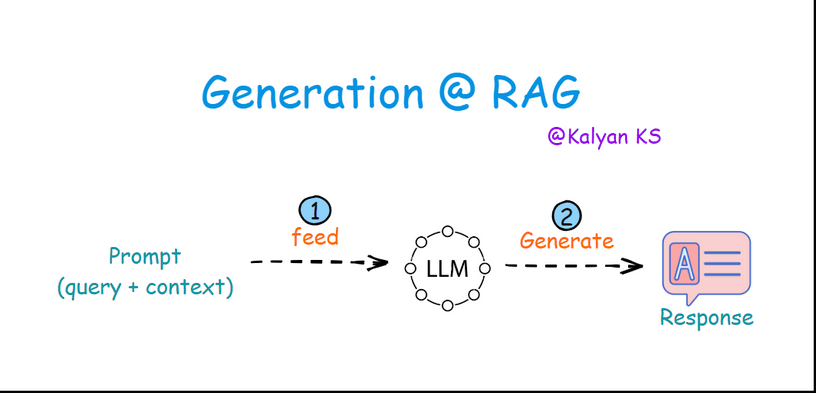
In this step, the prompt is fed to the LLM. The LLM processes the prompt and then generates a response based on both the query and the context.
Feed: The prompt having query and context along with instructions is passed on to the LLM.
Generate: The LLM processes the prompt and generates a response based on both the query and the provided context.
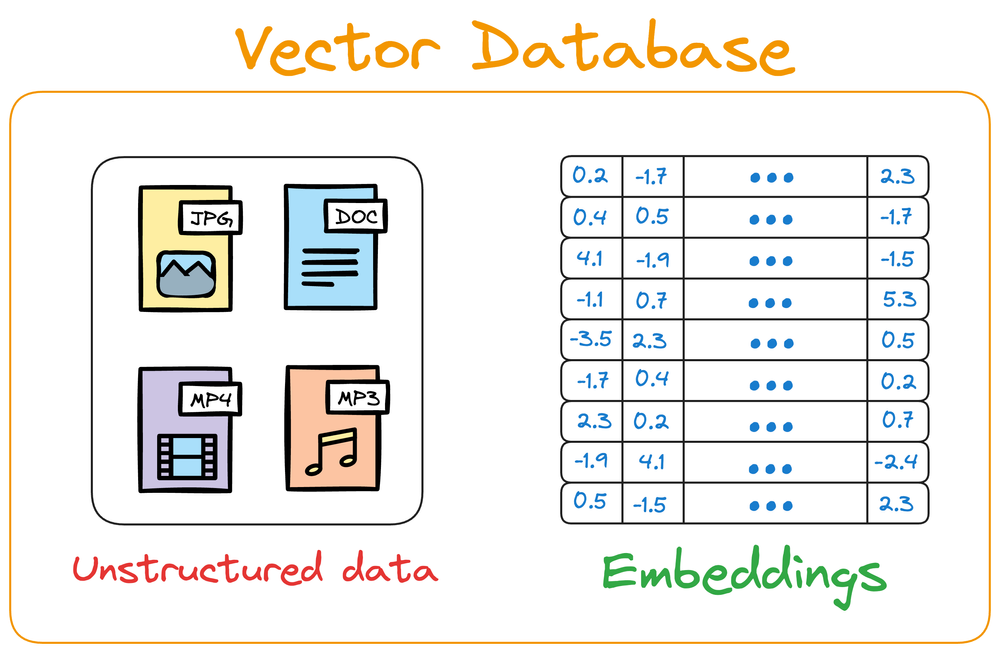
3.6.4.1.2. Vector Database#
Vector database stores unstructured data (text, images, audio, video, etc.) in the form of vector embeddings.
Each data point (whether a word, a document, an image, or any other entity) is transformed into a numerical vector (embeddings) using ML techniques (which we shall see ahead). The model is trained by embeddings in such a way that these vectors capture the essential features and characteristics of the underlying data.
Once stored in a vector database, we can retrieve original objects that are similar to the query we wish to run on our unstructured data. Encoding unstructured data allows us to run many sophisticated operations like similar search, classification,…
Vector databases allow LLMs to look up new information they were not trained on, which is crucial for real-world applications and use it in text generation. (without training the model again)
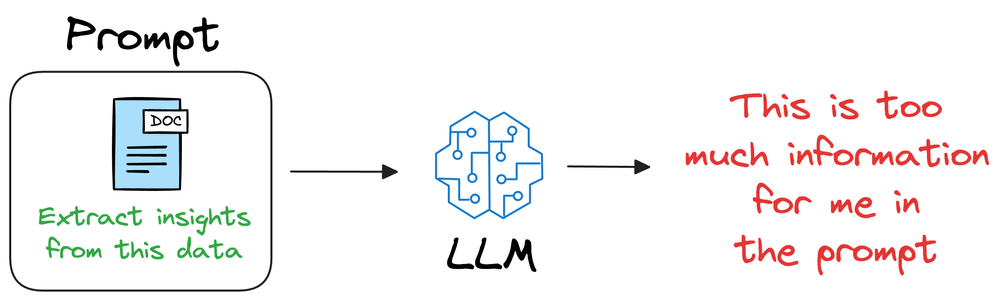
maintain the available information in a vector database by encoding it into vectors using an embedding model, that can be queried by the retriever to find relevant passages for the generator. Then the LLMs needs to access the information, it can query the vector database using an approximate similarity search with the prompt vector to find content that is similar to the input query vector.
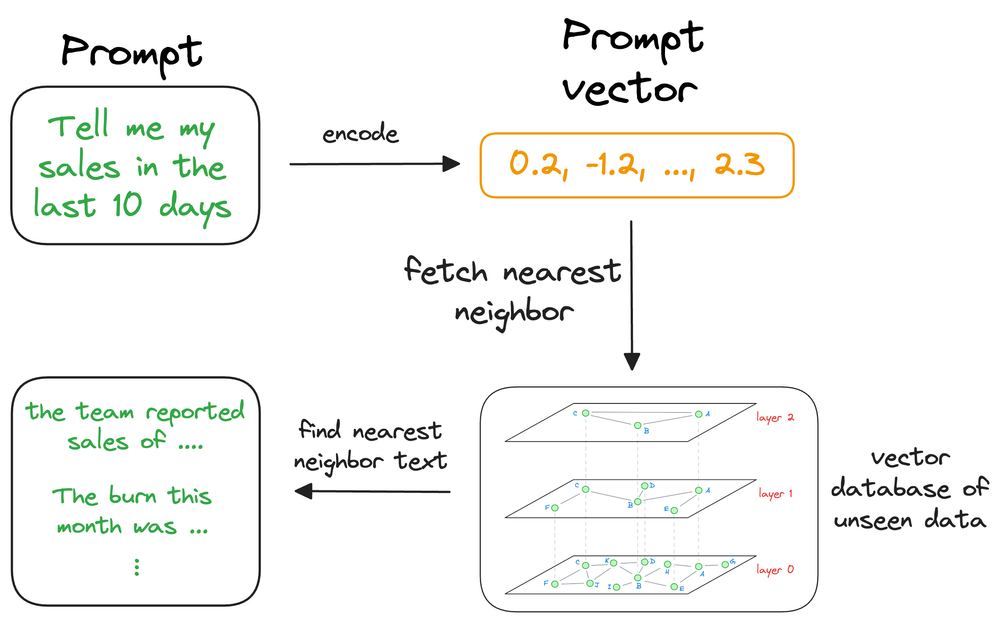
With RAG, the language model can use the retrieved information (which is expected to be reliable) from the vector database to ensure that its responses are grounded in real-world knowledge and context, reducing the likelihood of hallucinations.
makes the model’s responses more accurate, reliable, and contextually relevant
ensuring that we don’t have to train the LLM repeatedly on new data
Vector Database for Embedding systems

Pinecone: Cloud-based semantic search.
Chroma: Lightweight local database.
Faiss: Open-source for nearest neighbor search.
3.6.4.1.3. RAG Roadmap#
Here is the RAG Beginner’s roadmap. This roadmap provides a structured learning path to mastering RAG from basics to deployment. 🚀
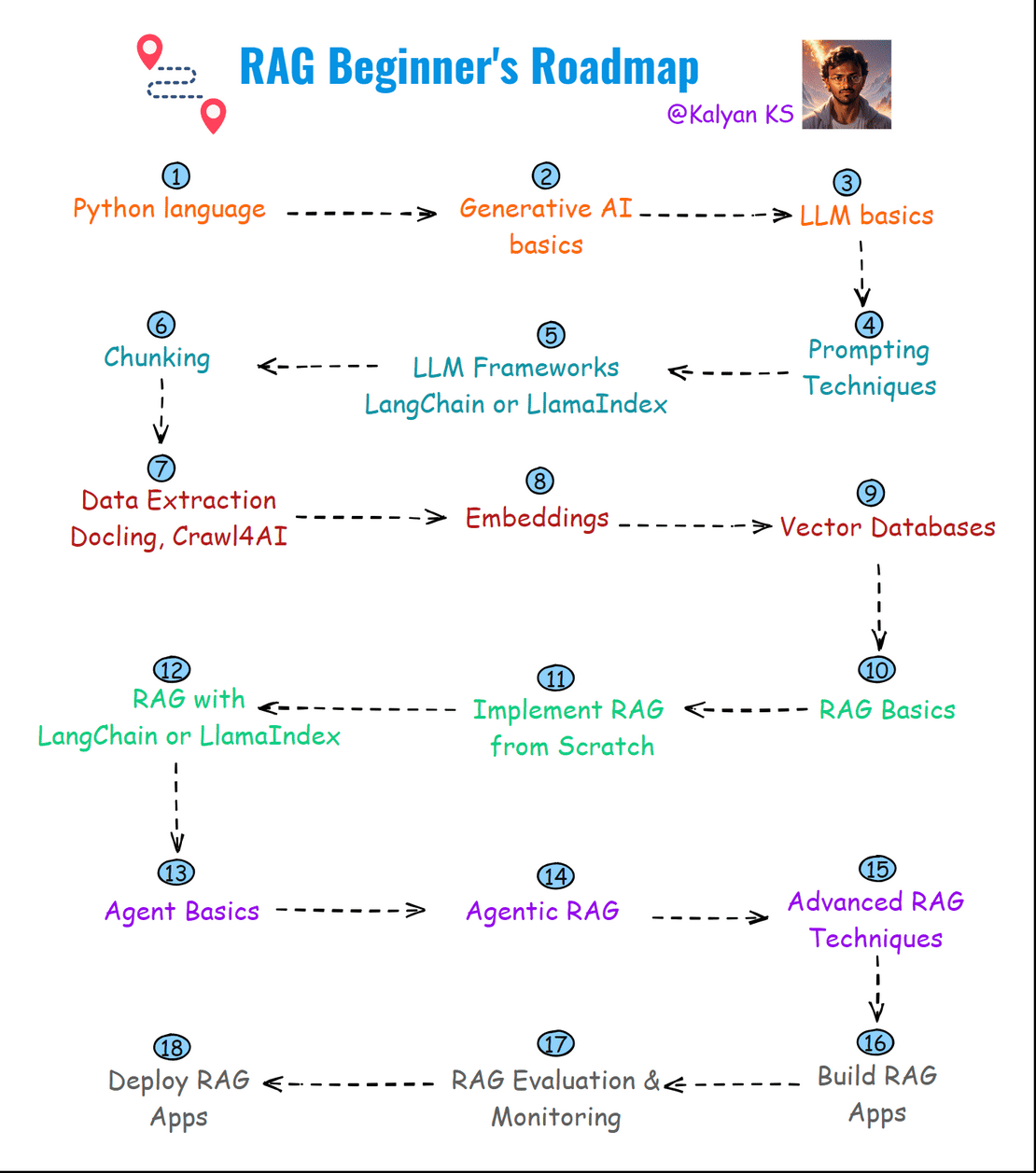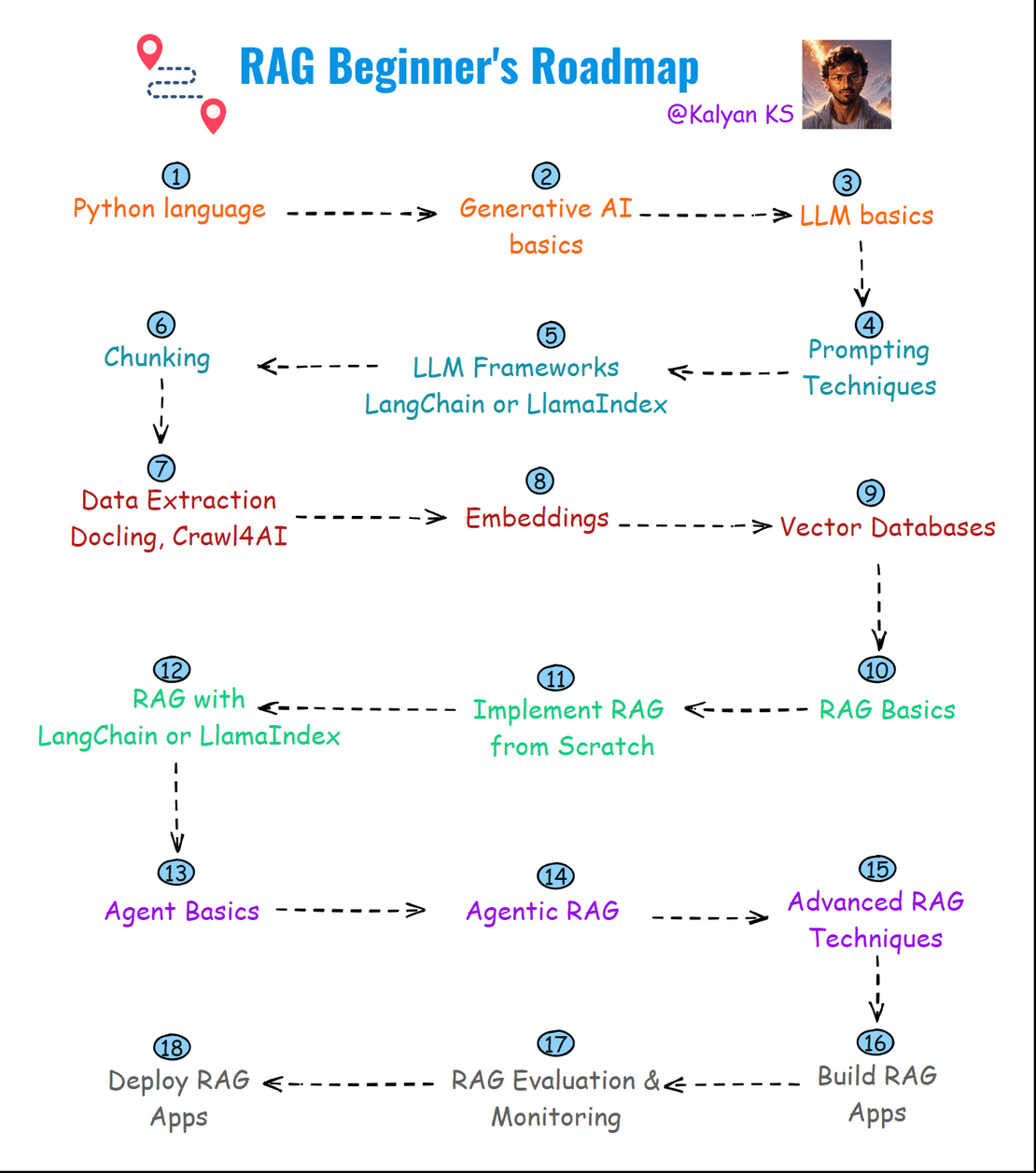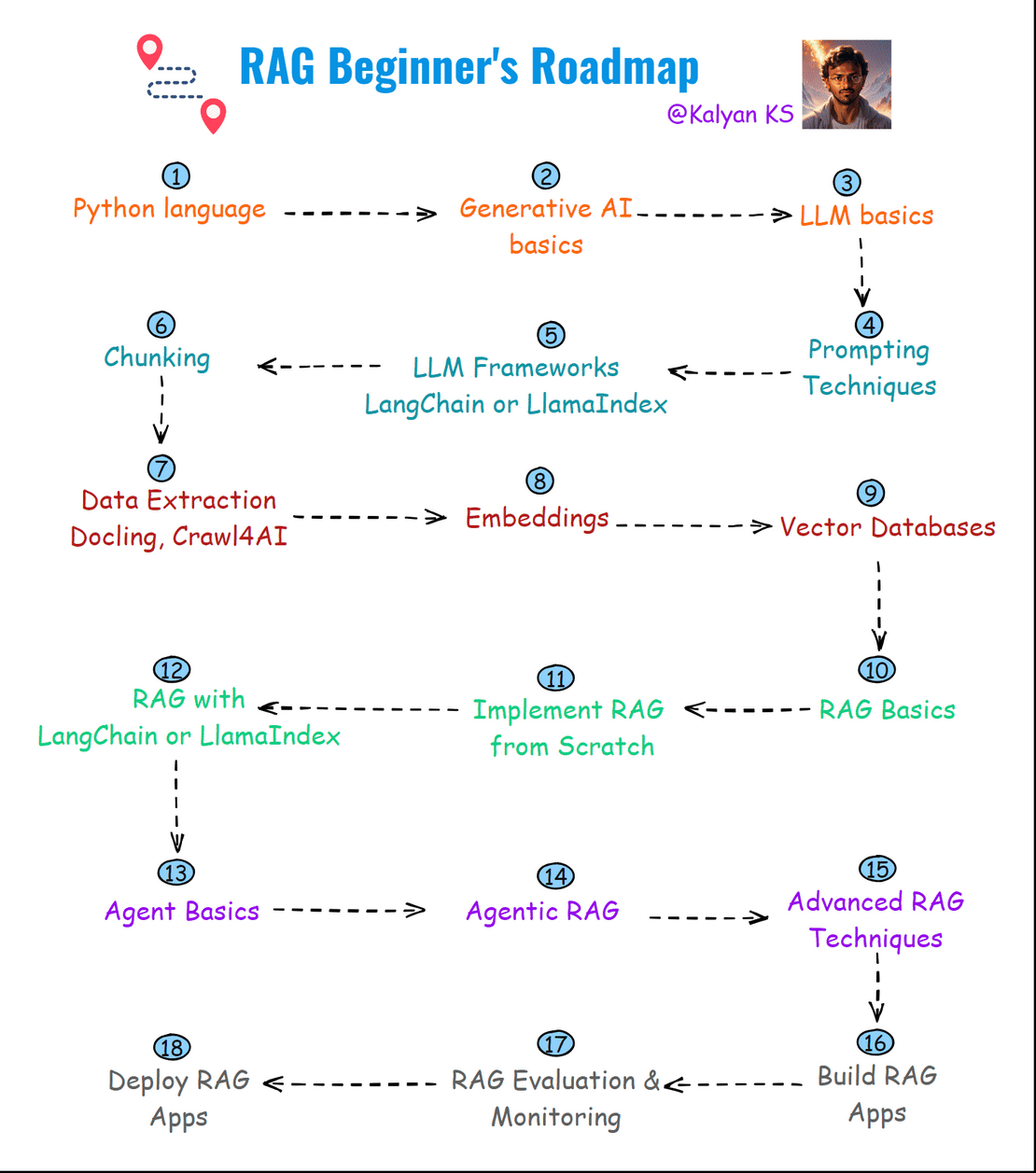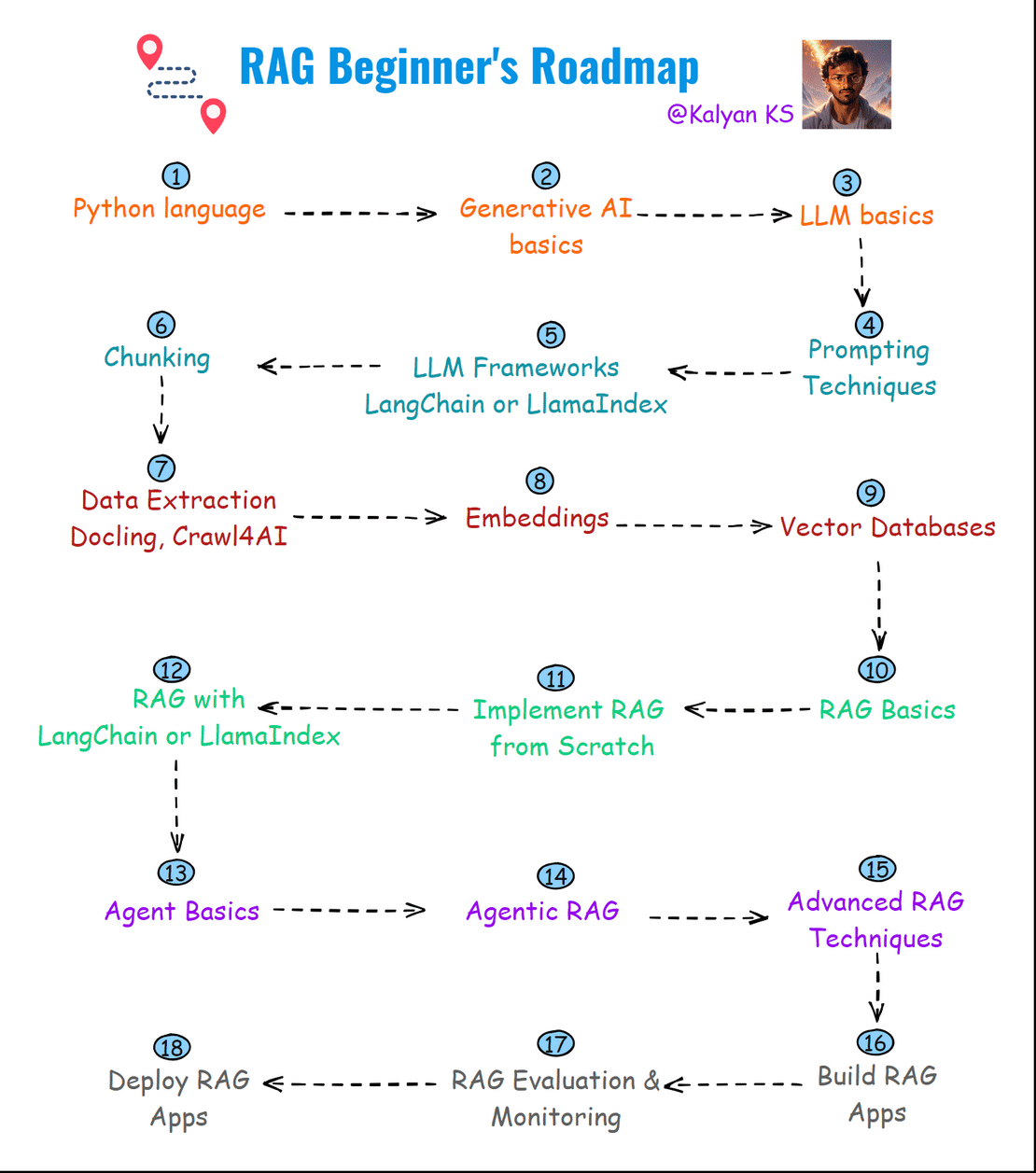
1. Python Programming Language : Python là ngôn ngữ chính cho phát triển RAG nhờ hệ sinh thái AI phong phú. Python cung cấp các thư viện như LangChain, LlamaIndex và sentence-transformers để triển khai một cách trơn tru.
2. Generative AI Basics : Hiểu cách hoạt động của các mô hình AI tạo sinh (generative AI), bao gồm tạo văn bản, tạo hình ảnh và AI đa phương tiện, là rất quan trọng để xây dựng ứng dụng RAG.
3. LLM Basics : Các Large Language Models (LLMs) được huấn luyện trên lượng dữ liệu khổng lồ để tạo ra văn bản giống con người. Hệ thống RAG sử dụng LLM để diễn giải yêu cầu của người dùng và tạo phản hồi dựa trên ngữ cảnh đã truy xuất.
4. Prompt Techniques : Prompting là quá trình cung cấp đầu vào cho LLMs để hướng dẫn phản hồi. Các kỹ thuật như few-shot prompting, zero-shot prompting và chain-of-thought prompting giúp cải thiện chất lượng văn bản được tạo.
5. LLM Frameworks (LangChain hoặc LlamaIndex) : Các framework này cung cấp những chức năng tích hợp sẵn để phát triển ứng dụng RAG.
6. Chunking : Chunking là việc chia nhỏ tài liệu thành các đoạn ngắn để những đoạn liên quan có thể được đưa cho LLM xử lý. Chiến lược chunking có thể là chunking cố định, chunking đệ quy, chunking dạng agentic, chunking theo ngữ nghĩa, v.v.
7. Data Extraction : Trích xuất dữ liệu có cấu trúc từ các tài liệu không cấu trúc (PDF, HTML, văn bản, v.v.) là bước quan trọng để xây dựng kho kiến thức cho RAG.
8. Embeddings : Embeddings chuyển văn bản thành các vector số chiều cao, nắm bắt ý nghĩa ngữ nghĩa. Chúng được dùng cho tìm kiếm tương đồng, truy xuất và gom cụm tài liệu trong hệ thống RAG.
9. Vector Databases : Các cơ sở dữ liệu vector như FAISS, ChromaDB, và Weaviate lưu trữ và truy xuất embeddings một cách hiệu quả. Chúng cho phép tìm kiếm ngữ nghĩa nhanh chóng để xác định những đoạn liên quan cho LLM.
10. RAG Basics : Retrieval-Augmented Generation (RAG) tăng cường LLMs bằng cách truy xuất kiến thức phù hợp trước khi tạo nội dung. Điều này cải thiện độ chính xác, giảm sai lệch (hallucinations) và cho phép cập nhật theo thời gian thực.
11. Implement RAG from Scratch : Xây dựng hệ thống RAG từ đầu liên quan đến thiết kế quy trình truy xuất, chunking, lập chỉ mục, lưu trữ embeddings và cơ chế truy vấn mà không phụ thuộc vào các framework dựng sẵn.
12. Implement RAG with LangChain hoặc LlamaIndex : Các framework này đơn giản hóa việc triển khai RAG bằng cách cung cấp công cụ tích hợp sẵn cho việc tải tài liệu, tạo embeddings, truy xuất và tích hợp LLM.
13. Agent Basics : Agent sử dụng khả năng suy luận, bộ nhớ và các công cụ để tương tác với hệ thống bên ngoài và tự động hóa quy trình phức tạp. Agent được hỗ trợ bởi LLM có thể tự động truy xuất và xử lý dữ liệu động.
14. Agentic RAG : Agentic RAG kết hợp kiến thức truy xuất với khả năng agent tự động. Nó cho phép LLM thực hiện các truy vấn lặp đi lặp lại, tinh chỉnh câu trả lời và thực hiện hành động dựa trên thông tin đã truy xuất.
15. Advanced RAG Techniques : Các kỹ thuật nâng cao bao gồm truy xuất lai (semantic + keyword search), viết lại truy vấn, re-ranking, v.v.
16. Build RAG Apps : Xây dựng ứng dụng RAG trong thực tế bao gồm tích hợp giao diện người dùng (UI), logic backend và cơ sở dữ liệu. Sử dụng Streamlit, FastAPI hoặc Flask để tạo các hệ thống RAG tương tác.
17. RAG Evaluation & Monitoring : Đánh giá mô hình RAG cần các chỉ số như độ chính xác truy xuất, tỷ lệ sai lệch và mức độ liên quan của phản hồi. Các công cụ giám sát như LangSmith giúp phân tích hiệu suất của hệ thống.
18. Deploy RAG Apps : Triển khai ứng dụng RAG đòi hỏi lưu trữ mô hình, cơ sở dữ liệu vector và pipeline truy xuất trên các nền tảng đám mây như AWS, Azure hoặc Google Cloud để đảm bảo khả năng mở rộng.
3.6.4.1.4. RAG Variants#
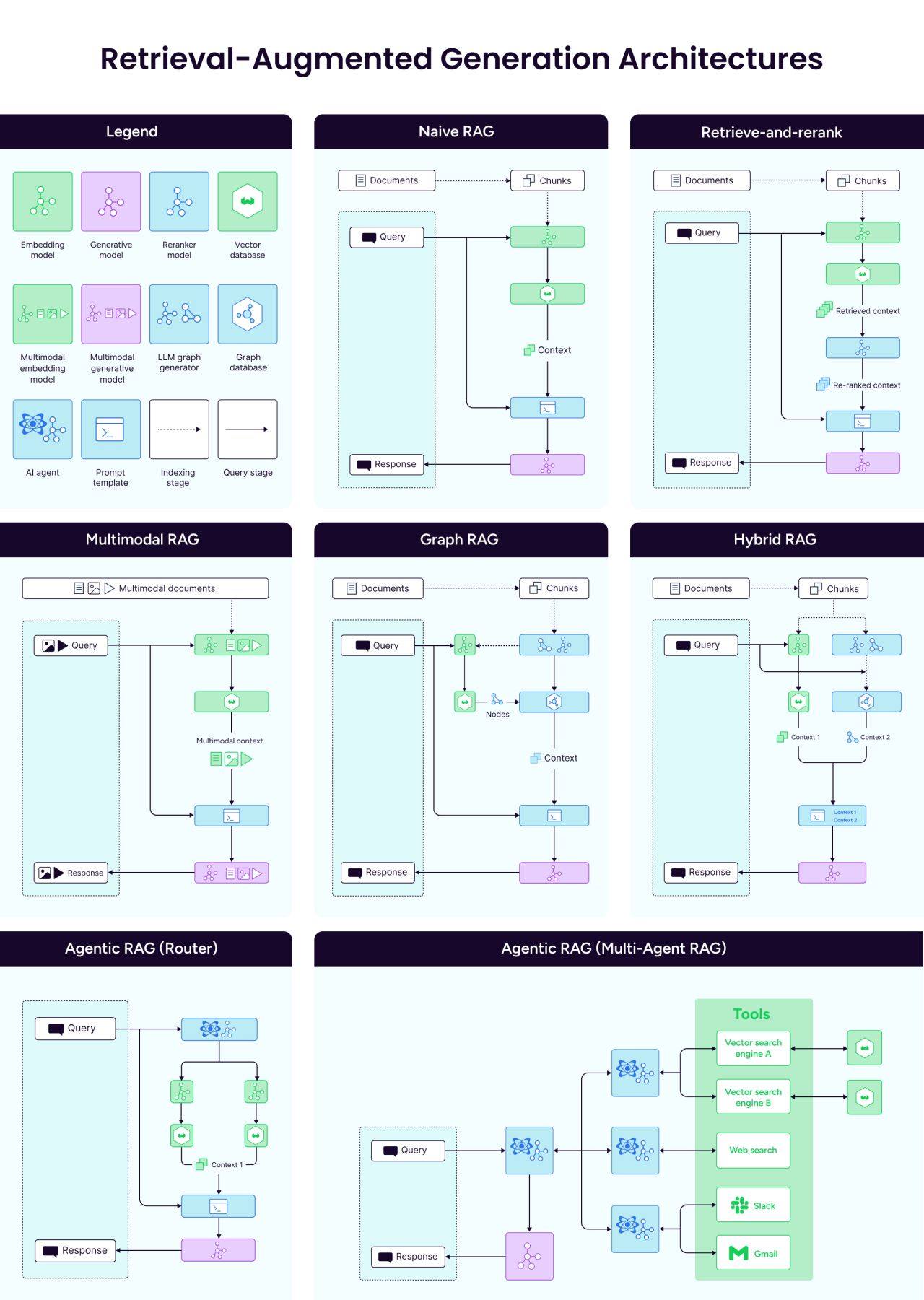
1️⃣ Naive RAG: The Classic Approach: Naive RAG is the standard implementation with a relatively straightforward process:
Query comes in from the user
System retrieves relevant documents from a vector database
Retrieved documents are combined with the query as context
LLM generates a response based on both query and context This works well for many simple applications, like basic Q&A systems or document assistants.
2️⃣ Retrieve and Rerank RAG: This one adds a reranking step after the retrieval to improve response quality:
Initial retrieval returns a larger set of potentially relevant documents
A reranking model evaluates and scores these documents based on relevance
Only the highest-scoring documents are sent to the LLM
3️⃣ Multimodal RAG: The architecture leverages models that can process and retrieve from text, images, audio, video, and other data types.
4️⃣ Graph RAG: Graph RAG uses a graph database to incorporate relationship information between documents:
Documents/chunks are nodes in a graph
Relationships between documents are edges
Can follow relationship paths to find contextually relevant information
5️⃣ Hybrid RAG: Vector DB with Graph DB: This architecture combines both vector search and a graph database:
Vector search identifies semantically similar content
Graph database provides structured relationship data
Queries can leverage both similarity and explicit relationships
Results can include information discovered through relationship traversal
6️⃣ Agentic RAG with Router Agent: A single agent makes decisions about retrieval:
Analyzes the query to determine the best knowledge sources
Makes strategic decisions about how to retrieve information
Coordinates the retrieval process based on query understanding
7️⃣ Multi-Agent RAG: This one employs multiple specialized agents:
Master agent coordinates the overall process
Specialized retrieval agents focus on different tasks
Agents can communicate and collaborate to solve complex problems For example, one agent might retrieve from various sources, another might do data transformation, and a third personalizing the results from the user—all coordinated by a master agent that assembles the final response.
3.6.4.2. RAG Basics#
3.6.4.2.1. RAG Workflow#
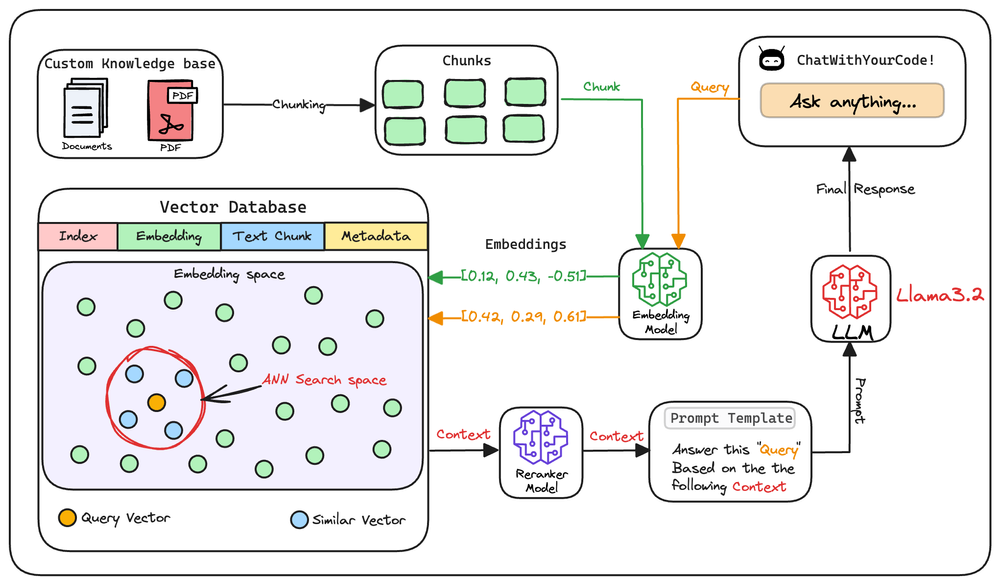
Retrieval: Accessing and retrieving information from a knowledge source, such as a database or memory.
Augmented: Enhancing or enriching something, in this case, the text generation process, with additional information or context.
Generation: The process of creating or producing something, in this context, generating text or language.
Step 1: Data Collection and Indexing
Documents
Financial Statements
Product metadata
FAQ list
Note: Depending on each user group, they will have access to specific types of documents.
Indexing in RAG involves processing raw documents by first extracting their content (parsing) and then splitting them into smaller, meaningful chunks. These chunks are then converted into vector embeddings using an embedding model and stored in a vector database, enabling efficient retrieval during query-time.
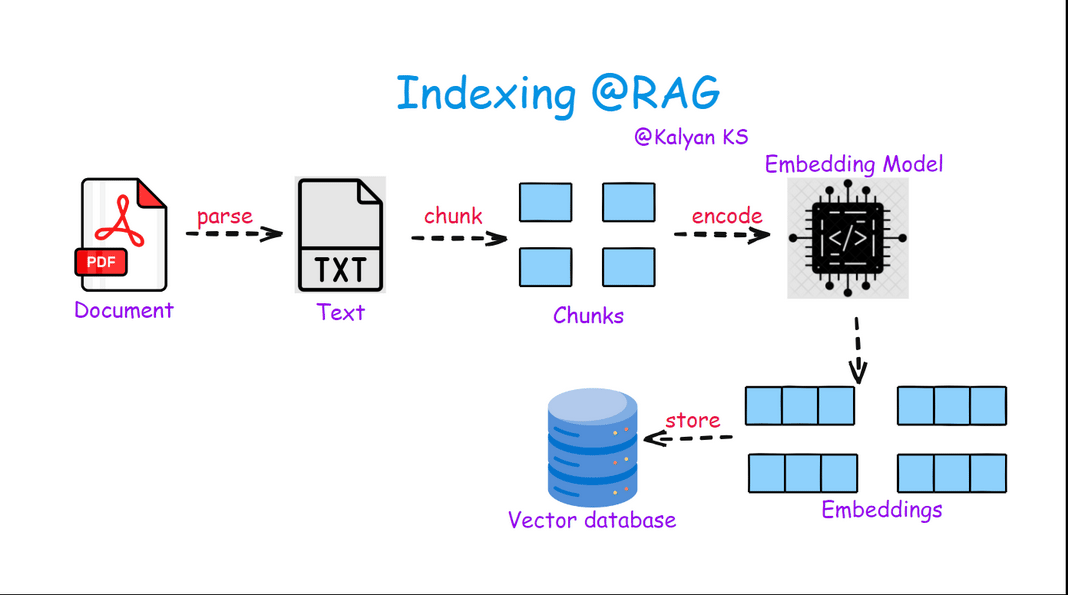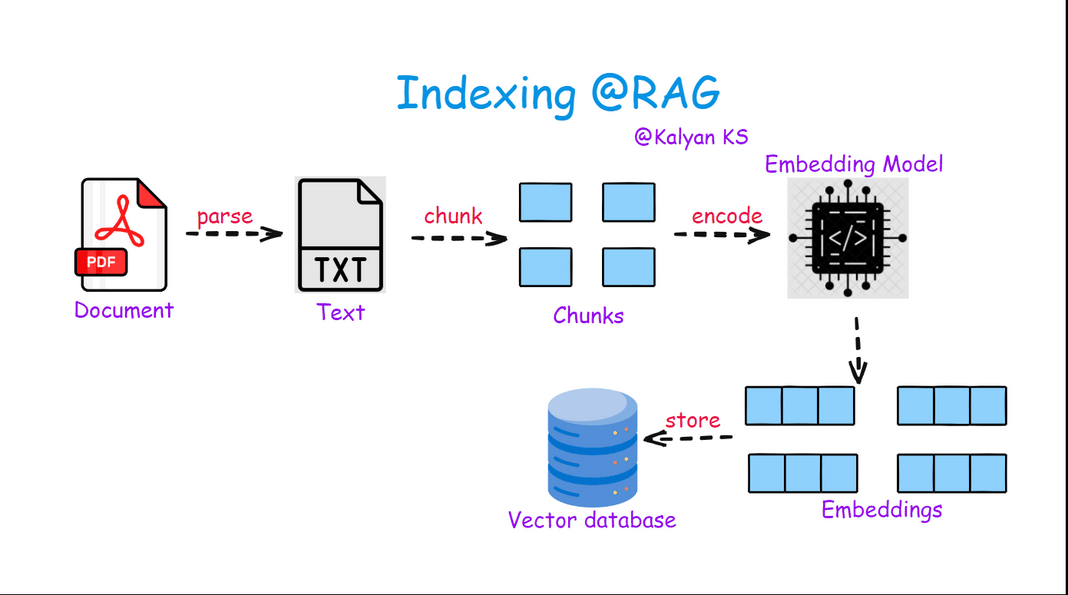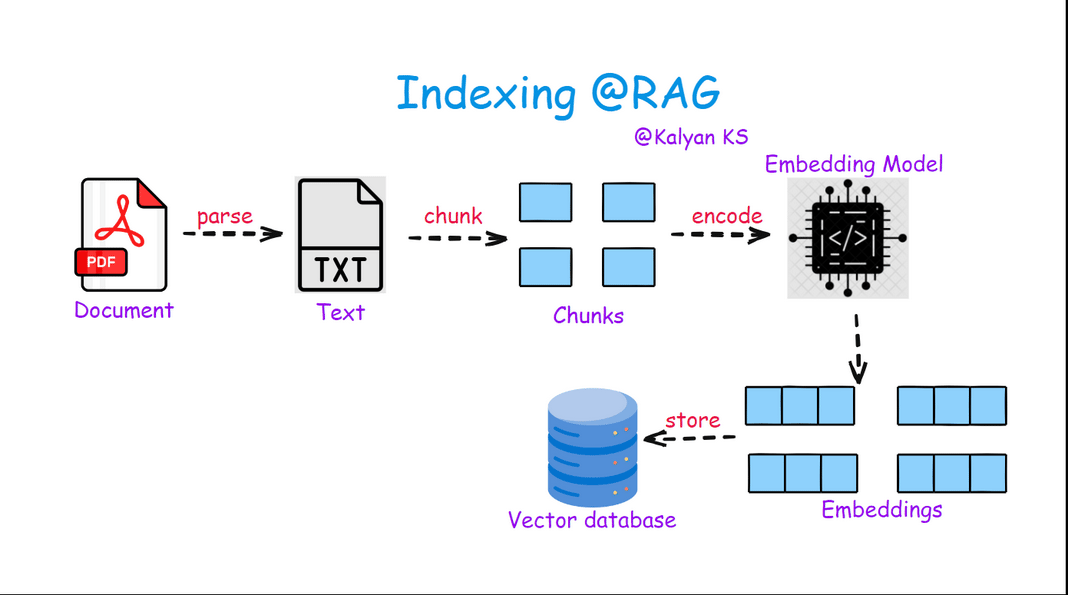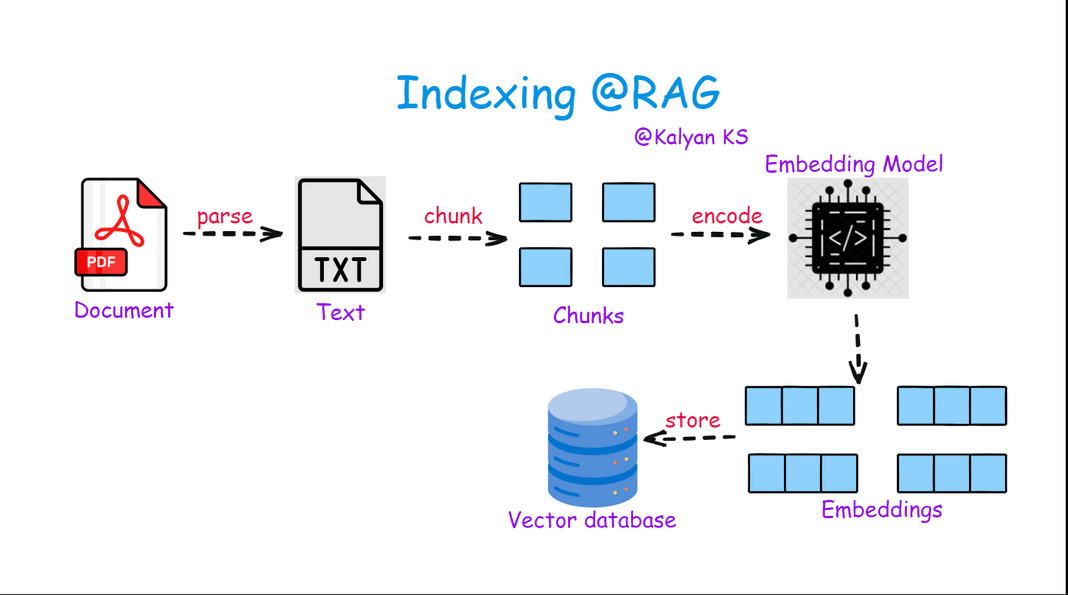
Parse: Extract raw text from documents (PDFs, web pages, etc.).
Chunk: Split text into smaller, meaningful segments for retrieval.
Encode: Convert chunks into dense vector embeddings using an embedding model.
Store: Save embeddings in a vector database for fast similarity search.
Step 2: Data Chunking
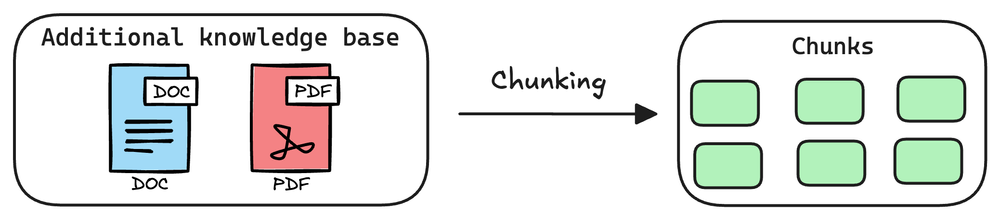
Data Chunking: Breaking down the data into smaller, more manageable pieces or chunks before embedding and storing it in the vector database.
If we don’t chunk, the entire document will have a single embedding, which won’t be of any practical use to retrieve relevant context. In fact, we use only a part of the document to retrieve relevant context.
Benifits:
Efficient retrieval: Retrieving only the relevant chunks of data instead of the entire document, focus on specific information.
Scalability: Handling large volumes of data more efficiently.
Improved accuracy: Ensuring that the retrieved information is contextually relevant to the query.
Chunking Strategy: 5 strategies

Fixed-size chunking (Chia theo độ dài cố định)
Tài liệu được chia thành các đoạn (chunk) có kích thước đều nhau, ví dụ theo số từ hay ký tự cố định.
Ưu điểm: Đơn giản, dễ triển khai.
Nhược điểm: Có thể cắt nội dung quan trọng thành nhiều phần rời rạc.
Semantic chunking (Chia theo ngữ nghĩa)
Dựa vào mức độ tương đồng ngữ nghĩa giữa các đoạn. Khi độ tương đồng giảm mạnh, bắt đầu một đoạn mới.
Ưu điểm: Bảo toàn được mạch nội dung logic.
Nhược điểm: Cần tính toán độ tương đồng (như cosine similarity), phức tạp hơn.
Recursive chunking (Chia đệ quy)
Tách tài liệu lớn thành các đoạn dựa trên tiêu chí (như chủ đề, độ dài), nếu đoạn vẫn quá dài thì tiếp tục tách đệ quy.
Ưu điểm: Kiểm soát kích thước chunk hợp lý hơn, tránh bị quá dài.
Nhược điểm: Quá trình cắt phức tạp, cần lặp lại nhiều bước.
Document structure-based chunking (Chia theo cấu trúc tài liệu)
Chia tài liệu dựa trên cấu trúc sẵn có, ví dụ tiêu đề, mục, chương, phần, v.v…
Ưu điểm: Tận dụng logic phân chia của tài liệu gốc.
Nhược điểm: Phụ thuộc vào tính nhất quán và mức độ chi tiết của cấu trúc tài liệu.
LLM-based chunking (Chia dựa trên mô hình ngôn ngữ)
Dữ liệu được chuyển vào mô hình LLM; mô hình sẽ tự đề xuất cách chia sao cho hợp lý với ngữ cảnh.
Ưu điểm: Khai thác sức mạnh hiểu ngôn ngữ của LLM.
Nhược điểm: Có thể tốn tài nguyên, phụ thuộc vào hiệu suất và chất lượng của mô hình.
Prefer method
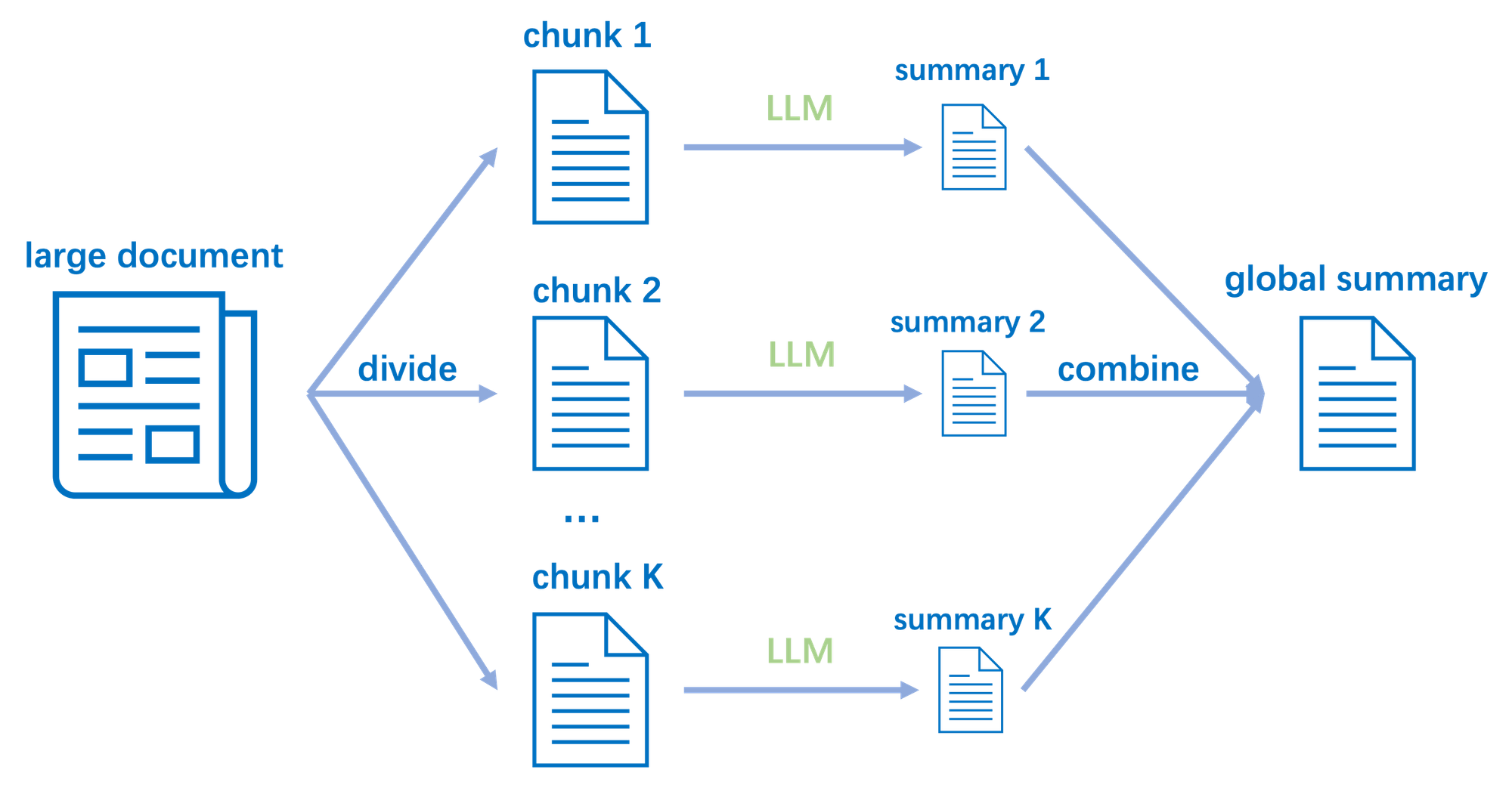
Document-based chunking: Chia theo cấu trúc tài liệu thanh các đoạn nhỏ, mỗi đoạn chứa một phần nội dung liên quan. Ví dụ: chia theo tiêu đề, mục lục, chương, phần, v.v…
Summary by LLM: Tóm tắt nội dung của mỗi đoạn bằng mô hình LLM, rút trích các thông tin quan trọng.
Embedding: Chuyển các đoạn tóm tắt thành vector embeddings, lưu trữ vào cơ sở dữ liệu vector phuc vụ cho việc search truy xuất thông tin from user query. Raw data lưu trữ phuc vụ cho việc get information tạo câu trả lời final.
Step 3: Generate embeddings
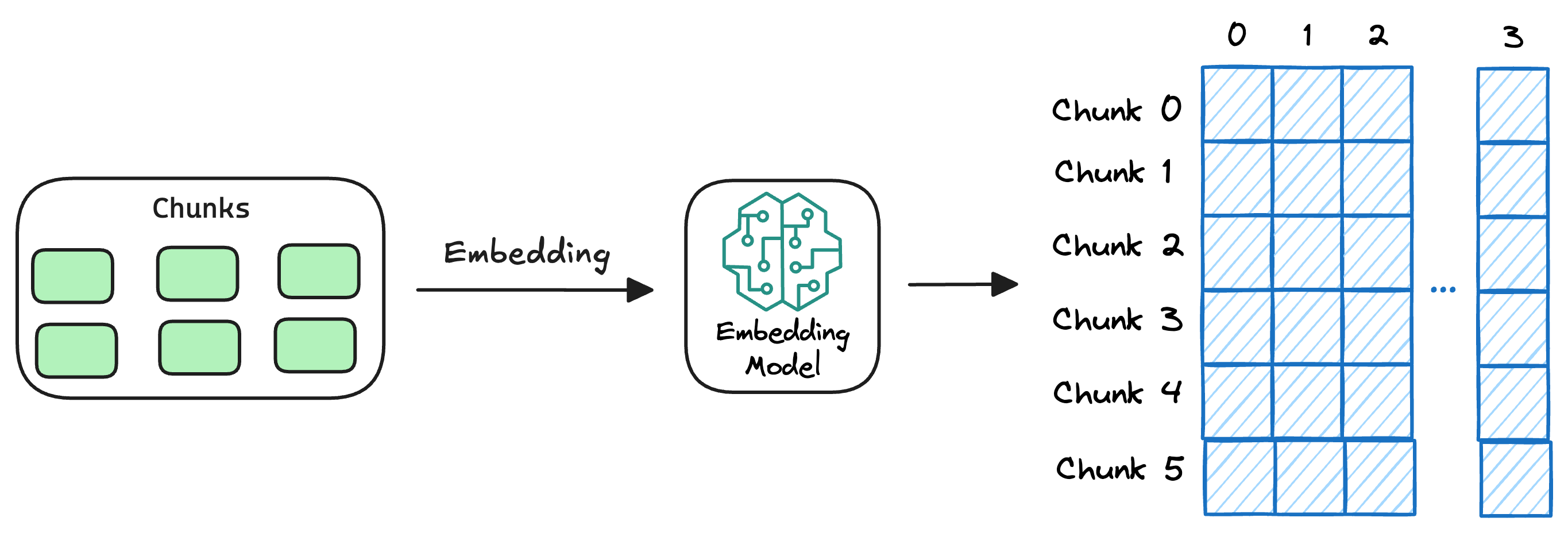
Document Embedding: Transforming the chunks of data into numerical vectors using an embedding model.
Since these are context embedding models (not word embedding models), models like [bi-encoders](https://www.dailydoseofds.com/bi-encoders-and-cross-encoders-for-sentence-pair-similarity-scoring-part-1/ are highly relevant here.
Function: Matches user queries with relevant chunks of data in the vector database.
Outcome: Ensures that the retrieved information is contextually relevant to the query.
Step 4: Store Embedding
These embeddings are then stored in the vector database:
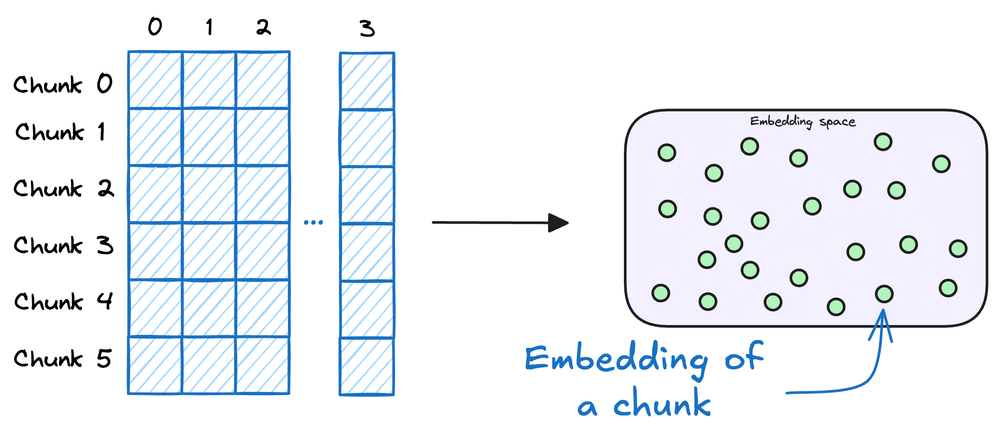
Vector database hoat động như một bo nhớ lưu trữ of RAG system, chứa các vector embeddings của các đoạn thông tin đã được xử lý, bằng cách sử dụng chúng, user query sẽ được truy xuất thông tin từ cơ sở dữ liệu vector.
Vector database lưu trữ cả thông tin gốc (raw data, có thể gồm cả summary sau khi chạy qua LLM) và metadata, indexing, và vector embeddings.
Step 5: Handle User Queries
Process:
Embed the user query using the same embedding model used for the data chunks.
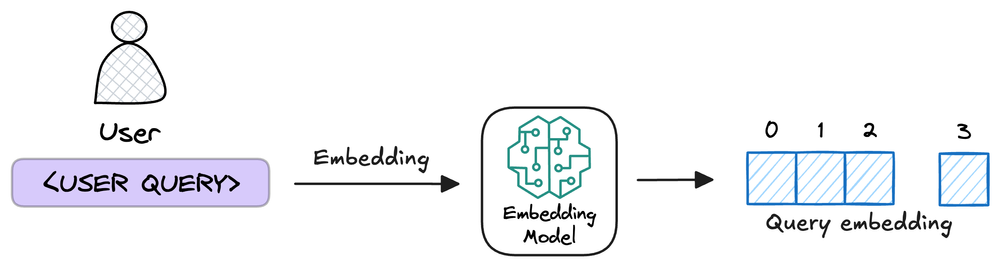
Retrieve the relevant chunks of data from the vector database using the query embedding and similar measures
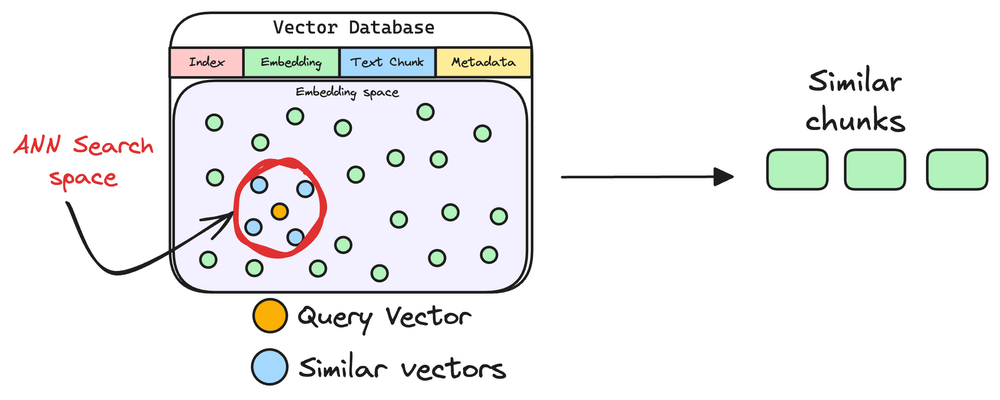
The vectorized query is then compared against our existing vectors in the database to find the most similar information.
The vector database returns the k (a pre-defined parameter) most similar documents/chunks (using approximate nearest neighbor search).
Re-ranking the retrieved chunks based on their relevance to the query.
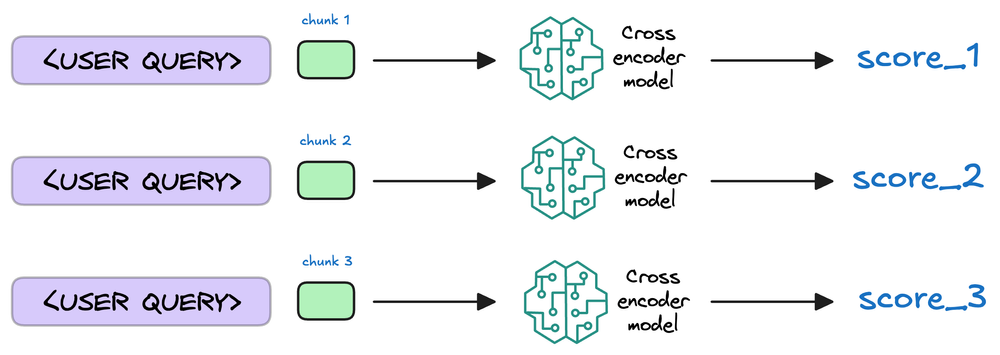
The selected chunks might need further refinement to ensure the most relevant information is prioritized. Model evaluates the initial list of retrieved chunks alongside the query to assign a relevance score to each chunk.
Step 6: Generating Response with LLMs
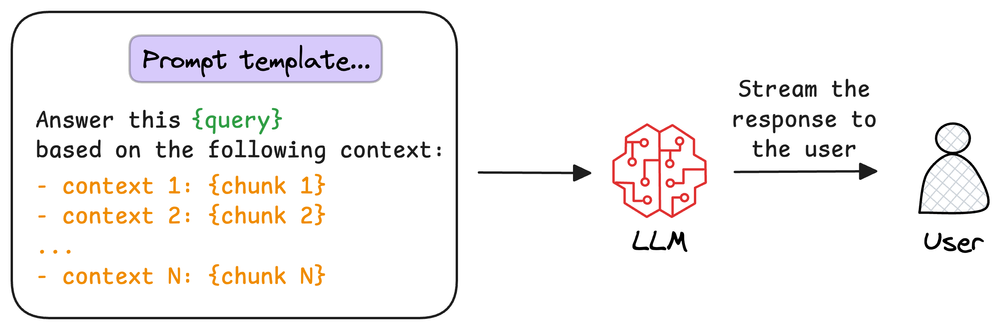
This model combines the user’s original query with the retrieved chunks in a prompt template to generate a response that synthesizes information from the selected documents.This model combines the user’s original query with the retrieved chunks in a prompt template to generate a response that synthesizes information from the selected documents.
Feed the retrieved chunks and the user query to the LLM to generate the final response.
3.6.4.2.2. Data Processing#
3.6.4.2.2.1. Data Ingestion#
Data Ingestion: The process of collecting and importing data from various sources into a system for further processing and analysis. This can include data from databases, APIs, files, or other sources. The goal is to make the data available for analysis, storage, or other purposes.
TextLoader: Handle text files, CSV, JSON, and other formats.URLLoader: Scrape data from websites.PDFLoader: Load data from PDF files.DocxLoader: Load data from Word documents.UnstructuredFileLoader: Load data from various unstructured file formats.Google Drive Loader: Load data (Docs or Entity folders) from Google Drive.
PDF Loader
!pip install -q pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(
r"contents\theory\aiml_algorithms\dl_nlp\llm\data\The One Page Linux Manual.pdf"
)
pages = loader.load_and_split()
pages
[Document(metadata={'producer': 'Acrobat PDFWriter 3.0 for Windows', 'creator': 'Microsoft Word', 'creationdate': 'D:00000101000000Z', 'title': 'The One Page Linux Manual', 'author': 'downloaded from The Quick Reference Site (http://www.digilife.be/quickreferences)', 'keywords': 'Linux Unix Redhat Caldera', 'subject': '(c) 2003 The Quick Reference Site (Tim Sinaeve)', 'moddate': '2003-02-16T13:58:05+01:00', 'source': 'contents\\theory\\aiml_algorithms\\dl_nlp\\llm\\data\\The One Page Linux Manual.pdf', 'total_pages': 2, 'page': 0, 'page_label': '1'}, page_content='THE ONE PAGE LINUX MANUALA summary of useful Linux commands\nVersion 3.0 May 1999 squadron@powerup.com.au\nStarting & Stopping\nshutdown -h now Shutdown the system now and do not\nreboot\nhalt Stop all processes - same as above\nshutdown -r 5 Shutdown the system in 5 minutes and\nreboot\nshutdown -r now Shutdown the system now and reboot\nreboot Stop all processes and then reboot - same\nas above\nstartx Start the X system\nAccessing & mounting file systems\nmount -t iso9660 /dev/cdrom\n/mnt/cdrom\nMount the device cdrom\nand call it cdrom under the\n/mnt directory\nmount -t msdos /dev/hdd\n/mnt/ddrive\nMount hard disk “d” as a\nmsdos file system and call\nit ddrive under the /mnt\ndirectory\nmount -t vfat /dev/hda1\n/mnt/cdrive\nMount hard disk “a” as a\nVFAT file system and call it\ncdrive under the /mnt\ndirectory\numount /mnt/cdrom Unmount the cdrom\nFinding files and text within files\nfind / -name fname Starting with the root directory, look\nfor the file called fname\nfind / -name ”*fname*” Starting with the root directory, look\nfor the file containing the string fname\nlocate missingfilename Find a file called missingfilename\nusing the locate command - this\nassumes you have already used the\ncommand updatedb (see next)\nupdatedb Create or update the database of files\non all file systems attached to the linux\nroot directory\nwhich missingfilename Show the subdirectory containing the\nexecutable file called missingfilename\ngrep textstringtofind\n/dir\nStarting with the directory called dir ,\nlook for and list all files containing\ntextstringtofind\nThe X Window System\nxvidtune Run the X graphics tuning utility\nXF86Setup Run the X configuration menu with\nautomatic probing of graphics cards\nXconfigurator Run another X configuration menu with\nautomatic probing of graphics cards\nxf86config Run a text based X configuration menu\nMoving, copying, deleting & viewing files\nls -l List files in current directory using\nlong format\nls -F List files in current directory and\nindicate the file type\nls -laC List all files in current directory in\nlong format and display in columns\nrm name Remove a file or directory called\nname\nrm -rf name Kill off an entire directory and all it’s\nincludes files and subdirectories\ncp filename\n/home/dirname\nCopy the file called filename to the\n/home/dirname directory\nmv filename\n/home/dirname\nMove the file called filename to the\n/home/dirname directory\ncat filetoview Display the file called filetoview\nman -k keyword Display man pages containing\nkeyword\nmore filetoview Display the file called filetoview one\npage at a time, proceed to next page\nusing the spacebar\nhead filetoview Display the first 10 lines of the file\ncalled filetoview\nhead -20 filetoview Display the first 20 lines of the file\ncalled filetoview\ntail filetoview Display the last 10 lines of the file\ncalled filetoview\ntail -20 filetoview Display the last 20 lines of the file\ncalled filetoview\nInstalling software for Linux\nrpm -ihv name.rpm Install the rpm package called name\nrpm -Uhv name.rpm Upgrade the rpm package called\nname\nrpm -e package Delete the rpm package called\npackage\nrpm -l package List the files in the package called\npackage\nrpm -ql package List the files and state the installed\nversion of the package called\npackage\nrpm -i --force package Reinstall the rpm package called\nname having deleted parts of it (not\ndeleting using rpm -e)\ntar -zxvf archive.tar.gz or\ntar -zxvf archive.tgz\nDecompress the files contained in\nthe zipped and tarred archive called\narchive\n./configure Execute the script preparing the\ninstalled files for compiling\nUser Administration\nadduser accountname Create a new user call accountname\npasswd accountname Give accountname a new password\nsu Log in as superuser from current login\nexit Stop being superuser and revert to\nnormal user\nLittle known tips and tricks\nifconfig List ip addresses for all devices on\nthe machine\napropos subject List manual pages for subject\nusermount Executes graphical application for\nmounting and unmounting file\nsystems'),
Document(metadata={'producer': 'Acrobat PDFWriter 3.0 for Windows', 'creator': 'Microsoft Word', 'creationdate': 'D:00000101000000Z', 'title': 'The One Page Linux Manual', 'author': 'downloaded from The Quick Reference Site (http://www.digilife.be/quickreferences)', 'keywords': 'Linux Unix Redhat Caldera', 'subject': '(c) 2003 The Quick Reference Site (Tim Sinaeve)', 'moddate': '2003-02-16T13:58:05+01:00', 'source': 'contents\\theory\\aiml_algorithms\\dl_nlp\\llm\\data\\The One Page Linux Manual.pdf', 'total_pages': 2, 'page': 1, 'page_label': '2'}, page_content='/sbin/e2fsck hda5 Execute the filesystem check utility\non partition hda5\nfdformat /dev/fd0H1440 Format the floppy disk in device fd0\ntar -cMf /dev/fd0 Backup the contents of the current\ndirectory and subdirectories to\nmultiple floppy disks\ntail -f /var/log/messages Display the last 10 lines of the system\nlog.\ncat /var/log/dmesg Display the file containing the boot\ntime messages - useful for locating\nproblems. Alternatively, use the\ndmesg command.\n* wildcard - represents everything. eg.\ncp from/* to will copy all files in the\nfrom directory to the to directory\n? Single character wildcard. eg.\ncp config.? /configs will copy all files\nbeginning with the name config. in\nthe current directory to the directory\nnamed configs.\n[xyz] Choice of character wildcards. eg.\nls [xyz]* will list all files in the current\ndirectory starting with the letter x, y,\nor z.\nlinux single At the lilo prompt, start in single user\nmode. This is useful if you have\nforgotten your password. Boot in\nsingle user mode, then run the\npasswd command.\nps List current processes\nkill 123 Kill a specific process eg. kill 123\nConfiguration files and what they do\n/etc/profile System wide environment variables for\nall users.\n/etc/fstab List of devices and their associated mount\npoints. Edit this file to add cdroms, DOS\npartitions and floppy drives at startup.\n/etc/motd Message of the day broadcast to all users\nat login.\netc/rc.d/rc.local Bash script that is executed at the end of\nlogin process. Similar to autoexec.bat in\nDOS.\n/etc/HOSTNAME Conatins full hostname including domain.\n/etc/cron.* There are 4 directories that automatically\nexecute all scripts within the directory at\nintervals of hour, day, week or month.\n/etc/hosts A list of all know host names and IP\naddresses on the machine.\n/etc/httpd/conf Paramters for the Apache web server\n/etc/inittab Specifies the run level that the machine\nshould boot into.\n/etc/resolv.conf Defines IP addresses of DNS servers.\n/etc/smb.conf Config file for the SAMBA server. Allows\nfile and print sharing with Microsoft\nclients.\n/etc/X11/XF86Confi\ng\nConfig file for X-Windows.\n~/.xinitrc Defines the windows manager loaded by\nX. ~ refers to user’s home directory.\nFile permissions\nIf the command ls -l is given, a long list of file names is\ndisplayed. The first column in this list details the permissions\napplying to the file. If a permission is missing for a owner,\ngroup of other, it is represented by - eg. drwxr-x—x\nRead = 4\nWrite = 2\nExecute = 1\nFile permissions are altered by giving the\nchmod command and the appropriate\noctal code for each user type. eg\nchmod 7 6 4 filename will make the file\ncalled filename R+W+X for the owner,\nR+W for the group and R for others.\nchmod 7 5 5 Full permission for the owner, read and\nexecute access for the group and others.\nchmod +x filename Make the file called filename executable\nto all users.\nX Shortcuts - (mainly for Redhat)\nControl|Alt + or - Increase or decrease the screen\nresolution. eg. from 640x480 to\n800x600\nAlt | escape Display list of active windows\nShift|Control F8 Resize the selected window\nRight click on desktop\nbackground\nDisplay menu\nShift|Control Altr Refresh the screen\nShift|Control Altx Start an xterm session\nPrinting\n/etc/rc.d/init.d/lpd start Start the print daemon\n/etc/rc.d/init.d/lpd stop Stop the print daemon\n/etc/rc.d/init.d/lpd\nstatus\nDisplay status of the print daemon\nlpq Display jobs in print queue\nlprm Remove jobs from queue\nlpr Print a file\nlpc Printer control tool\nman subject | lpr Print the manual page called subject\nas plain text\nman -t subject | lpr Print the manual page called subject\nas Postscript output\nprinttool Start X printer setup interface\n~/.Xdefaults Define configuration for some X-\napplications. ~ refers to user’s home\ndirectory.\nGet your own Official Linux Pocket Protector - includes\nhandy command summary. Visit:\nwww.powerup.com.au/~squadron')]
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=700, chunk_overlap=100)
texts = text_splitter.split_documents(pages)
print("Preview:")
print(texts[0].page_content)
Preview:
THE ONE PAGE LINUX MANUALA summary of useful Linux commands
Version 3.0 May 1999 squadron@powerup.com.au
Starting & Stopping
shutdown -h now Shutdown the system now and do not
reboot
halt Stop all processes - same as above
shutdown -r 5 Shutdown the system in 5 minutes and
reboot
shutdown -r now Shutdown the system now and reboot
reboot Stop all processes and then reboot - same
as above
startx Start the X system
Accessing & mounting file systems
mount -t iso9660 /dev/cdrom
/mnt/cdrom
Mount the device cdrom
and call it cdrom under the
/mnt directory
mount -t msdos /dev/hdd
/mnt/ddrive
Mount hard disk “d” as a
msdos file system and call
it ddrive under the /mnt
directory
mount -t vfat /dev/hda1
/mnt/cdrive
Mount hard disk “a” as a
VFAT file system and call it
cdrive under the /mnt
directory
umount /mnt/cdrom Unmount the cdrom
Finding files and text within files
find / -name fname Starting with the root directory, look
for the file called fname
find / -name ”*fname*” Starting with the root directory, look
for the file containing the string fname
locate missingfilename Find a file called missingfilename
using the locate command - this
assumes you have already used the
command updatedb (see next)
updatedb Create or update the database of files
on all file systems attached to the linux
root directory
which missingfilename Show the subdirectory containing the
executable file called missingfilename
grep textstringtofind
/dir
Starting with the directory called dir ,
look for and list all files containing
textstringtofind
The X Window System
xvidtune Run the X graphics tuning utility
XF86Setup Run the X configuration menu with
automatic probing of graphics cards
Xconfigurator Run another X configuration menu with
automatic probing of graphics cards
xf86config Run a text based X configuration menu
Moving, copying, deleting & viewing files
ls -l List files in current directory using
long format
ls -F List files in current directory and
indicate the file type
ls -laC List all files in current directory in
long format and display in columns
rm name Remove a file or directory called
name
rm -rf name Kill off an entire directory and all it’s
includes files and subdirectories
cp filename
/home/dirname
Copy the file called filename to the
/home/dirname directory
mv filename
/home/dirname
Move the file called filename to the
/home/dirname directory
cat filetoview Display the file called filetoview
man -k keyword Display man pages containing
keyword
more filetoview Display the file called filetoview one
page at a time, proceed to next page
using the spacebar
head filetoview Display the first 10 lines of the file
called filetoview
head -20 filetoview Display the first 20 lines of the file
called filetoview
tail filetoview Display the last 10 lines of the file
called filetoview
tail -20 filetoview Display the last 20 lines of the file
called filetoview
Installing software for Linux
rpm -ihv name.rpm Install the rpm package called name
rpm -Uhv name.rpm Upgrade the rpm package called
name
rpm -e package Delete the rpm package called
package
rpm -l package List the files in the package called
package
rpm -ql package List the files and state the installed
version of the package called
package
rpm -i --force package Reinstall the rpm package called
name having deleted parts of it (not
deleting using rpm -e)
tar -zxvf archive.tar.gz or
tar -zxvf archive.tgz
Decompress the files contained in
the zipped and tarred archive called
archive
./configure Execute the script preparing the
installed files for compiling
User Administration
adduser accountname Create a new user call accountname
passwd accountname Give accountname a new password
su Log in as superuser from current login
exit Stop being superuser and revert to
normal user
Little known tips and tricks
ifconfig List ip addresses for all devices on
the machine
apropos subject List manual pages for subject
usermount Executes graphical application for
mounting and unmounting file
systems
3.6.4.2.2.2. Text Splitters - Chunking#
Text Splitters: The process of breaking down large text documents into smaller, more manageable chunks or segments. This is important for various applications, such as natural language processing, machine learning, and information retrieval. By splitting text into smaller pieces, it becomes easier to analyze, process, and retrieve relevant information.
Phương pháp Chunking trong RAG phụ thuộc vào loại văn bản:
Fixed-size chunking (chia theo kích thước cố định) cho tài liệu lớn như PDF, Word, v.v…
Recursive chunking (chia đệ quy) phù hợp cho văn bản thông thường
Document structure-based chunking (theo cấu trúc tài liệu) dựa trên tiêu đề cho tài liệu có cấu trúc như Markdown, HTML, v.v…
Semantic chunking (theo ngữ nghĩa) cho văn bản cần tính liên kết ý nghĩa.
LLM-based chunking (dựa trên mô hình ngôn ngữ)
Mức Overlap thường 100-1000 token hoặc 10-20% để tối ưu hóa hiệu suất RAG.
Process:
Breaking text into smaller, semantically meaningful units, such as sentences, paragraphs, or sections. (Cần đảm bảo rằng các đoạn văn bản này vẫn giữ được ngữ nghĩa và ngữ cảnh của tài liệu gốc.)
Aggregating these units into significant segments utils they reach a certain size (Lựa chọn size cho phù hợp)
Isolating the most relevant segments as distinct pieces once the target size is reached.
Repeating the process until some segment overlap to maintain contextual continuity (Các đoạn chunking nên overlap nhau một chút của đoạn trước và sau đó)
document = """
Mở cửa phiên giao dịch sáng nay, lúc 8h15', nhà vàng Mi Hồng đã điều chỉnh giá vàng nhẫn lên mức 96,2 - 97,8 triệu đồng/lượng, tăng 200.000 đồng mỗi lượng so với đầu giờ sáng qua.
Lúc 13h25', giá vàng nhẫn tại Bảo Tín Minh Châu đã tăng lên mức 97,4 - 99,5 triệu đồng. So với đầu giờ sáng, giá vàng nhẫn tăng thêm 600.000 đồng/lượng ở chiều mua vào và 400.000 đồng/lượng ở chiều bán ra.
Giá vàng miếng cũng tăng thêm 500.000 đồng/lượng ở chiều mua vào và 300.000 đồng/lượng ở chiều bán ra, hiện giữ ở mức 97,3 - 98,7 triệu đồng/lượng.
Công ty SJC cũng nâng giá vàng nhẫn lên mức 97 - 98,5 triệu đồng/lượng, tăng 400.000 đồng/lượng ở cả hai chiều mua vào và bán ra.
Cùng mức tăng, giá vàng nhẫn tại DOJI cũng nâng lên mức mức 97,1 - 98,4 triệu đồng/lượng. Giá vàng miếng tại Công ty SJC và DOJI đồng loạt niêm yết ở mức 97,2 - 98,7 triệu đồng/lượng.
"""
3.6.4.2.2.2.1. Fixed-size Chunking#
Token Text Splitter: Tách tài liệu thành các đoạn nhỏ hơn dựa trên số lượng token (từ) trong tài liệu. (Tương tự như tách theo kích thước ký tự, nhưng sử dụng số lượng token thay vì ký tự). Convert text thành BPE token, chia thành những smaller chunks, sau đó recontruct lại thành văn bản.
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size=100, # Kích thước tối đa của mỗi đoạn
chunk_overlap=20, # Số ký tự chồng lấp giữa các đoạn
)
chunks = text_splitter.split_text(document)
chunks
["\nMở cửa phiên giao dịch sáng nay, lúc 8h15', nhà vàng Mi Hồng đã điều chỉnh giá vàng nhẫn lên mức 96,2 - 97,8 triệu đồng",
"�c 96,2 - 97,8 triệu đồng/lượng, tăng 200.000 đồng mỗi lượng so với đầu giờ sáng qua.\n\nLúc 13h25', giá vàng nhẫn t�",
"úc 13h25', giá vàng nhẫn tại Bảo Tín Minh Châu đã tăng lên mức 97,4 - 99,5 triệu đồng. So với đầu giờ sáng, giá vàng nh�",
'u giờ sáng, giá vàng nhẫn tăng thêm 600.000 đồng/lượng ở chiều mua vào và 400.000 đồng/lượng ở chiều bán ra.\n\nGiá vàng mi�',
'� chiều bán ra.\n\nGiá vàng miếng cũng tăng thêm 500.000 đồng/lượng ở chiều mua vào và 300.000 đồng/lượng ở chiều bán ra, hiện g',
'�ng ở chiều bán ra, hiện giữ ở mức 97,3 - 98,7 triệu đồng/lượng.\n\nCông ty SJC cũng nâng giá vàng nhẫn lên mức 97 - 98,5 tri',
' nhẫn lên mức 97 - 98,5 triệu đồng/lượng, tăng 400.000 đồng/lượng ở cả hai chiều mua vào và bán ra.\n\nCùng mức tăng',
'à bán ra.\n\nCùng mức tăng, giá vàng nhẫn tại DOJI cũng nâng lên mức mức 97,1 - 98,4 triệu đồng/lượng. Giá vàng miếng t�',
'ượng. Giá vàng miếng tại Công ty SJC và DOJI đồng loạt niêm yết ở mức 97,2 - 98,7 triệu đồng/lượng.\n']
3.6.4.2.2.2.2. Recursive Chunking#
Recursive Character Text Splitter: Sử dụng split bằng một số ký tự nhất định (ví dụ: dấu chấm, dấu phẩy, dấu cách) để chia tài liệu thành các đoạn nhỏ hơn. Sau đó, nó sẽ kiểm tra xem các đoạn này có quá dài hay không và nếu có, nó sẽ tiếp tục chia chúng thành các đoạn nhỏ hơn cho đến khi đạt được kích thước mong muốn. (bắt đầu với một kích thước lớn và giảm dần kích thước cho đến khi đạt được kích thước mong muốn)
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
length_function=len,
)
chunks = text_splitter.split_text(document)
chunks
["Mở cửa phiên giao dịch sáng nay, lúc 8h15', nhà vàng Mi Hồng đã điều chỉnh giá vàng nhẫn lên mức 96,2 - 97,8 triệu đồng/lượng, tăng 200.000 đồng mỗi lượng so với đầu giờ sáng qua.",
"Lúc 13h25', giá vàng nhẫn tại Bảo Tín Minh Châu đã tăng lên mức 97,4 - 99,5 triệu đồng. So với đầu giờ sáng, giá vàng nhẫn tăng thêm 600.000 đồng/lượng ở chiều mua vào và 400.000 đồng/lượng ở chiều bán ra.",
'Giá vàng miếng cũng tăng thêm 500.000 đồng/lượng ở chiều mua vào và 300.000 đồng/lượng ở chiều bán ra, hiện giữ ở mức 97,3 - 98,7 triệu đồng/lượng.\n\nCông ty SJC cũng nâng giá vàng nhẫn lên mức 97 - 98,5 triệu đồng/lượng, tăng 400.000 đồng/lượng ở cả hai chiều mua vào và bán ra.',
'Cùng mức tăng, giá vàng nhẫn tại DOJI cũng nâng lên mức mức 97,1 - 98,4 triệu đồng/lượng. Giá vàng miếng tại Công ty SJC và DOJI đồng loạt niêm yết ở mức 97,2 - 98,7 triệu đồng/lượng.']
Sử dụng spacy để tách theo câu
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpacyTextSplitter(
chunk_size=300, # Kích thước tối đa của mỗi đoạn
chunk_overlap=50, # Số ký tự chồng lấp giữa các đoạn
)
texts = text_splitter.split_text(document)
texts
["Mở cửa phiên giao dịch sáng nay, lúc 8h15', nhà vàng Mi Hồng đã điều chỉnh giá vàng nhẫn lên mức 96,2 - 97,8 triệu đồng/lượng, tăng 200.000 đồng mỗi lượng so với đầu giờ sáng qua.\n\n\n\nLúc 13h25', giá vàng nhẫn tại Bảo Tín Minh Châu đã tăng lên mức 97,4 - 99,5 triệu đồng.",
'So với đầu giờ sáng, giá vàng nhẫn tăng thêm 600.000 đồng/lượng ở chiều mua vào và 400.000 đồng/lượng ở chiều bán ra.\n\n\n\nGiá vàng miếng cũng tăng thêm 500.000 đồng/lượng ở chiều mua vào và 300.000 đồng/lượng ở chiều bán ra, hiện giữ ở mức 97,3 - 98,7 triệu đồng/lượng.',
'Công ty SJC cũng nâng giá vàng nhẫn lên mức 97 - 98,5 triệu đồng/lượng, tăng 400.000 đồng/lượng ở cả hai chiều mua vào và bán ra.\n\n\n\nCùng mức tăng, giá vàng nhẫn tại DOJI cũng nâng lên mức mức 97,1 - 98,4 triệu đồng/lượng.\n\nGiá vàng miếng tại Công ty SJC và DOJI đồng loạt niêm yết ở',
'mức 97,2 - 98,7 triệu đồng/lượng.']
3.6.4.2.2.2.3. Structured Chunking#
Markdown splitter: Tách tài liệu theo các tiêu đề trong tài liệu Markdown, phân tách bằng headers, code blocks or dividers. (tương tự như tách theo cấu trúc tài liệu)
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_text = "# Tiêu đề 1\n\nMột số văn bản\n\n## Tiêu đề 2\n\nThêm văn bản"
headers_to_split_on = [
("#", "Tiêu đề 1"),
("##", "Tiêu đề 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_chunks = markdown_splitter.split_text(markdown_text)
md_chunks
[Document(metadata={'Tiêu đề 1': 'Tiêu đề 1'}, page_content='Một số văn bản'),
Document(metadata={'Tiêu đề 1': 'Tiêu đề 1', 'Tiêu đề 2': 'Tiêu đề 2'}, page_content='Thêm văn bản')]
Ví dụ cho Source Code:
from langchain_text_splitters import RecursiveCharacterTextSplitter, Language
python_code = "def ham1():\n pass\n\ndef ham2():\n pass"
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=30, chunk_overlap=0
)
code_chunks = python_splitter.split_text(python_code)
code_chunks
['def ham1():\n pass', 'def ham2():\n pass']
3.6.4.2.2.2.4. Semantic Chunking#
Chia nhỏ ngữ nghĩa
!pip install --quiet langchain_experimental langchain_openai
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
from dotenv import find_dotenv, load_dotenv
from langchain.embeddings import HuggingFaceEmbeddings
# load_dotenv(r"contents\theory\aiml_algorithms\dl_nlp\llm\.env")
# Use any open-source embedding model from Hugging Face
# 'sentence-transformers/all-MiniLM-L6-v2' is a lightweight, popular choice
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
semantic_splitter = SemanticChunker(
embeddings,
buffer_size=1,
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=70,
)
chunks = semantic_splitter.split_text(document)
chunks
["\nMở cửa phiên giao dịch sáng nay, lúc 8h15', nhà vàng Mi Hồng đã điều chỉnh giá vàng nhẫn lên mức 96,2 - 97,8 triệu đồng/lượng, tăng 200.000 đồng mỗi lượng so với đầu giờ sáng qua. Lúc 13h25', giá vàng nhẫn tại Bảo Tín Minh Châu đã tăng lên mức 97,4 - 99,5 triệu đồng. So với đầu giờ sáng, giá vàng nhẫn tăng thêm 600.000 đồng/lượng ở chiều mua vào và 400.000 đồng/lượng ở chiều bán ra. Giá vàng miếng cũng tăng thêm 500.000 đồng/lượng ở chiều mua vào và 300.000 đồng/lượng ở chiều bán ra, hiện giữ ở mức 97,3 - 98,7 triệu đồng/lượng. Công ty SJC cũng nâng giá vàng nhẫn lên mức 97 - 98,5 triệu đồng/lượng, tăng 400.000 đồng/lượng ở cả hai chiều mua vào và bán ra.",
'Cùng mức tăng, giá vàng nhẫn tại DOJI cũng nâng lên mức mức 97,1 - 98,4 triệu đồng/lượng. Giá vàng miếng tại Công ty SJC và DOJI đồng loạt niêm yết ở mức 97,2 - 98,7 triệu đồng/lượng.',
'']
3.6.4.2.2.2.5. LLM-based Chunking#
LLM-based chunking: Sử dụng mô hình ngôn ngữ để tự động chia tài liệu thành các đoạn nhỏ hơn dựa trên ngữ nghĩa và ngữ cảnh của văn bản. (sử dụng mô hình LLM để tự động xác định cách chia tài liệu thành các đoạn nhỏ hơn dựa trên ngữ nghĩa và ngữ cảnh của văn bản)
1. LLMChunkizer
Phương pháp này chia tài liệu thành các khối dựa trên số lượng token, sau đó sử dụng LLM (như GPT-4o) để chia nhỏ hơn thành các đoạn chứa ý tưởng hoàn chỉnh, đồng thời xử lý chồng chéo để giữ ngữ cảnh. Tài liệu được chia thành các khối dựa trên số lượng token (ví dụ: 200 token mỗi khối), sau đó LLM được sử dụng để chia mỗi khối thành các đoạn nhỏ hơn, mỗi đoạn chứa một ý tưởng hoàn chỉnh.
Xử lý chồng chéo: Để duy trì ngữ cảnh, hai đoạn cuối từ khối trước được thêm vào đầu khối tiếp theo trước khi phân tích, đảm bảo các ý tưởng liên quan được giữ cùng nhau.
Ưu điểm: Duy trì ngữ cảnh với chồng chéo, dễ điều chỉnh kích thước khối
Nhược điểm: Phụ thuộc vào Prompt, có thể tốn kém hơn
2. Proposition-based chunking
Phương pháp này sử dụng LLM để biến đổi tài liệu thành danh sách các mệnh đề tự chứa, mỗi mệnh đề là một ý nghĩa độc lập, đồng thời giải quyết tham chiếu, sử dụng model Propositionizer (Flan-T5-large). Phương pháp này cải thiện hiệu suất trong các tác vụ QA (hỏi đáp) bằng cách cung cấp thông tin liên quan với mật độ cao, vượt trội so với chia dựa trên đoạn hoặc câu
Ưu điểm: Tạo các đoạn tự chứa, tối ưu cho QA (hỏi đáp), mật độ thông tin cao.
Nhược điểm: Cần mô hình tinh chỉnh, phức tạp hơn để triển khai
3.6.4.2.3. Data Retrieval#
Data Retrieval: The process of accessing and extracting relevant information from a database or knowledge source.
3.6.4.2.3.1. Vector Embedding#
Vector embedding (còn gọi là embeddings) là cách biểu diễn dữ liệu (thường là văn bản, hình ảnh, hoặc âm thanh) dưới dạng các vector số trong không gian nhiều chiều. Những vector này giúp máy tính hiểu và so sánh dữ liệu theo ngữ nghĩa, thay vì chỉ dựa trên các thông tin bề mặt như chuỗi ký tự.
Tìm kiếm ngữ nghĩa (semantic search): Với vector embedding, ta có thể thực hiện tìm kiếm dựa trên ý nghĩa nội dung. Trong RAG (Retrieval-Augmented Generation), thuật toán sẽ tìm được các đoạn văn bản liên quan về mặt ngữ nghĩa để cung cấp cho mô hình.
Tối ưu hóa độ chính xác: Khi lựa chọn các đoạn văn bản liên quan, việc sử dụng vector embeddings cho phép hệ thống RAG đưa ra các kết quả chính xác hơn vì chúng được xếp hạng dựa trên mức độ tương đồng ngữ nghĩa.
Giảm thiểu chi phí tính toán: Tạo embedding và so sánh vector có thể hiệu quả về mặt tính toán hơn so với nhiều phương pháp so khớp dựa trên chuỗi thông thường, đặc biệt khi áp dụng cho dữ liệu lớn.
1. Lựa chọn mô hình embedding phù hợp
Sử dụng các mô hình như BERT-based, Sentence Transformers (Ví dụ: sentence-BERT) hoặc các mô hình LLM có khả năng sinh ra embeddings chất lượng cao.
Cân nhắc giữa mô hình nhỏ (nhanh) và mô hình lớn (chính xác hơn) tuỳ theo yêu cầu về thời gian phản hồi và độ chính xác.
2. Chuẩn hóa và làm sạch dữ liệu
Loại bỏ nội dung nhiễu, trùng lặp, hoặc không liên quan trước khi tạo embedding.
Sử dụng kỹ thuật tokenization, lowercasing, và loại bỏ stopword (nếu phù hợp) để đảm bảo chất lượng embedding.
3. Xác định độ lớn embedding
Cân nhắc kích thước vector embedding để cân bằng giữa chất lượng biểu diễn và khả năng lưu trữ / tốc độ truy xuất.
Embedding quá lớn sẽ tốn tài nguyên và thời gian, nhưng embedding quá nhỏ có thể mất đi nhiều thông tin ngữ nghĩa.
4. Sử dụng chỉ mục vector (Vector Index)
Để hỗ trợ tìm kiếm ngữ nghĩa nhanh và hiệu quả, nên dùng các công cụ chỉ mục vector như Faiss, Annoy, Milvus, v.v.
Tận dụng kỹ thuật Approximate Nearest Neighbor Search (ANN) để giảm độ phức tạp và tăng tốc tìm kiếm.
5. Quản lý và cập nhật embeddings
Thường xuyên cập nhật embeddings khi dữ liệu thay đổi, nhất là trong các ứng dụng cần thông tin mới (tin tức, mạng xã hội, v.v.).
Thiết kế giải pháp tuần tự để tái tạo và tái chỉ mục (re-indexing) một cách hiệu quả, tránh xung đột trong quá trình tìm kiếm.
6. Đo lường chất lượng
Sử dụng các chỉ số như
Recall@K,MRR,nDCG… để đánh giá mức độ phù hợp của kết quả tìm kiếm.Thử nghiệm nhiều mô hình embedding và chiến lược tiền xử lý khác nhau để tìm giải pháp tối ưu.
3.6.4.2.3.2. Similarity Search#
Similarity Search: Calculating the similarity between two vectors (query and document) to determine how closely they are related. This is typically done using distance metrics like KNN or ANN (Approximate Nearest Neighbor) search algorithms.
KNN: K-nearest neighbors, a simple algorithm that finds the k most similar items to a given query based on distance metrics.
ANN: Approximate nearest neighbor search, a more efficient algorithm for finding similar items in high-dimensional spaces, often used in vector databases.
Tiêu chí |
KNN (Exact) |
ANN (Approximate) |
|---|---|---|
Phương pháp |
Tìm kiếm láng giềng gần nhất chính xác |
Tìm kiếm láng giềng gần nhất xấp xỉ |
Độ phức tạp tính toán |
- Thường là \(O(N)\) hay \(O(N \log N)\) cho việc truy vấn |
- Có thể đạt dưới \(\log N\) nhờ cấu trúc index đặc biệt |
Độ chính xác |
- Kết quả chính xác tuyệt đối |
- Kết quả gần đúng, có thể có sai số nhưng thường rất nhỏ |
Tốc độ |
- Chậm hơn khi quy mô dữ liệu lớn |
- Tốc độ truy vấn rất nhanh |
Bộ nhớ |
- Dễ triển khai KNN đơn giản (không index), nhưng tốn công truy vấn |
- Nhiều giải pháp ANN khác nhau, đa phần đòi hỏi tạo index |
Ưu điểm |
- Chính xác cao |
- Tốc độ xử lý nhanh hơn nhiều khi dữ liệu rất lớn |
Hạn chế |
- Thời gian truy vấn dài nếu không có index tốt |
- Kết quả không chính xác tuyệt đối (dù sai số nhỏ) |
Ứng dụng phổ biến |
- Tìm kiếm với bộ dữ liệu nhỏ hoặc trung bình |
- Recommendation systems, tìm kiếm văn bản, hình ảnh ở quy mô lớn |
Use-cases of vector similarity search:
Deduplication
Recommendation systems
Anomaly detection
Reverse image search
Search engines
3.6.4.2.4. Data Generation#
3.6.4.3. Agentic RAG#
3.6.4.4. RAG Evaluation#
3.6.4.5. RAG Advanced#
3.6.4.6. RAG Toolkits#
RAG All-in-one is a guide to building Retrieval-Augmented Generation (RAG) applications. It offers a collection of tools, libraries, and frameworks for RAG systems, with explanations of key components and recommendations for effective implementation.

3.6.4.6.1. Data Processing#
Tools and libraries for ingesting various document formats, extracting text, and preparing data for further processing.
📌Document Ingestor
The process of collecting and importing data from various sources into a system for further processing and analysis. This can include data from databases, APIs, files, or other sources. The goal is to make the data available for analysis, storage, or other purposes, help to extract data from a variety of documents like web pages, PDF, word documents, images, power point presentations etc. Once the data is extracted, the data is chunked, encoded and then stored as embeddings in vector databases.
Library |
Description |
Link |
GitHub Stars 🌟 |
|---|---|---|---|
LangChain Document Loaders |
Comprehensive set of document loaders for various file types |
||
LlamaIndex Parser |
Flexible document parsing and chunking capabilities for various file formats |
||
Docling |
Document processing tool that parses diverse formats with advanced PDF understanding and AI integrations |
||
Unstructured |
Library for pre-processing and extracting content from raw documents |
||
PyPDF |
Library for reading and manipulating PDF files |
||
PyMuPDF |
A Python binding for MuPDF, offering fast PDF processing capabilities |
||
MegaParse |
Versatile parser for text, PDFs, PowerPoint, and Word documents with lossless information extraction |
||
Adobe PDF Extract |
A service provided by Adobe for extracting content from PDF documents |
||
Azure AI Document Intelligence |
A service provided by Azure for extracting content including text, tables, images from PDF documents |







📌Data Extraction - Web Scraping
Library |
Description |
Link |
|---|---|---|
Crawl4AI (Web Scraping) |
Open-source LLM Friendly Web Crawler & Scrapper |
|
ScrapeGraphAI (Web & Document) |
A web scraping Python library that uses LLM and direct graph logic to create scraping pipelines for websites and local documents (XML, HTML, JSON, Markdown, etc.). |
|
Crawlee (Web Scraping) |
A web scraping and browser automation library |
📌Data Extraction - Documents
Library |
Description |
Link |
|---|---|---|
Docling (Document) |
Docling parses documents and exports them to the desired format with ease and speed. |
|
Llama Parse (Document) |
GenAI-native document parser that can parse complex document data for any downstream LLM use case (RAG, agents). |
|
PyMuPDF4LLM (Document) |
PyMuPDF4LLM library makes it easier to extract PDF content in the format you need for LLM & RAG environments. |
|
MegaParse (Document) |
Parser for every type of documents |
|
ExtractThinker (Document) |
Document Intelligence library for LLMs |
📌Chunking
The process of breaking down large text documents into smaller, more manageable chunks or segments. This is important for various applications, such as natural language processing, machine learning, and information retrieval. By splitting text into smaller pieces, it becomes easier to analyze, process, and retrieve relevant information.
Library |
Description |
Link |
|---|---|---|
Chonkie |
RAG chunking library that is lightweight, lightning-fast, and easy to use. The no-nonsense RAG chunking library. This library supports seven different chunking strategies. |
📌Rerankers
The process of re-ranking the retrieved chunks based on their relevance to the query. The selected chunks might need further refinement to ensure the most relevant information is prioritized. Model evaluates the initial list of retrieved chunks alongside the query to assign a relevance score to each chunk.
Library |
Description |
Link |
|---|---|---|
Rerankers |
A lightweight, low-dependency, unified API to use all common reranking and cross-encoder models. Any new reranking models can be added with very little knowledge of the codebase. |
3.6.4.6.2. RAG Frameworks#
📌Research
Library |
Description |
Link |
|---|---|---|
FlashRAG |
A Python Toolkit for Efficient RAG Research. This toolkit includes 36 pre-processed benchmark RAG datasets and 16 state-of-the-art RAG algorithms. |
📌RAG Framework
End-to-end frameworks that provide integrated solutions for building RAG applications, simplify building applications with LLMs by providing in-built tools. These frameworks avoids writing code from scratch and speeds up the LLM application development.
Library |
Description |
Link |
GitHub Stars 🌟 |
|---|---|---|---|
LangChain |
Framework for building applications with LLMs and integrating with various data sources |
||
LlamaIndex |
Data framework for building RAG systems with structured data |
||
Haystack |
End-to-end framework for building NLP pipelines |
||
fastRAG |
Research framework for efficient and optimized retrieval augmented generative pipelines, incorporating state-of-the-art LLMs and Information Retrieval. |
||
Llmware |
Unified framework for building enterprise RAG pipelines with small, specialized models |
||
SmolAgents |
A barebones library for agents |
||
txtai |
Open-source embeddings database for semantic search and LLM workflows |
||
Pydantic AI |
Agent Framework / shim to use Pydantic with LLMs |
||
OpenAI Agent |
A lightweight, powerful framework for multi-agent workflows |







📌Agentic RAG
Library |
Description |
Link |
|---|---|---|
CrewAI |
Framework for orchestrating role-playing, autonomous AI agents. |
|
Agno |
Build AI Agents with memory, knowledge, tools and reasoning. Chat with them using a beautiful Agent UI. |
|
LangGraph |
Build resilient language agents as graphs. |
|
AutoGen |
An open-source framework for building AI agent systems. |
|
R2R |
Agentic Retrieval-Augmented Generation (RAG) with a RESTful API. R2R offers multimodal content ingestion, hybrid search functionality, knowledge graphs, and comprehensive user and document management. |
|
Vectara |
Build Agentic RAG applications. |
📌Graph RAG
Library |
Description |
Link |
|---|---|---|
GraphRAG |
A modular graph-based Retrieval-Augmented Generation (RAG) system. |
|
Nano GraphRAG |
A simple, easy-to-hack GraphRAG implementation. |
|
FastGraph RAG |
Streamlined and promptable Fast GraphRAG framework designed for interpretable, high-precision, agent-driven retrieval workflows. |
3.6.4.6.3. Vector Database#
📌Databases optimized for storing and efficiently searching vector embeddings/text documents. A specialized database that stores and indexes text embeddings as high-dimensional vectors. It enables fast, efficient retrieval of semantically similar content for RAG applications.
Database |
Description |
Link |
GitHub Stars 🌟 |
|---|---|---|---|
LanceDB |
Developer-friendly, embedded retrieval engine for multimodal AI |
||
Pinecone |
Managed vector database for semantic search |
||
MongoDB |
General-purpose document database |
||
Elasticsearch |
Search and analytics engine that can store documents |
||
SQLite-Vec |
A vector search SQLite extension that runs anywhere! |
||
FAISS |
A library for efficient similarity search and clustering of dense vectors. |
||
PGVector |
Open-source vector similarity search for Postgres |
||
Chroma |
The AI-native open-source embedding database. The fastest way to build Python or JavaScript LLM apps with memory! |
||
Qdrant |
High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. |
||
Pincone |
The vector database for machine learning applications. |
||
Weaviate |
Weaviate is a cloud-native, open source vector database that is robust, fast, and scalable. |
||
Milvus |
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search |









3.6.4.6.4. Model LLMs and Embedding#
📌LLM Models
Large Language Models and platforms for generating responses based on retrieved context. Powerful AI models trained on vast text data to generate human-like responses. LLMs forms the core of RAG, enabling natural language understanding and generation.
LLM |
Description |
Link |
|---|---|---|
OpenAI API |
Access to GPT models through API |
|
Claude |
Anthropic’s Claude series of LLMs |
|
Hugging Face LLM Models |
Platform for open-source NLP models |
|
LLaMA |
Meta’s open-source large language model |
|
Mistral |
Open-source and commercial models |
|
Cohere |
API access to generative and embedding models |
|
DeepSeek |
Advanced large language models for various applications |
|
Qwen |
Alibaba Cloud’s large language model accessible via API |
|
Ollama |
Run open-source LLMs locally |
📌Embedding
Models and services for creating vector representations of text. These convert text into numerical vectors, capturing semantic meaning for similarity comparisons. They’re crucial for retrieving relevant documents or chunks in RAG’s retrieval step.
Embedding Solution |
Description |
Link |
|---|---|---|
OpenAI Embeddings |
API for text-embedding-ada-002 and newer models |
|
Sentence Transformers |
Python framework for state-of-the-art sentence embeddings |
|
Cohere Embed |
Specialized embedding models API |
|
Hugging Face Embeddings |
Various embedding models |
|
E5 Embeddings |
Microsoft’s text embeddings |
|
BGE Embeddings |
BAAI general embeddings |
3.6.4.6.5. Observability Monitoring#
📌Tools for monitoring, analyzing, and improving LLM applications.
Library |
Description |
Link |
GitHub Stars 🌟 |
|---|---|---|---|
Langfuse |
Open source LLM engineering platform |
||
Opik/Comet |
Debug, evaluate, and monitor LLM applications with tracing, evaluations, and dashboards |
||
Phoenix/Arize |
Open-source observability for LLM applications |
||
Helicone |
Open source LLM observability platform. One line of code to monitor, evaluate, and experiment |
||
Openlit |
Open source platform for AI Engineering: OpenTelemetry-native LLM Observability, GPU Monitoring, Guardrails, Evaluations, Prompt Management, Vault, Playground |
||
Lunary |
The production toolkit for LLMs. Observability, prompt management and evaluations. |
||
Langtrace |
OpenTelemetry-based observability tool for LLM applications with real-time tracing and metrics |







3.6.4.6.6. Prompt Techniques#
Methods and frameworks for effective prompt engineering in RAG systems.
📌Open Source Prompt Engineering Tools
Library |
Description |
Link |
GitHub Stars 🌟 |
|---|---|---|---|
Prompt Engineering Guide |
Comprehensive guide to prompt engineering |
||
DSPy |
Framework for programming language models instead of prompting |
||
Guidance |
Language for controlling LLMs |
||
LLMLingua |
Prompt compression library for faster LLM inference |
||
Promptify |
NLP task prompt generator for GPT, PaLM and other models |
||
PromptSource |
Toolkit for creating and sharing natural language prompts |
||
Promptimizer |
Library for optimizing prompts |
||
Selective Context |
Context compression tool for doubling LLM content processing |
||
betterprompt |
Testing suite for LLM prompts before production |









📌Documentation & Services
3.6.4.6.7. Evaluation#
📌Tools and frameworks for assessing and improving RAG system performance. It is crucial to assess the performance of RAG applications to understand the merits and the demerits. For this, we have libraries like RAGAS, Giskard, Trulens etc.
Library |
Description |
Link |
Github Stars 🌟 |
|---|---|---|---|
FastChat |
Open platform for training, serving, and evaluating LLM-based chatbots |
||
OpenAI Evals |
Framework for evaluating LLMs and LLM systems |
||
RAGAS |
Ultimate toolkit for evaluating and optimizing RAG systems |
||
Promptfoo |
Open-source tool for testing and evaluating prompts |
||
DeepEval |
Comprehensive evaluation library for LLM applications |
||
Giskard |
Open-source evaluation and testing for ML & LLM systems |
||
PromptBench |
Unified evaluation framework for large language models |
||
TruLens |
Evaluation and tracking for LLM experiments with RAG-specific metrics |
||
EvalPlus |
Rigorous evaluation framework for LLM4Code |
||
LightEval |
All-in-one toolkit for evaluating LLMs |
||
LangTest |
Test suite for comparing LLM models on accuracy, bias, fairness and robustness |
||
AgentEvals |
Evaluators and utilities for measuring agent performance |
||
RAGChecker |
A Fine-grained Framework For Diagnosing RAG. |
||
BeyondLLM |
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems |














3.6.4.7. RAG Survey Papers#
Paper
Paper |
Category |
Link |
|---|---|---|
Retrieval-Augmented Generation for Large Language Models: A Survey |
General |
|
Retrieval-Augmented Generation for Natural Language Processing: A Survey |
General |
|
A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions |
General |
|
Retrieval-Augmented Generation for AI-Generated Content: A Survey |
General |
|
A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models |
General |
|
A Survey on Retrieval-Augmented Text Generation for Large Language Models |
General |
|
Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely |
General |
|
Graph Retrieval-Augmented Generation: A Survey |
Graph RAG |
|
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG |
Agentic RAG |
|
Evaluation of Retrieval-Augmented Generation: A Survey |
Evaluation |
|
Searching for Best Practices in Retrieval-Augmented Generation |
RAG Best Practices |