3.1. Best Practice for Data Engineering#
3.1.1. Get started#
3.1.1.1. Tầm quan trọng của Data Engineering#
Data Engineering là công việc liên quan đến thiết kế, xây dựng, quản lý các hệ thống dữ liệu lớn và phức tạp. Data Engineering có vai trò quan trọng trong việc hỗ trợ các hoạt động phân tích dữ liệu, khoa học dữ liệu và trí tuệ nhân tạo.
Data Engineering giúp tối ưu hóa hiệu năng và chi phí của các hệ thống dữ liệu, giảm thiểu thời gian truy vấn, tăng khả năng mở rộng và tiết kiệm tài nguyên.
Data Engineering giúp đảm bảo chất lượng và tính nhất quán của dữ liệu.
Data Engineering giúp cung cấp dữ liệu cho các bên liên quan một cách an toàn và hiệu quả.
3.1.1.2. Trước khi bắt đầu…#
Trước khi bắt tay vào xây dựng hệ thống dữ liệu, chúng ta cần xem xét đến các yếu tố sau:
Căn chỉnh cấu trúc dữ liệu với chiến lược kinh doanh: Kiến trúc hỗ trợ tầm nhìn, sứ mệnh và mục tiêu của tổ chức, đồng thời phù hợp với các chỉ số hiệu suất (KPI) và các chỉ số đo lường sự thành công của doanh nghiệp.
Xác định tiêu chuẩn và quản trị dữ liệu: Quản trị dữ liệu là tập hợp các chính sách, quy trình, vai trò và trách nhiệm đảm bảo việc sử dụng dữ liệu hiệu quả và hiệu quả trong toàn tổ chức. Tiêu chuẩn và quản trị dữ liệu giúp đảm bảo rằng dữ liệu nhất quán, chính xác, đầy đủ và đáng tin cậy.
Thiết kế cho hệ thống có khả năng mở rộng và linh hoạt: Kiến trúc có khả năng đáp ứng sự tăng trưởng và thay đổi, sự đa dạng, tốc độ và tính xác thực của dữ liệu theo thời gian, có khả năng thích ứng với các yêu cầu và công nghệ kinh doanh đang thay đổi mà không ảnh hưởng đến hiệu suất hoặc chức năng của hệ thống dữ liệu.
Tối ưu hóa hiệu suất và hiệu quả: Kiến trúc dữ liệu sẽ cho phép truy cập dữ liệu nhanh chóng và dễ dàng cho các mục đích khác nhau như phân tích, báo cáo, ra quyết định hoặc quy trình vận hành. Kiến trúc dữ liệu giúp giảm thiểu chi phí và độ phức tạp, tận dụng các công nghệ và kỹ thuật phù hợp để tối ưu hóa việc lưu trữ, xử lý, tích hợp và phân phối dữ liệu.
Trong loạt bài viết này, chúng ta sẽ cùng đi qua toàn bộ quá trình xây dựng hệ thống dữ liệu, từ việc chuẩn bị, thiết kế đến xây dựng hệ thống hoàn chỉnh.
3.1.2. Step 1: Xây dựng kiến trúc và lựa chọn công cụ, framework#
Trong những năm gần đây, kiến trúc cho các nền tảng dữ liệu thay đổi liên tục, các khái niệm mới, phương pháp tiếp cận mới được giới thiệu, phát triển và áp dụng vào thực tế một cách nhanh chóng. Có thể kể đến rất nhiều công nghệ và kỹ thuật được ra mắt chỉ trong vài năm như Lakehouse, Data Fabric, Data Mesh…
Khi xây dựng kiến trúc và chọn lựa công cụ, framework, ta cũng nên cân nhắc, xem xét đến cả các phương pháp mới. Trong thực tế, công sức để phát triển nền tảng dữ liệu ban đầu thường rất nhỏ nếu so sánh với công sức duy trì, vận hành và tiếp tục phát triển các chức năng. Vận dụng những phương pháp hiện đại có thể giúp ta tiết kiệm được chi phí cả về phát triển lẫn vận hành hệ thống.
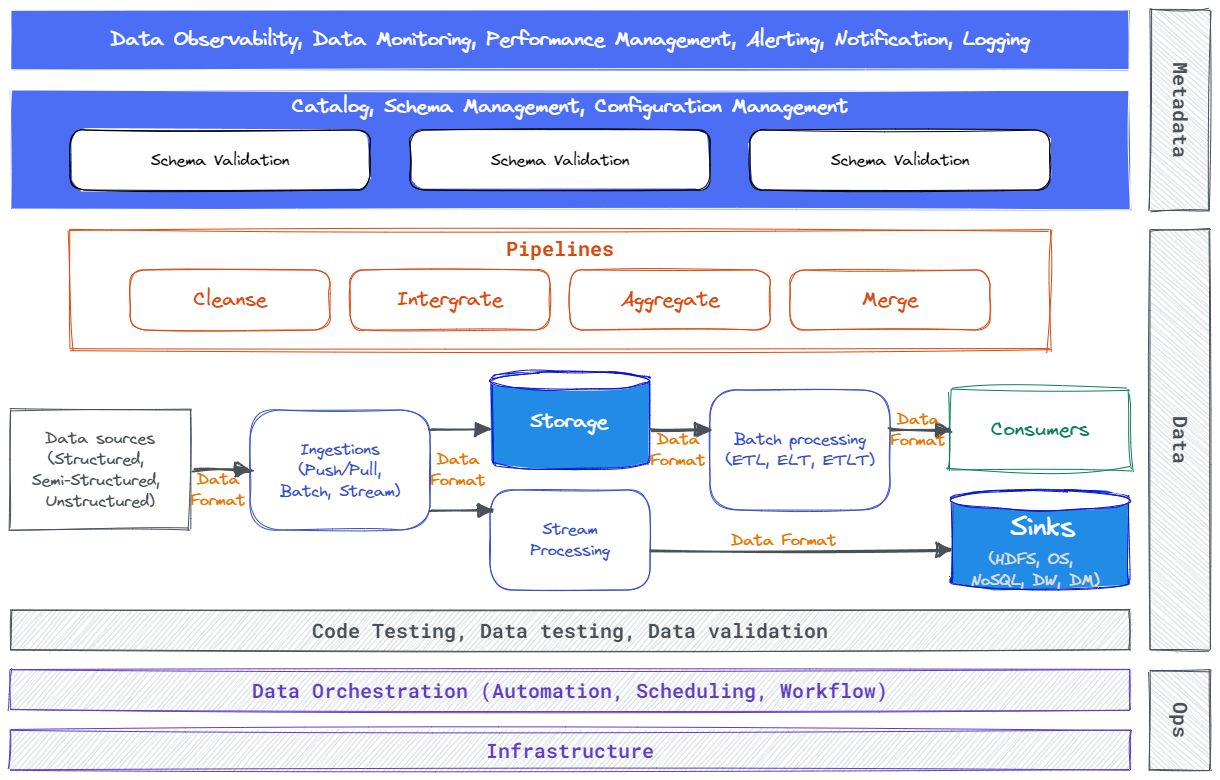
Kiến trúc logical cho hệ thống dữ liệu
3.1.2.1. 1. Nguyên tắc khi xây dựng và lựa chọn công cụ#
Khi xây dựng và chọn lựa công cụ cho nền tảng dữ liệu, cần chú ý những nguyên tắc sau đây:
Linh hoạt: Sự linh hoạt của kiến trúc là điều cần thiết cho bất kỳ nền tảng dữ liệu nào cần có khả năng theo kịp nhu cầu thay đổi của doanh nghiệp. Hệ thống phải được mô-đun hoá để có thể thêm hoặc bớt các thành phần khi cần. Điều này sẽ giúp việc điều chỉnh dễ dàng hơn với những thay đổi phát sinh. Ta có thể thực hiện bằng cách tích hợp nhiều công cụ vào nền tảng một cách đồng thời như Spark, Flink và Beam. Để làm hệ thống linh hoạt, cần tận dụng tối đa khả năng của Serverless, nó sẽ giúp giảm chi phí, cải thiện khả năng mở rộng và đơn giản hóa việc quản lý. Serverless cũng giúp cải thiện khả năng mở rộng bằng cách tự động tăng hoặc giảm quy mô tài nguyên dựa trên nhu cầu. Điều này có thể giúp đảm bảo rằng nền tảng dữ liệu của bạn luôn hoạt động, ngay cả trong thời kỳ nhu cầu cao nhất.
Tách rời xử lý dữ liệu khỏi hạ tầng: Tách rời hạ tầng và xử lý dữ liệu là một cách thiết kế giúp hệ thống trở nên linh hoạt và có thể mở rộng hơn. Bằng cách tách riêng việc xử lý khỏi cơ sở hạ tầng, ta có thể thay đổi một cách tách biệt các gói xử lý mà không làm ảnh hưởng lẫn nhau. Điều này giúp việc quản lý dễ dàng hơn và đáp ứng các thay đổi trong nhu cầu kinh doanh một cách nhanh chóng. Có một vài cách khác nhau để tách rời cơ sở hạ tầng và đường ống dẫn dữ liệu.
Một cách là sử dụng nền tảng dữ liệu dựa trên đám mây. Các nền tảng dựa trên đám mây mang lại một số lợi thế, bao gồm khả năng mở rộng, tính linh hoạt và dễ sử dụng.
Một cách khác để tách rời hạ tầng và luồng xử lý dữ liệu là sử dụng kiến trúc microservices. Microservices là các dịch vụ nhỏ, riêng biệt có thể được phát triển và triển khai độc lập. Điều này giúp dễ dàng thay đổi các dịch vụ riêng lẻ mà không ảnh hưởng đến phần còn lại của hệ thống. Các thành phần này được triển khai trên nền tảng hỗ trợ container như Docker, Kubernetes.
Thiết kế hệ thống có thể thay đổi một cách dễ dàng bằng cách sử dụng file cấu hình để điều hướng luồng xử lý, xây dựng các abstract function để có thể dễ dàng thừa kế và mở rộng.
Tự động hoá: Có nhiều cách để tự động hóa và tránh các tác vụ thủ công khi thiết kế nền tảng dữ liệu. Dưới đây là một số phương pháp phổ biến nhất:
Sử dụng các công cụ và nền tảng tự động hóa: Hiện có nhiều công cụ và nền tảng tự động hóa khác nhau, chẳng hạn như Informatica PowerCenter, IBM InfoSphere DataStage và Microsoft SQL Server Integration Services (SSIS). Những công cụ này có thể được sử dụng để tự động hóa nhiều tác vụ liên quan đến dữ liệu, chẳng hạn như trích xuất, chuyển đổi và tải dữ liệu.
Sử dụng các dịch vụ dựa trên đám mây: Các dịch vụ dựa trên đám mây có thể là một cách tuyệt vời để tự động hóa các tác vụ liên quan đến dữ liệu. Ví dụ: Amazon Web Services (AWS) cung cấp một số dịch vụ có thể được sử dụng để tự động hóa quá trình xử lý dữ liệu, chẳng hạn như Amazon Kinesis và Amazon Redshift.
Sử dụng các công cụ và công nghệ mã nguồn mở: Có một số công cụ và công nghệ nguồn mở có thể được sử dụng để tự động hóa các tác vụ liên quan đến dữ liệu. Ví dụ: Apache Hadoop và Apache Spark là hai công cụ nguồn mở phổ biến có thể được sử dụng để xử lý lượng lớn dữ liệu.
Tập trung vào độ tin cậy của hệ thống:
Giám sát hệ thống: Điều quan trọng là phải giám sát chặt chẽ nền tảng dữ liệu để xác định sớm bất kỳ vấn đề nào. Điều này có thể được thực hiện bằng cách sử dụng nhiều công cụ và kỹ thuật giám sát.
Sử dụng tự động hóa: Tự động hóa có thể giúp cải thiện độ tin cậy của nền tảng dữ liệu bằng cách giảm nhu cầu can thiệp thủ công. Điều này có thể bao gồm tự động hóa các tác vụ như tải dữ liệu, chuyển đổi dữ liệu và phân tích dữ liệu.
Có kế hoạch cho xử lý lỗi: Cho dù nền tảng dữ liệu được thiết kế và bảo trì tốt đến đâu thì vẫn luôn có khả năng bị lỗi. Điều quan trọng là phải có sẵn một kế hoạch để xử lý các lỗi, chẳng hạn như có một kế hoạch sao lưu để lưu trữ và khôi phục dữ liệu.
3.1.2.2. 2. Những điểm trọng tâm khi thiết kế và xây dựng#
Khi bắt đầu vào bước thiết kế và xây dựng hệ thống xử lý dữ liệu, ta cần cân nhắc và quyết định các lựa chọn. Một số lựa chọn ảnh hưởng đến toàn hệ thống ta cần xác định là:
Lựa chọn stack công nghệ: Bao gồm lựa chọn framework, nhà cung cấp giải pháp, công cụ,… Đây là một quy trình phức tạp gồm nhiều yếu tố, bao gồm nhu cầu kinh doanh, ngân sách và chuyên môn kỹ thuật của đội. Bắt đầu bằng cách xác định nhu cầu nghiệp vụ, hãy đặt câu hỏi ‘Ta đang cố gắng đạt được điều gì với nền tảng dữ liệu của mình?’. Khi biết được mục tiêu, ta có thể bắt đầu xác định các thành phần cần thiết. Sau đó, ta cần đánh giá chuyên môn kỹ thuật của đội phát triển. Một số kỹ thuật phức tạp hơn và đòi hỏi thời gian, kinh nghiệm nhiều hơn. Điều quan trọng là kỹ thuật mà ta có thể sử dụng một cách thành thạo. Cho dù tương lai có nhiều công cụ mới ra đời, thì hầu hết các công cụ hiện hữu vẫn hoàn toàn có thể đáp ứng được nhu cầu.
Xác định kiểu trích xuất dữ liệu phù hợp vào nền tảng: Nó có thể là batch, stream hay CDC tuỳ theo nhu cầu. Nó cũng bao gồm việc cần phải biết dữ liệu nguồn ở đâu? Tần suất dữ liệu được nhập vào là bao lâu? Thời gian thực hay theo lịch trình? Dữ liệu được bảo mật như thế nào? Nó có được nhập qua một kết nối an toàn không? Quá trình nhập dữ liệu có cần tuân theo quy định nào không?
Xác định cách thức xử lý dữ liệu: Loại xử lý dữ liệu được sử dụng có thể có tác động đáng kể đến tính chính xác, hiệu quả và bảo mật của dữ liệu. Có nhiều kiểu xử lý dữ liệu khác nhau, mỗi kiểu đều có ưu và nhược điểm riêng. Dựa vào nhu cầu nghiệp vụ, ta có thể xác định được công cụ phù hợp. Ví dụ: Nếu cần xử lý một lượng lớn dữ liệu, thì Apache Hadoop hoặc Apache Spark có thể là một lựa chọn tốt. Nếu bạn cần xử lý dữ liệu trong thời gian thực, thì có thể chọn Google Cloud Dataproc hoặc Amazon EMR. Và nếu cần xử lý dữ liệu với chi phí hợp lý trên Azure, thì Microsoft Azure HDInsight có thể là một lựa chọn phù hợp cho bạn.
Xác định nhu cầu lưu trữ: Trong phần lớn trường hợp, data lake là một lựa chọn tốt và đủ dùng. Tuy nhiên, ta cần cân nhắc nhiều yếu tố khi xác định cách thức lưu trữ dữ liệu: Ta cần lưu trữ loại dữ liệu nào? Ta cần lưu trữ bao nhiêu dữ liệu? Ta cần truy cập dữ liệu bao lâu một lần? Mức độ quan trọng của dữ liệu?
3.1.2.3. 3. Xây dựng chi tiết phương án thiết kế#
Sau khi các nhu cầu đã được xác định một cách rõ ràng, chúng ta sẽ cần cân nhắc cụ thể hơn cho từng thành phần trong nền tảng dữ liệu để tiến hành xây dựng. Một số chi tiết cho hệ thống ta cần xác định là:
Xác định các tiêu chí đo đạc, giám sát cho các thành phần của nền tảng: tích hợp dữ liệu, lưu trữ dữ liệu, xử lý dữ liệu.
Xác định cách thức xử lý lỗi và đảm bảo luồng xử lý lỗi sẽ đồng nhất trong nền tảng. Ví dụ: Xử lý dữ liệu bị lỗi khi tích hợp vào hệ thống.
Xác định hệ thống quản lý mã nguồn như là Git, Bitbucket, v.v…
Công cụ và môi trường dùng để phát triển và triển khai.
Xác định tiêu chuẩn dữ liệu.
Thực hiện đánh giá cẩn thận kiến trúc theo các tiêu chí sau:
Bảo mật
Linh hoạt
Khả năng mở rộng
Tính sẵn sàng
Quản lý schema: Quản lý schema là một khía cạnh quan trọng của thiết kế và triển khai data pipeline. Chúng ta sẽ cùng tìm hiểu chi tiết hơn về quản lý schema trong phần kế tiếp của bài viết.
3.1.2.4. 4. Quản lý schema#
Một trong những điểm quan trọng của việc xây dựng một nền tảng dữ liệu hiện đại, đó là việc quản lý schema được thực hiện một cách tập trung, điều này trái ngược với những nền tảng dữ liệu xây dựng trên Hadoop hay các cơ sở dữ liệu không quan hệ. Quản lý schema rất quan trọng vì nó giúp đảm bảo tính chính xác, nhất quán và toàn vẹn của dữ liệu.
Chức năng chính của quản lý schema tập trung bao gồm:
Tạo và duy trì các schema
Tài liệu mô tả, giải thích về schema
Quản lý thay đổi schema
Các cấu hình cho việc thay đổi trong schema đối với dữ liệu vào và ra
Tìm và khắc phục các sự cố lỗi do schema
Quản lý schema thích hợp có thể giúp ngăn ngừa hỏng dữ liệu, cải thiện bảo mật dữ liệu, giúp quản lý và sử dụng dữ liệu dễ dàng hơn.
Một số lợi ích của việc quản lý schema:
Tăng độ chính xác: Một schema được xác định rõ giúp đảm bảo dữ liệu được nhập và lưu trữ chính xác. Điều này quan trọng đối với bất kỳ cơ sở dữ liệu nào, nhưng nó đặc biệt cấp thiết đối với cơ sở dữ liệu lưu trữ dữ liệu nhạy cảm hoặc bí mật.
Tính nhất quán: Một schema cũng giúp đảm bảo rằng dữ liệu nhất quán trong cơ sở dữ liệu. Điều này có nghĩa là cùng một dữ liệu được lưu trữ theo cùng một cách trong tất cả các bảng và cột. Tính nhất quán rất quan trọng để đảm bảo dữ liệu chính xác và đáng tin cậy.
Tính toàn vẹn: Một schema có thể giúp bảo vệ tính toàn vẹn của dữ liệu bằng cách thực thi các ràng buộc đối với dữ liệu. Ví dụ: schema có thể được sử dụng để đảm bảo rằng một cột chỉ có thể chứa các giá trị nhất định hoặc một hàng không thể bị xóa nếu nó được tham chiếu bởi một hàng khác.
Bảo mật: Một schema cũng có thể được sử dụng để kiểm soát quyền truy cập vào dữ liệu. Ví dụ, một schema có thể được sử dụng để tạo các vai trò người dùng khác nhau với các quyền khác nhau để truy cập vào các bảng hoặc cột khác nhau.
Tài liệu: Một schema có tài liệu tốt có thể giúp các nhà phát triển và những người dùng khác hiểu cấu trúc của cơ sở dữ liệu dễ dàng hơn. Điều này có thể tiết kiệm thời gian và công sức khi khắc phục sự cố hoặc thực hiện các thay đổi đối với cơ sở dữ liệu.
Nhìn chung, quản lý schema là một phần quan trọng của quản trị cơ sở dữ liệu. Bằng cách làm theo các phương pháp quản lý schema tốt, bạn có thể giúp đảm bảo tính chính xác, nhất quán, toàn vẹn, bảo mật và khả năng sử dụng dữ liệu của mình.
Sau đây là một số công cụ phổ biến để quản lý schema:
Confluent Schema Registry: Confluent Schema Registry là một dịch vụ đăng ký schema phân tán, có thể mở rộng và có tính sẵn sàng cao. Nó được xây dựng dựa trên Apache Kafka và cung cấp API RESTful để lưu trữ, truy xuất và quản lý các schema.
AWS Glue Schema Registry: AWS Glue Schema Registry là dịch vụ đăng ký schema được quản lý toàn phần và được tích hợp với Danh mục dữ liệu AWS Glue.
Google Cloud Dataflow Schema Registry: Google Cloud Dataflow Schema Registry là một dịch vụ đăng ký schema được quản lý đầy đủ và được tích hợp với Google Cloud Dataflow.
Apache Avro Schema Registry: Apache Avro Schema Registry là một dịch vụ đăng ký schema được xây dựng dựa trên Apache Avro.
Kafdrop: Kafdrop là bảng điều khiển dựa trên web dành cho Apache Kafka. Nó cung cấp nhiều tính năng, bao gồm trình xem Schema egistry.
Trên đây là những nguyên tắc, yếu tố quan trọng cần xác định khi thiết kế và xây dựng hệ thống xử lý dữ liệu. Hi vọng các bạn đã phần nào nắm được những kiến thức trọng yếu khi xây dựng kiến trúc và lựa chọn công cụ, framework cho nền tảng dữ liệu.
3.1.3. Step 2: Xây dựng các luồng xử lý dữ liệu#
Data pipeline là giải pháp tự động hóa việc thu thập dữ liệu từ nhiều nguồn khác nhau, thực thi một chuỗi các bước xử lý, và lưu trữ hay truyền tải dữ liệu đến các quy trình kế tiếp để khai thác giá trị dữ liệu. Đối với các nền tảng dữ liệu hiện đại, việc kết hợp các kỹ thuật và công nghệ mới sẽ làm tăng năng suất đồng thời giúp nền tảng dữ liệu được linh hoạt hơn rất nhiều. Sau đây, ta sẽ đi sâu hơn các thành phần quan trọng của nền tảng dữ liệu và xem xét các cách tiếp cận mới.
3.1.3.1. 1. ETL, ELT hay ETLT?#
ETL và ELT là hai quy trình phổ biến và quan trọng trong hệ thống phân tích và xử lý dữ liệu. Trong thời gian gần đây, phương pháp kết hợp cả ETL và ELT thành ETLT ngày càng phổ biến do các kiến trúc data vault và data mesh xuất hiện. Việc lựa chọn phụ thuộc vào yêu cầu cụ thể của việc xử lý dữ liệu, mức độ phức tạp, hiệu suất, khả năng của hệ thống lưu trữ…
ETL, viết tắt của Extract, Transform, Load (Trích xuất, Biến đổi, Tải), bao gồm việc trích xuất dữ liệu từ nhiều nguồn và biến đổi trước khi tải vào kho dữ liệu.
ELT, viết tắt của Extract, Load, Transform (Trích xuất, Tải, Biến đổi), sẽ thực hiện trích xuất dữ liệu, tải ngay lập tức vào kho dữ liệu và sau đó mới biến đổi.
ETLT kết hợp các lợi ích của ETL và ELT bằng cách thực hiện các phép biến đổi đơn giản trên dữ liệu trước khi dữ liệu được tải vào kho dữ liệu, cho phép nhập dữ liệu nhanh hơn và giúp cải thiện chất lượng dữ liệu. Các biến đổi phức tạp, đa nguồn sẽ được thực hiện sau đó, khi cần dữ liệu để phân tích.
Những bài toán phù hợp với ETL:
Data Warehouse: dữ liệu cần biến đổi (clean, transform thành schema cụ thể,…) trước khi lưu trữ vào kho dữ liệu để khai thác.
Compliance & Regulations: dữ liệu cần được tổng hợp, ẩn các thông tin nhạy cảm,… trước khi lưu vào kho dữ liệu để đáp ứng các quy định về Compliance của hệ thống.
Hệ thống cần xử lý khối lượng lớn dữ liệu thô, phi cấu trúc.
Các công cụ phổ biến: Talend, Informatica PowerCenter, Microsoft SQL Server Integration Services (SSIS), Apache Nifi, Pentaho Data Integration.
Những bài toán phù hợp với ELT:
Big Data: các hệ thống lưu trữ dữ liệu hiện đại (Hadoop, Cloud-based data warehouse,…) đủ khả năng thực hiện biến đổi dữ liệu sau khi tải lên.
Real-time Processing: dữ liệu cần sẵn sàng càng nhanh càng tốt.
Data Analysis & Exploration: trong trường hợp cấu trúc dữ liệu cuối thường thay đổi, tải dữ liệu trước khi biến đổi sẽ giúp hệ thống linh hoạt hơn.
Các công cụ phổ biến: Apache Spark, Amazon Redshift, Google BigQuery, Snowflake, Microsoft Azure Data Factory.
Những bài toán phù hợp với ETLT:
Cross-Platform Analysis: dữ liệu được trích xuất, tải lên một hệ thống trung gian, nơi thực hiện việc biến đổi dữ liệu, và sau đó được tải lên hệ thống cuối cùng để phân tích.
Data Consolidation: dữ liệu từ nhiều nguồn cần được tổng hợp, biến đổi và tải lên một hệ thống khác.
Complex Transformation: quá trình biến đổi tốn nhiều tài nguyên mà hệ thống mục tiêu không đủ mạnh để thực thi biến đổi dữ liệu.
Các công cụ phổ biến: Microsoft SQL Server Integration Services, Informatica PowerCenter, Talend Data Integration, IBM InfoSphere DataStage.
3.1.3.2. 2. Functional Programming#
Functional Programming là phương pháp lập trình tập trung vào việc sử dụng pure function để tạo chương trình, từ đó giúp tăng khả năng module hóa, tăng khả năng kết hợp và tăng khả năng đọc hiểu luồng xử lý. Đối với việc tạo data pipeline, Functional Programming có những đặc điểm sau:
Tính immutable - các dữ liệu không thay đổi trong quá trình xử lí, mà sẽ thực hiện trên bản sao mới của dữ liệu. Điều này giúp tránh được các side effect không mong muốn và dễ dàng theo dõi hành vi của hệ thống.
Higher-order functions - hàm nhận một hàm khác làm tham số hoặc trả về một hàm như kết quả. Đặc điểm này giúp việc tạo pipeline biến đổi dữ liệu dễ dàng hơn, khi trong mỗi bước xử lí một hàm nhận đầu ra của bước trước làm đầu vào của mình.
Tích hợp hỗ trợ Parallel processing và concurency, giúp việc xử lý dữ liệu lớn trở nên hiệu quả hơn.
Một số công cụ phổ biến cho Functional Programming trong lĩnh vực Data Engineering có thể kể đến như Apache Spark, Flink, thư viện pandas của Python. Các công cụ này cung cấp các functional programming API và tính năng cho thao tác xử lí và chuyển đổi dữ liệu.
3.1.3.3. 3. Imperative hay Declarative#
Imperative - lập trình mệnh lệnh và Declarative - lập trình khai báo là hai phương pháp khác nhau được sử dụng trong Data Engineering tùy thuộc vào nhiệm vụ cụ thể.
Imperative programming: là phương pháp chú trọng vào cách thức thực hiện tác vụ bằng cách viết chuỗi các dòng code, command, script,… mô tả từng bước tác vụ được thực thi (ví dụ như code bằng ngôn ngữ Java, Python,…)
Declarative programming: là phương pháp chú trọng vào khai báo kết quả muốn đạt được và để trình thông dịch của ngôn ngữ quyết định cách thực hiện. SQL là ngôn ngữ khai báo phổ biến nhất trong Data Engineering.
Data engineer thường thuộc một trong hai nhóm: nhóm tập trung vào business - thường sử dụng SQL để nhanh chóng đạt mục tiêu và nhóm tập trung vào kĩ thuật - sử dụng các ngôn ngữ lập trình như Python, Java, Scala, các best practice để xây dựng hệ thống và khả năng mở rộng. Trong thực tế doanh nghiệp sẽ tùy thuộc vào yêu cầu bài toán và nhân lực để chọn hướng phát triển phù hợp. Một số query engine mạnh mẽ như Hive, Presto, Impala cũng được sử dụng để nhanh chóng phát triển hệ thống xử lí dữ liệu cùng đội ngũ mạnh về SQL.
So sánh nhanh về Imperative và Declarative trong Data Engineering:
Imperative |
Declarative |
|
|---|---|---|
Pros |
- Mức độ điều khiển, tùy chỉnh cao |
- Dễ đọc hiểu |
Cons |
- Hệ thống phức tạp |
- Khó xử lý các tác vụ có độ phức tạp nghiệp vụ cao |
3.1.3.4. 4. Một số phương pháp xử lý cho các vấn đề thường gặp#
3.1.3.4.1. Xử lý SCD#
Trong lĩnh vực Data, SCD là viết tắt của Slowly Changing Dimension. Đây là khái niệm trong quản lí dữ liệu nói về cách đối ứng với thay đổi của dữ liệu theo thời gian. SCD được chia thành 3 Type thông dụng:
SCD Type 1: Ghi đè dữ liệu cũ bằng dữ liệu mới, không lưu lại lịch sử.
SCD Type 2: Thêm record mới và đánh dấu inactive cho record cũ (hoặc sử dụng trường expireTime), lịch sử thay đổi có thể được truy vấn từ các record cũ.
SCD Type 3: Thêm một cột mới mỗi khi thay đổi để lưu lại “giá trị trước”, phương pháp này chỉ giữ lại phiên bản hiện tại và một phiên bản trước của dữ liệu.
Ngoài ra, có một số kiểu xử lý SCD theo dạng hybrid như:
SCD Type 4 (kết hợp Type 1 và Type 2): Sử dụng một bảng để lưu và theo dõi record cũ.
SCD Type 6 (kết hợp Type 1, 2 và 3): Lưu record mới khi có thay đổi, đồng thời thêm cột vào record cũ để cập nhật giá trị hiện tại cho tất cả record cũ.
SCD Type |
Mô tả |
Ưu điểm |
Nhược điểm |
Trường hợp sử dụng |
|---|---|---|---|---|
SCD Type 0 (Fixed) |
Không thay đổi dữ liệu, giữ nguyên giá trị gốc. |
Đơn giản, không cần xử lý cập nhật. |
Không lưu trữ lịch sử thay đổi. |
Khi dữ liệu cần cố định, không bao giờ thay đổi (VD: mã số thuế). |
SCD Type 1 (Overwrite) |
Ghi đè lên giá trị cũ khi có thay đổi. |
Giữ dữ liệu mới nhất, đơn giản trong triển khai. |
Mất lịch sử dữ liệu cũ. |
Khi không cần lưu lịch sử thay đổi (VD: số điện thoại liên hệ). |
SCD Type 2 (Historical Tracking) |
Tạo bản ghi mới khi có thay đổi, kèm theo cột hiệu lực (start_date, end_date, is_active). |
Giữ đầy đủ lịch sử thay đổi, hữu ích để phân tích xu hướng. |
Tăng kích thước bảng dữ liệu nhanh chóng. |
Khi cần lưu trữ lịch sử thay đổi (VD: địa chỉ khách hàng). |
SCD Type 3 (Previous Value) |
Thêm cột mới để lưu giá trị trước đó. |
Giữ một mức lịch sử đơn giản mà không tăng số dòng. |
Chỉ lưu được một lần thay đổi, không theo dõi toàn bộ lịch sử. |
Khi chỉ cần theo dõi một thay đổi gần nhất (VD: trạng thái tài khoản cũ và mới). |
SCD Type 4 (Hybrid – Historical + Current) |
Duy trì bảng chính với dữ liệu hiện tại, lưu lịch sử vào bảng riêng. |
Kết hợp ưu điểm của Type 1 và Type 2, quản lý tốt hiệu suất. |
Phức tạp trong thiết kế và bảo trì dữ liệu. |
Khi cần truy vấn nhanh dữ liệu hiện tại nhưng vẫn lưu lịch sử (VD: phân tích giao dịch tài chính). |
SCD Type 6 (Hybrid Type 1+2+3) |
Kết hợp cả Type 1, Type 2 và Type 3 (giữ lịch sử trong hàng, trong cột, và cập nhật giá trị mới nhất). |
Đầy đủ thông tin lịch sử và dễ truy vấn dữ liệu hiện tại. |
Phức tạp nhất trong triển khai và bảo trì. |
Khi cần phân tích lịch sử chi tiết nhưng vẫn cần truy vấn nhanh giá trị hiện tại (VD: hệ thống quản lý khách hàng). |
Trong hệ sinh thái dữ liệu lớn, có 4 cách tiếp cận để giải quyết SCD:
Phương pháp xử lý SCD truyền thống: Các phương pháp này có thể phức tạp, dễ gặp lỗi với các tập dữ liệu lớn và làm chậm quá trình ETL.
Phương pháp snapshot: Lưu lại các snapshot của tất cả dimension mỗi khi quá trình ETL được chạy. Phương pháp này đơn giản hơn so với SCD truyền thống. Các dimension trở thành một loạt các bản snapshot được đánh dấu theo thời gian, mỗi bản đại diện cho trạng thái của dimension tại một thời điểm cụ thể.
Nested data type: Sử dụng các loại dữ liệu phức tạp như array hay map để theo dõi lịch sử thuộc tính mà không làm thay đổi cấu trúc của bảng.
Delta Lake: Phương pháp hiệu quả và đảm bảo tính toàn vẹn dữ liệu với tất cả sự xử lý phức tạp đều được thực hiện ngầm.
3.1.3.4.2. Xử lý dữ liệu trùng lặp#
Dữ liệu trùng lặp có thể là một vấn đề nghiêm trọng đối với một số ứng dụng, đặc biệt là trong lĩnh vực tài chính. Sự trùng lặp thường xảy ra do lỗi và quá trình retry sau đó, dẫn đến nguy cơ dữ liệu bị hỏng và ảnh hưởng đến các hệ thống liên quan.
Để giải quyết vấn đề này, cần tích hợp chiến lược deduplication (xóa bỏ sự trùng lặp) vào data flow. Nhưng việc này tương đối khó khăn trong môi trường xử lý phân tán và có tốc độ xử lý cao, độ trễ của dữ liệu cũng có thể gây nên vấn đề. Một số phương pháp deduplication trong hệ thống quy mô lớn là:
Các phương pháp thông dụng như hashing (kỹ thuật băm), binary comparision (so sánh nhị phân), delta differencing (chênh lệch delta)
Binary comparison là phương pháp so sánh để đưa ra kết luận dữ liệu có khác nhau hay không, thay vì nêu chi tiết sự khác biệt cụ thể. Delta differencing là phương pháp chú trọng vào việc tìm điểm khác nhau giữa hai dữ liệu và dùng dữ liệu này (được gọi là delta) để lưu trữ, truyền tải…
Unique key: Định nghĩa unique key trên một hoặc nhiều trường để đảm bảo tính duy nhất, bao gồm cả việc tạo bảng chứa unique key và kiểm tra sự tồn tại của key đến tránh trùng lặp.
Bloom filter: Cấu trúc lưu trữ dữ liệu dựa trên xác suất giúp nhanh chóng và hiệu quả trong việc xác định một phần tử có thuộc một tập hợp hay không.
Exactly-Once Processing: Tận dụng khả năng của hệ thống đảm bảo xử lý mỗi message chỉ một lần duy nhất để tránh xử lý thừa.
3.1.3.5. 5. Best practices#
Các best practice cho quá trình xây dựng data pipeline:
Thiết kế pipeline:
Nghiên cứu xây dựng metadata-driven pipelines
Tham số hóa data pipeline code để thực hiện đưa dữ liệu vào theo từng phần nhỏ
Thiết kế tính idempotent cho data pipelines
Dọn dẹp tài nguyên sau khi thực thi
Sử dụng feature-flag để dễ dàng quản lý các thành phần trong pipeline
Giảm thiểu sự phụ thuộc giữa các thành phần trong pipeline
Fault tolerance:
Thiết kế tính đến fault tolerance
Giám sát các pipeline để phát hiện lỗi không mong muốn
Chuẩn bị đội ngũ giải quyết các lỗi xảy ra khi vận hành
Tối ưu hiệu suất:
Tránh các tác vụ thực thi quá lâu
Đảm bảo khả năng chịu lỗi để giảm thiểu data drift
Đảm bảo tính portability trên các nền tảng khác nhau
Thu thập thông tin về lưu lượng dữ liệu
Nghiên cứu sử dụng các công cụ quản lý workload trên các tenant khác nhau
Coding practices:
Thiết kế các function theo triết lý UNIX
Refactor boilerplate và khuyến khích code reuse
Giảm thiểu ràng buộc giữa các component trong pipeline
3.1.4. Step 3: Kiểm tra và chuẩn hóa dữ liệu#
3.1.4.1. 1. Giới thiệu#
Trong thời đại của dữ liệu lớn (big data) và xu hướng đưa ra quyết định dựa trên dữ liệu (data-driven decision-making), chất lượng dữ liệu (data quality) đóng vai trò trọng yếu. Data validation, một phần quan trọng của việc đảm bảo chất lượng dữ liệu, là quá trình đánh giá dữ liệu được thu thập, xử lý và phân tích dữ liệu để kiểm tra tính chính xác, đầy đủ, nhất quán. Việc đảm bảo dữ liệu đã đáp ứng tiêu chí và tuân thủ quy tắc giúp các hệ thống duy trì bộ dữ liệu chất lượng cao và đáng tin cậy cho các quá trình đưa ra quyết định. Triển khai quy trình kiểm tra chất lượng dữ liệu cũng giúp giảm chi phí liên quan đến các tình huống phát sinh do dữ liệu chất lượng kém, ước tính khoảng trên 3 nghìn tỷ USD mỗi năm chỉ riêng ở Hoa Kỳ.
3.1.4.2. 2. Ứng dụng Data Validation vào giai đoạn nào ?#
Data Validation có thể áp dụng vào nhiều giai đoạn trong data pipeline để đảm bảo chất lượng và độ chính xác trong suốt quy trình xử lý. Dưới đây là các bước quan trọng có thể áp dụng kiểm tra dữ liệu:
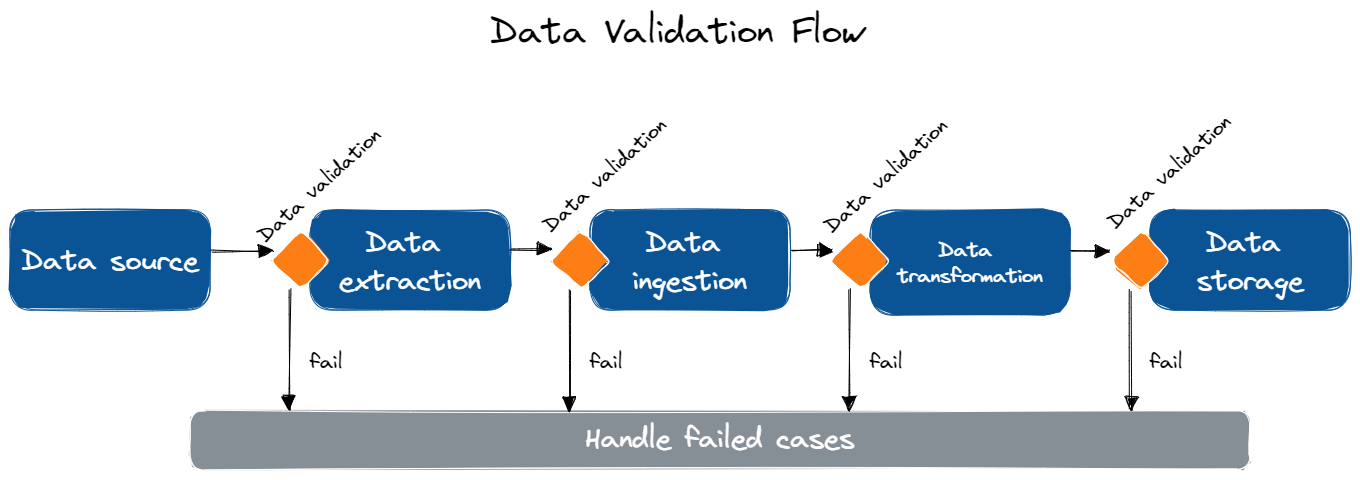
Bước |
Ứng dụng |
|---|---|
Data Extraction (Xuất dữ liệu) |
Kiểm tra dữ liệu tại nguồn dữ liệu trong quá trình xuất để đảm bảo dữ liệu hoàn chỉnh, chính xác, định dạng chuẩn. Điều này giúp phát hiện sớm các vấn đề trong data pipeline trước khi ảnh hưởng xấu đến giai đoạn tiếp theo. |
Data Ingestion (Nhập dữ liệu) |
Kiểm tra dữ liệu sau khi nhập vào hệ thống xử lý để phát hiện các vấn đề có thể xảy ra trong quá trình truyền tải, giúp đảm bảo dữ liệu đã nhập đáp ứng tiêu chuẩn chất lượng. |
Data Transformation (Chuyển đổi dữ liệu) |
Kiểm tra dữ liệu sau mỗi bước chuyển đổi để đảm bảo đã thực thi đúng và không gây lỗi hay thiếu nhất quán. Đặc biệt trong các pipeline mà dữ liệu cần làm sạch (clean), làm phong phú (enrich), xóa trùng lặp (deduplicate),… và các yếu tố khác có khả năng ảnh hưởng đến chất lượng dữ liệu. |
Data Storage (Lưu trữ dữ liệu) |
Kiểm tra dữ liệu sau khi đã lưu trữ để đảm bảo sự chính xác và tuân thủ các tiêu chuẩn đặt ra, có thể liên quan đến việc kiểm tra tính toàn vẹn dữ liệu, tính nhất quán và độ chính xác của dữ liệu trong kho lưu trữ. |
Áp dụng Data Validation trong các quá trình xử lý của data pipeline giúp xác định sớm vấn đề liên quan đến dữ liệu ở mỗi giai đoạn của quy trình, đảm bảo kết quả cuối cùng là đáng tin cậy và chính xác để sử dụng cho quá trình ra quyết định hay phân tích chuyên sâu.
3.1.4.3. 3. Những chỉ số đo lường của Data Validation#
Một số chỉ số đo lường phổ biến được sử dụng trong Data Validation để đánh giá chất lượng dữ liệu là:
Completeness (tính đầy đủ)
Tỷ lệ record có đầy đủ dữ liệu
Tỷ lệ data field có đầy đủ dữ liệu
Số lượng giá trị dữ liệu bị thiếu
Số lượng giá trị dữ liệu bị thiếu trung bình trên mỗi record
Uniqueness (tính duy nhất)
Số lượng record trùng lặp
Tỷ lệ record trùng lặp
Số lượng record duy nhất
Tỷ lệ record duy nhất
Consistency (tính nhất quán)
So sánh giá trị dữ liệu
Nhất quán về loại dữ liệu
Nhất quán về định dạng dữ liệu
Nhất quán về phạm vi dữ liệu
Timeliness (tính kịp thời)
Data age (ví dụ: thời gian tồn tại trung bình của dữ liệu trong một tập dữ liệu)
Data freshness (ví dụ: tỷ lệ dữ liệu có thời gian tạo dưới 24 giờ)
Data lag (ví dụ: độ trễ trung bình cho một tập dữ liệu)
Validity (tính hợp lệ)
Tỷ lệ giá trị dữ liệu nằm trong khoảng dự kiến
Tỷ lệ giá trị dữ liệu nhất quán với các giá trị dữ liệu khác
Tỷ lệ giá trị dữ liệu chính xác
3.1.4.4. 4. Best practices#
Data Validation Strategy (Phương pháp xác thực dữ liệu):
Xử lý “bad data” chính xác: Xác định phương pháp xử lý dữ liệu không đạt yêu cầu từ những giai đoạn đầu
Định nghĩa các bài kiểm tra hồi quy của pipeline và theo dõi kết quả metrics
Áp dụng cả unit test và integration test cho data pipeline
Kiểm tra hạ tầng độc lập với data pipeline
Tạo test case cho compliance
Test Automation and Monitoring (Kiểm thử Tự động hóa và Giám sát):
Sử dụng các công cụ automated data profiler để tạo các test case thay vì tạo từ đầu
Ví dụ như Great Expectations cung cấp tính năng automated data profiling để thống kê và tự động tạo expectation dự trên kết quả phân tích dữ liệu. Những công cụ khác cung cấp tính năng này như: Talend, IBM InfoSphere Information Analyzer, RapidMiner…
Kiểm tra dữ liệu ở mỗi giai đoạn trong pipeline và tự động hóa việc này
Tạo cơ chế tự động hóa cập nhật test database để tránh việc trở nên lỗi thời
Sử dụng các công cụ để giám sát data drift
Decoupling and Modularity (Tính tách rời và mô-đun):
Tránh ràng buộc (tighly couple) giữa code kiểm tra dữ liệu và code kiểm tra data pipeline.
Tạo phương thức cho phép kiểm tra dữ liệu trong các trường hợp cụ thể.
Cài đặt schema test trong mỗi nguồn dữ liệu trước khi thực hiện nhập dữ liệu vào pipeline.
Log kết quả failed để xác định dữ liệu “broken”, “corrupted” hay cần điều chỉnh lại test.
Infrastructure and Resource Management (Quản lý hạ tầng và tài nguyên):
Tránh thực thi các pipeline tốn nhiều tài nguyên trên dữ liệu kém chất lượng.
Tích hợp các chỉ số đo lường của bước xác thực và đảm chất lượng dữ liệu vào công cụ điều phối (orchestration).
Sử dụng chỉ số đo lường từ Data Validation trong các công cụ Data Orchestration mang đến nhiều lợi ích như giúp đưa ra quyết định chính xác, tăng chất lượng dữ liệu và sử dụng tài nguyên hiệu quả. Thêm vào đó, Data Validation còn giúp đảm bảo tính nhất quán của dữ liệu, tránh rủi ra và đảm bảo compliance.
Bài test thành công không có nghĩa tất cả đều tốt - cũng có thể hệ thống chưa cài đặt đủ bài test.
3.1.4.5. 5. Những công cụ hữu ích cho Data Validation#
Dưới đây là 5 công cụ đáng chú ý để hiện thực hóa Data Validation:
Great Expectations: Thư viện mã nguồn mở Python giúp tự động kiểm tra chất lượng dữ liệu thông qua khả năng định nghĩa và thực thi các bài test trên nhiều nguồn dữ liệu khác nhau. Các bạn có thể tìm hiểu thêm về Great Expectations tại đây.
Deequ: Thư viện mã nguồn mở được phát triển bởi Amazon để kiểm tra chất lượng dữ liệu trong các tập dữ liệu lớn bằng cách sử dụng Apache Spark, thích hợp cho các hệ thống big data.
Talend Data Quality: Nền tảng quản lí dữ liệu toàn diện cung cấp khả năng kiểm tra chất lượng dữ liệu trên nhiều nguồn và nền tảng dữ liệu khác nhau.
Informatica Data Quality: Giải pháp quản lí dữ liệu mạnh mẽ và có khả năng mở rộng, cung cấp các tính năng hiện đại về kiểm tra chất lượng dữ liệu, phù hợp với các doanh nghiệp với nhu cầu lớn về xử lý dữ liệu.
Trifacta: Công cụ hỗ trợ xử lý dữ liệu với giao diện thân thiện giúp kiểm tra và đảm bảo tính chính xác, độ tin cậy của dữ liệu trước khi phân tích.
Data Validation rất cần thiết cho mọi hệ thống xử lý dữ liệu, đây là bước đảm bảo chất lượng và độ chính xác của dữ liệu cho quá trình phân tích và đưa ra quyết định. Triển khai kiểm tra dữ liệu là điều nên làm trong các giai đoạn khác nhau của quy trình và ta cần áp dụng những chỉ số đo lường phù hợp cũng như các best practice để cải thiện hiệu suất và độ tin cậy của hệ thống xử lý dữ liệu. Bên cạnh đó, việc nắm bắt và sử dụng hiệu quả các công cụ hiện đại cũng giúp ta tối ưu hóa quá trình Data Validation.
3.1.5. Step 4: Điều phối và tự động hóa luồng dữ liệu#
3.1.5.1. 1. Mục tiêu của việc điều phối luồng dữ liệu#
Điều phối luồng dữ liệu là quá trình tự động hóa việc di chuyển và chuyển đổi dữ liệu giữa các hệ thống và ứng dụng khác nhau. Quản lý luồng dữ liệu hiệu quả là điều rất quan trọng trong việc xử lý, lưu trữ và phân tích dữ liệu một cách hiệu quả và chính xác. Các mục tiêu chính của việc quản lý luồng dữ liệu bao gồm:
Duy trì tính toàn vẹn và nhất quán của dữ liệu trong suốt quá trình xử lý dữ liệu.
Tối ưu hóa xử lý dữ liệu để giảm độ trễ và tối đa hóa khả năng tận dụng tài nguyên.
Đảm bảo độ tin cậy và khả năng mở rộng của hệ thống khi lượng dữ liệu ngày càng tăng.
Tự động hóa các tác vụ để tăng hiệu suất.
Tạo điều kiện để hợp tác và thực thi các chính sách quản trị dữ liệu.
3.1.5.2. 2. Lựa chọn công cụ#
Một số điểm cần phải cân nhắc khi lựa chọn công cụ điều phối dữ liệu:
Tích hợp với các dịch vụ cloud.
Ví dụ: AWS Step Functions, Google Cloud Composer (dựa trên Airflow) và Azure Data Factory là những công cụ điều phối dữ liệu được cung cấp bởi các cloud provider hàng đầu, giúp bạn dễ dàng tích hợp với các dịch vụ khác trong cùng hệ sinh thái.
Hỗ trợ tích hợp đa dạng, đặc biệt là container.
Ví dụ: Airflow 2.0 cung cấp Kubernetes Operator, cho phép bạn điều phối các tác vụ trên Kubernetes.
Lưu trữ tất cả các parameter, output và metadata của từng tác vụ.
Ví dụ: Kubeflow Pipelines lưu trữ thông tin chi tiết về các parameters, outputs và metadata của từng tác vụ trong quá trình xử lý, giúp người dùng theo dõi và kiểm soát dễ dàng hơn.
Có khả năng tiếp tục công việc từ nơi bị lỗi.
Ví dụ: Argo AI cung cấp khả năng tiếp tục công việc từ nơi bị lỗi, giúp tiết kiệm thời gian và nguồn lực khi xử lý các luồng dữ liệu lớn và phức tạp.
Có thể đảm bảo các SLA (Service Level Agreement) hay không.
Ví dụ: Airflow cung cấp khả năng định nghĩa SLA cho từng tác vụ và gửi cảnh báo khi không đạt được các chỉ số này.
Có hình ảnh trực quan của operations graph.
Ví dụ: Tecton cung cấp giao diện người dùng trực quan, giúp người dùng dễ dàng theo dõi quá trình xử lý dữ liệu và nhận biết các vấn đề tiềm ẩn.
Hỗ trợ gửi email hoặc tích hợp với các hệ thống khác như Slack để thông báo các lỗi xảy ra trong quá trình thử nghiệm.
Ví dụ: Prefect hỗ trợ các gửi thông báo qua Slack hoặc email khi có sự kiện nhất định, giúp quản trị viên nắm bắt tình hình dễ dàng hơn.
Khả năng trao đổi dữ liệu giữa các tác vụ.
Ví dụ: Dagster cho phép truyền dữ liệu giữa các tác vụ thông qua input và output được định nghĩa rõ ràng.
Có APIs doc tốt.
Ví dụ: Flyte cung cấp API rõ ràng và tài liệu chi tiết, giúp người dùng dễ dàng tạo và quản lý các tác vụ tự động.
Có bộ lập lịch đảm bảo tính sẵn sàng cao.
Ví dụ: AWS Step Functions cung cấp bộ lập lịch đáng tin cậy với khả năng chịu lỗi cao, đảm bảo quá trình xử lý dữ liệu không bị gián đoạn.
Khả năng mở rộng.
Ví dụ: Astronomer, một nền tảng dựa trên Airflow, cung cấp khả năng mở rộng đáng kể, giúp bạn xử lý các luồng dữ liệu lớn và phức tạp một cách dễ dàng hơn.
Khi đã xem xét và đánh giá các công cụ dựa trên các tiêu chí và yếu tố trên, bạn sẽ có thể lựa chọn công cụ điều phối dữ liệu phù hợp nhất cho nhu cầu của tổ chức. Hãy luôn cập nhật các xu hướng công nghệ mới và áp dụng các best practice trong quá trình điều phối dữ liệu để đạt hiệu quả cao nhất.
3.1.5.3. 3. Xây dựng hệ thống tự động hoá#
Để có thể mở rộng hệ thống, việc tự động hóa các quy trình phát triển và triển khai là điều bắt buộc. Một hệ thống tự động hóa có thể được xem là một nền tảng trọng yếu để mở rộng hoạt động dữ liệu. Dưới đây là một số thành phần chính khi xây dựng hệ thống tự động hóa:
Tự động hóa nhập và xử lý dữ liệu: Để một luồng dữ liệu có thể mở rộng, việc nhập, xử lý và lưu trữ dữ liệu cần được tự động hóa. Điều này bao gồm các tác vụ như trích xuất tự động dữ liệu từ nhiều nguồn, chuyển đổi thành định dạng phù hợp cho phân tích và lưu trữ vào database hoặc data warehouse. Các công cụ như Apache NiFi, StreamSets và Talend có thể được sử dụng để tự động hóa những tác vụ này.
Tự động hóa kiểm thử: Chất lượng dữ liệu là thiết yếu cho bất kỳ hệ thống dữ liệu nào. Các bài kiểm tra tự động có thể giúp đảm bảo dữ liệu chính xác, đầy đủ và đáng tin cậy. Các công cụ như Deequ hoặc Great Expectations có thể được sử dụng để thực hiện các kiểm tra xác thực dữ liệu và tiêu chí chất lượng, các công cụ này có thể chạy tự động như một phần của luồng dữ liệu.
Tự động hóa cung cấp hạ tầng: Khi hệ thống dữ liệu phát triển, nhu cầu về hạ tầng cũng tăng lên. Các công cụ tự động hóa như Terraform, Ansible hoặc Chef có thể giúp quản lý việc cung cấp và cấu hình hạ tầng, cho phép việc thiết lập và quản lý hạ tầng được tự động hóa và lặp lại, giảm thiểu lỗi do thao tác thủ công và nâng cao hiệu quả.
Tự động hóa triển khai: Việc triển khai các thay đổi và cập nhật đối với hệ thống dữ liệu nên được tự động hóa để đảm bảo sự nhất quán và giảm thiểu lỗi. Các công cụ như Jenkins, Travis CI, hoặc GitHub Actions giúp tự động hóa quy trình này, bao gồm cả việc kiểm tra, xây dựng, và triển khai các thay đổi. Điều này giúp cải thiện tốc độ triển khai và đồng thời giảm thiểu nguy cơ xảy ra lỗi.
Tự động hóa thực thi: Để đảm bảo hoạt động liên tục của các luồng dữ liệu, việc lên lịch và thực thi các tác vụ cần được tự động hóa. Công cụ như Apache Airflow, Luigi hoặc Prefect có thể giúp tự động hóa việc này, cho phép bạn thiết lập các quy tắc phức tạp cho việc thực thi luồng dữ liệu dựa trên thời gian, sự kiện hoặc tình trạng của các tác vụ khác.
3.1.5.4. 4. Best practice#
Một số best practice trong việc điều phối dữ liệu:
Việc cấu hình và thực thi luồng dữ liệu nên dễ dùng, linh hoạt và tập trung.
Các DAG workflow nên khởi tạo runtime parameters một lần ngay từ khi bắt đầu workflow và sau đó đưa vào các tác vụ.
Do chi phí lưu trữ không đắt đỏ, bạn nên thiết lập checkpoint và lưu trữ các phép tính dữ liệu trung gian trong quá trình trích xuất, tiền xử lý và training. Việc này giúp bạn có thể khôi phục lại quá trình xử lý dữ liệu nếu có lỗi xảy ra mà không cần phải bắt đầu lại từ đầu.
Tách biệt việc điều phối luồng dữ liệu khỏi business logic. Ví dụ, bạn có thể sử dụng Apache Airflow để điều phối dữ liệu, trong khi việc xử lý business logic có thể được thực hiện bởi một công cụ khác chuyên xử lý như Databricks, Spark.
Thiết kế ứng dụng sao cho cấu trúc của các DAG độc lập với cấu trúc của business logic. Điều này giúp tăng cường tính linh hoạt và giảm rủi ro xảy ra lỗi.
Cố gắng tổng quát hoá phương án xử lý file, tránh sử dụng tên file cụ thể trong luồng xử lý dữ liệu phức tạp. Thay vào đó, hãy sử dụng các hệ thống quản lý dữ liệu tự động như Hadoop HDFS hoặc Amazon S3. Ví dụ, bạn có thể sử dụng Amazon S3 để lưu trữ và quản lý dữ liệu của mình, đồng thời sử dụng các API của nó để truy xuất và xử lý dữ liệu mà không cần phải lo lắng về việc theo dõi tên file.
Một số best practice cho việc tự động hóa:
Lựa chọn cẩn thận nơi để tự động hóa. Không phải mọi quy trình công việc đều cần được tự động hóa. Đôi khi, một chút can thiệp thủ công có thể giúp giải quyết vấn đề một cách linh hoạt hơn. Tuy nhiên, có những quy trình quan trọng và tốn thời gian như việc xử lý dữ liệu, chuẩn bị dữ liệu cho việc phân tích, hay quy trình ETL nên được ưu tiên tự động hóa.
Khi bắt đầu tự động hóa luồng dữ liệu hãy bắt đầu với các luồng đơn giản, tích luỹ kinh nghiệm và sau đó thêm độ phức tạp. Ví dụ, bạn có thể bắt đầu với việc tự động hóa quá trình chuyển dữ liệu từ nguồn dữ liệu sang cơ sở dữ liệu. Sau khi đã làm chủ quy trình này, bạn có thể bắt đầu thêm các bước phức tạp hơn như chuyển đổi dữ liệu, làm sạch dữ liệu, hoặc thậm chí là phân tích dữ liệu.
Thực hiện anomaly detection trên dữ liệu: Điều này không chỉ giúp bạn nhanh chóng phát hiện và xử lý các vấn đề có thể ảnh hưởng đến chất lượng dữ liệu, mà còn giúp bạn hiểu rõ hơn về dữ liệu của mình. Một công cụ hữu ích cho việc này là ElasticSearch kết hợp với Kibana, cho phép bạn theo dõi dữ liệu theo thời gian thực và phát hiện bất thường một cách tự động.
Đưa những kiến trúc tiêu chuẩn và các công cụ tự động hóa, áp dụng và điều chỉnh các template và pattern có sẵn trong các công cụ để phù hợp nhất với yêu cầu của doanh nghiệp.
Lập lịch tự động và giám sát luồng dữ liệu theo thời gian thực bằng cách sử dụng các công cụ như Apache Airflow, giúp tiết kiệm thời gian và nâng cao năng suất. Ngoài ra, công cụ này còn cho phép bạn xây dựng các luồng dữ liệu phức tạp, với các công việc phụ thuộc vào nhau.
Tự động hóa bảo vệ dữ liệu sao cho dữ liệu nhạy cảm được kết nối với các chính sách bảo vệ dữ liệu và áp dụng các chính sách đó cho việc che dấu và làm mờ dữ liệu. Một ví dụ về việc này có thể là việc sử dụng công cụ như DataRobot, giúp tự động hóa việc tìm và che giấu dữ liệu nhạy cảm.
Tự động hóa thu thập metadata về các nguồn dữ liệu của luồng dữ liệu, quá trình định hình dữ liệu. Sử dụng công cụ như Apache Atlas, bạn có thể tự động thu thập và quản lý thông tin, giúp bạn dễ dàng kiểm soát và quản lý dữ liệu của mình.
Việc điều phối và tự động hoá luồng dữ liệu là một yếu tố quan trọng trong quá trình xây dựng và vận hành các hệ thống dữ liệu. Để đạt được hiệu quả tối ưu, các nhà phát triển và kỹ sư dữ liệu cần lựa chọn công cụ phù hợp, áp dụng các nguyên tắc và thực hành tốt nhất trong việc điều phối và tự động hoá quy trình xử lý dữ liệu.